深度学习图像分割方法U-Net改进之Attention U-Net-程序员宅基地
目录
1、Introduce
注意力机制是一种基于权重的模型,其作用是让深度学习模型能够更加集中地关注当前输入数据中最具有代表性和区分性的部分,从而提高模型的分类精度和泛化性能。
注意力机制在深度学习中广泛应用于自然语言处理、计算机视觉等领域。例如,在自然语言处理任务中,如机器翻译或文本摘要任务中,注意力机制可以帮助模型专注于输入序列中与预测结果最相关的内容,从而提高模型的翻译或摘要质量。再比如,在图像问答(QA)任务中,注意力机制可以对原始图像像素进行加权,以聚焦于图像中最相关的区域,从而对图片问题作出正确回答。
总的来说,注意力机制能够显著提高深度学习模型的表现,并在许多自然语言处理和计算机视觉领域的任务中取得了不错的效果。
2 、Attention U-Net
2.1 structure
Attention U-Net是基于U-Net模型结构的变体,其增加了注意力机制来提高模型在图像分割任务中的性能。与传统的U-Net模型相比,注意力U-Net包括了编码器、解码器和跳跃连接等常见的模块,但在解码器部分引入了注意力机制。

U-Net结构
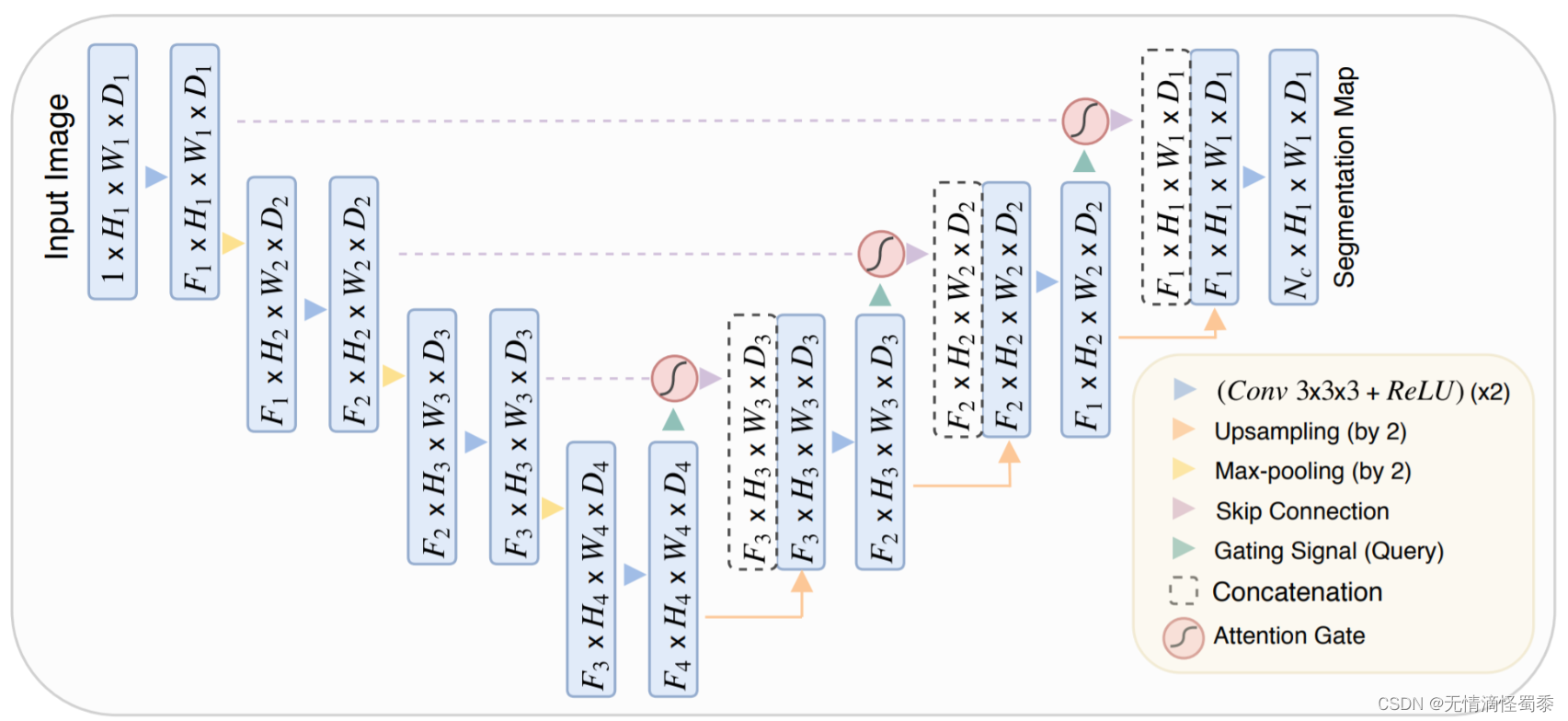
Attention U-Net结构
2.2 Attention module
具体来说,注意力U-Net在每个解码器层中都添加了一个注意力子模块,以帮助模型更准确地学习如何区分前景和背景。该子模块利用了一个注意力门控网络,它可以自动地对前景和背景进行建模,并计算不同位置处的像素应该被赋予的权重,从而使模型可以更加聚焦与所关注的区域,提高分割质量。具体地,注意力U-Net中的注意力子模块由三个组成部分组成:查询嵌入(即解码器的特征向量),键嵌入(即编码器的特征向量)和值嵌入(即加权后编码器特征向量)。其中,查询嵌入和键嵌入都采用卷积神经网络从当前解码器层和编码器各自的最大池化层输出计算得到;然后对键嵌入和查询嵌入进行相关运算,得到对应的权重矩阵;再将设置得之权重矩阵与值嵌入相乘得到加权编码器特征向量。
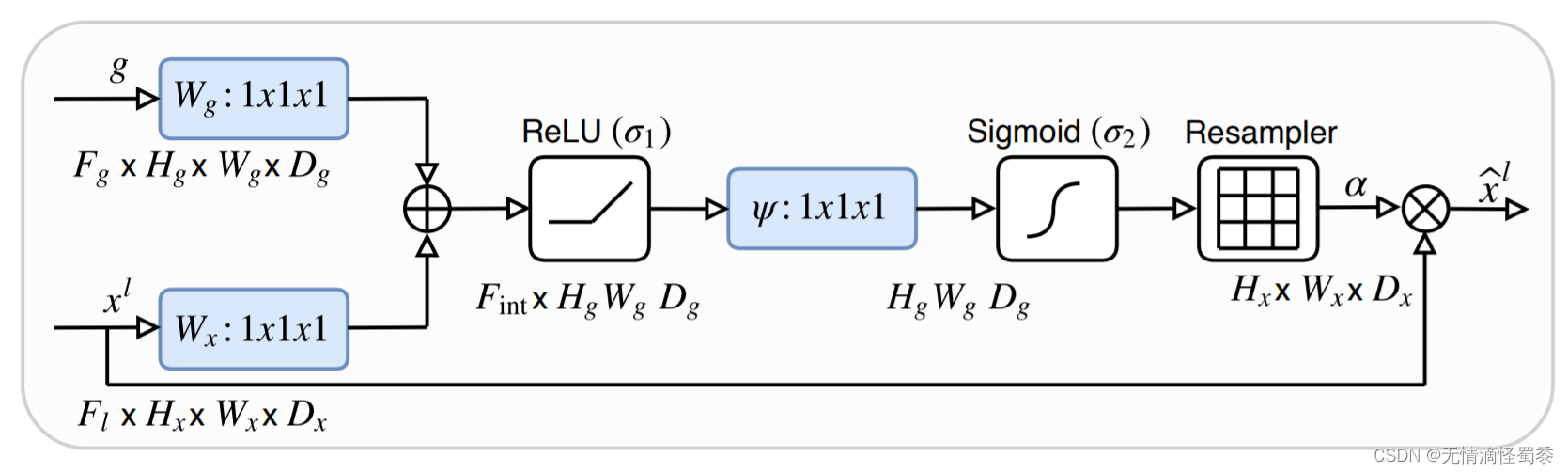
Attention 结构
Attention 结构图中尤其要注意的是X为解码器的倒数第二层,g为完成上采样的解码器倒数第一层。只有完成上采样后的层才能与X完成后续的加权操作。为了便于理解直接上代码:
在注意力子模块输出后,其与解码器层的输出进行加和。最后通过卷积操作得到最终分割结果。实验证明,引入该注意力子模块可以显著提高模型在图像分割任务中的性能。
def attention_gate(X, g, channel,
activation='ReLU',
attention='add', name='att'):
'''
Self-attention gate modified from Oktay et al. 2018.
attention_gate(X, g, channel, activation='ReLU', attention='add', name='att')
Input
----------
X: input tensor, i.e., key and value.
g: gated tensor, i.e., query.
channel: number of intermediate channel.
Oktay et al. (2018) did not specify (denoted as F_int).
intermediate channel is expected to be smaller than the input channel.
activation: a nonlinear attnetion activation.
The `sigma_1` in Oktay et al. 2018. Default is 'ReLU'.
attention: 'add' for additive attention; 'multiply' for multiplicative attention.
Oktay et al. 2018 applied additive attention.
name: prefix of the created keras layers.
Output
----------
X_att: output tensor.
1. 将输入张量 X 通过一个卷积层映射到中间层 theta_att。
2. 将门控张量 g 通过一个卷积层映射到中间层 phi_g。
3. 使用指定的注意力机制(additive 或 multiplicative)根据 theta_att 和 phi_g 计算 Q,即 query。
4. 对 Q 进行指定的非线性激活函数处理(如 ReLU),得到 f。
5. 将 f 经过卷积层转换到输出通道数为 1 的 tensor psi_f。
6. 对 psi_f 输出进行 sigmoid 激活操作,得到注意力系数 coef_att。
7. 对输入张量 X 乘以 coef_att 得到加权后的张量 X_att。返回 X_att。
'''
activation_func = eval(activation)
attention_func = eval(attention)
# mapping the input tensor to the intermediate channel
# x输入完成卷积操作
theta_att = Conv2D(channel, 1, use_bias=True, name='{}_theta_x'.format(name))(X)
# mapping the gate tensor
# g输入完成卷积操作
phi_g = Conv2D(channel, 1, use_bias=True, name='{}_phi_g'.format(name))(g)
# ----- attention learning ----- #
# 将[conv—x,conx-g] -> add
query = attention_func([theta_att, phi_g], name='{}_add'.format(name))
# nonlinear activation
# 对 Q 进行指定的非线性激活函数处理(如 ReLU),得到 f。
f = activation_func(name='{}_activation'.format(name))(query)
# linear transformation
# 将 f 经过卷积层转换到输出通道数为 1 的 tensor psi_f。
psi_f = Conv2D(1, 1, use_bias=True, name='{}_psi_f'.format(name))(f)
# ------------------------------ #
# sigmoid activation as attention coefficients
# 对psi_f输出进行sigmoid激活操作,得到注意力系数coef_att。
coef_att = Activation('sigmoid', name='{}_sigmoid'.format(name))(psi_f)
# multiplicative attention masking
# 对输入张量 X 乘以 coef_att 得到加权后的张量 X_att。返回 X_att。
X_att = multiply([X, coef_att], name='{}_masking'.format(name))
return X_att3、Reference
【语义分割系列:七】Attention Unet 论文阅读翻译笔记 医学图像 python实现_attention unet论文_鹿鹿最可爱的博客-程序员宅基地
智能推荐
AD20设计规则检查设置(DRC检查设置)_ad的drc检查规则设置-程序员宅基地
文章浏览阅读1k次。AD中PCB检查设计错误规则设置_ad的drc检查规则设置
虚拟内存和物理内存_虚拟内存和物理内存的效率-程序员宅基地
文章浏览阅读4.6k次,点赞17次,收藏69次。一、从程序到进程:我们都知道Linux下一个C程序的生成分为4个阶段:预编译(.i) --> 编译(.s) --> 汇编成目标文件(.o) --> 链接(可执行文件)1.在预编译阶段,它会修改原始的C程序,将源程序翻译成一个ASCII码的以.i结尾的中间文件。它会读取系统头文件stdio.h的内容,并把它直接插入到程序文本中。2.在编译阶段,编译器将以.i为扩展名的文本文件翻译成以.s作为扩展名的文本文件,它包含一个汇编语言程序。3.在汇编阶段,汇编器将以.s为扩展名的文本文件_虚拟内存和物理内存的效率
matlab 积分内联函数,如何在MATLAB中创建分段内联函数?-程序员宅基地
文章浏览阅读328次。你确实定义了一个带有三个断点的分段函数,即[0,0.5,1].但是,您尚未在中断之外定义函数的值. (顺便说一下,我在这里使用了“break”这个术语,因为我们确实定义了一个简单形式的样条,一个分段常数样条.我也可能使用了术语knot,这是splines世界中的另一个常用词. )如果你绝对知道你永远不会评估[0,1]之外的函数,那么就没有问题了.因此,只需在x = 0.5时定义一个断点的分段函数...._matlab内lian函数写分段函数
Linux命令-系统管理_ubuntu中怎么进入系统管理设置见面-程序员宅基地
文章浏览阅读8.8k次。文章目录1,查看当前日历:cal2,显示或设置时间:date3,查看进程信息:ps4,动态显示进程【了解】:top5,终止进程:kill6,关机重启:reboot、shutdown、init7,检测磁盘空间:df8,检测目录所占磁盘空间:du9,查看或配置网卡信息:ifconfig10,测试远程主机连通性:ping11,防火墙管理一、service方式二、iptables方式1,查看当前日历:c..._ubuntu中怎么进入系统管理设置见面
最全的WiFi速率对应表(802.11b、802.11g、802.11a、802.11n、802.11ac、802.11ax)及速率计算方法_wifi速率表-程序员宅基地
文章浏览阅读4.3w次,点赞52次,收藏291次。Wi-Fi理论带宽计算方式计算公式Wi-Fi理论带宽 =(符号位长×码率×子载波数量×空间流)÷ 传输时间符号位长一个Symbol能承载的bit数量,这个与调试有关。 11a/g 11n 11ac 11ax 最大调制方式 64QAM 64QAM 256QAM 1024QAM bit数/Symbol 6 6 8 10 码率Wi-Fi在传输时,根据空口环境的好坏,会加入不同数量的纠错码,用来提高传输的可靠性,空_wifi速率表
基于单片机三路地磁场分量信号采集系统仿真_地磁 单片机-程序员宅基地
文章浏览阅读931次,点赞29次,收藏29次。*单片机设计介绍,基于单片机三路地磁场分量信号采集系统仿真。_地磁 单片机
随便推点
商业级4G代理搭建指南【搭建篇之Docker版】_移动4gip池搭建-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏6次。时间过得真快,距离这个系列的上一篇文章《商业级4G代理搭建指南【准备篇】》发布的时间已经过了两个星期了,上个星期由于各种琐事缠身,周二开始就没空写文章了,所以就咕咕咕了。那么在准备篇中,我们了解了一下搭建 4G 代理所需要的软硬件,也知道了各种选择的优劣势。现在,我们就可以开始实际搭建了,相信大家也是期待已久了。基本思路从这篇文章的标题中我们可以看出,这一次的搭建方案主要用到的是 Dock..._移动4gip池搭建
使用Java将PPT、PDF和html转换图片并上传OSS_java ppt转图片-程序员宅基地
文章浏览阅读1.2k次。最近小雨遇到了一个需求,需要在前端小程序中嵌入展示Office文件的功能。然而,前端使用开源组件进行在线预览会导致性能消耗较大的问题(转半天圈圈)。产品理想的效果是用户上传Office文件后,浏览起来与页面一样流畅。没错,作为服务端的老铁,可以提供更强大的计算资源和处理能力来支持前端小伙伴实现需求(We are a team)!这种情况下,可以在服务端使用开源插件对文件进行预览切片,将文件的预览效果保持为一张一张的图片,用户预览时直接夹在图片即可。_java ppt转图片
兴奋了:springboot 放弃maven,选择了gradle,gradle构建springboot_springboot 用gradle还是maven-程序员宅基地
文章浏览阅读2.7k次。前言很多人好奇maven用的好好的为什么切换到gradle?Spring Boot 团队给出的主要原因是,迁移至 Gradle 可以减少构建项目所花费的时间。而 Gradle 的宗旨是减少构建工作量,它可以根据需要构建任何有变化的地方或者并行构建。当然,Spring Boot 团队也花了很多时间来尝试用 Maven 进行 并行构建,但因为构建 Spring Boot 项目的复杂性,最终失败了。另外,Spring Boot 团队也看到了在其他 Spring 项目中使用 Gradle 以及并行构建所带来_springboot 用gradle还是maven
echarts的横向柱状图文字省略,鼠标移入显示内容 vue3_echarts 鼠标移动显示数据-程序员宅基地
文章浏览阅读1.6k次。效果图如果是在x轴上的,就在x轴上添加triggerEvent: true,如果是y轴就在y轴添加,我是在y轴上添加的并且自定义的方法(我取名为extension)然后我放在末尾引入的数据格式_echarts 鼠标移动显示数据
Java的wait和notify学习三部曲之二:修改JVM源码看参数-程序员宅基地
文章浏览阅读848次,点赞17次,收藏7次。其它面试题(springboot、mybatis、并发、java中高级面试总结等)[外链图片转存中…(img-0mo0gwUi-1710971453680)][外链图片转存中…(img-05XajDND-1710971453680)]本文已被CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】收录。
MongoDB搭建环境_mongo dbowner-程序员宅基地
文章浏览阅读238次。MongoDB搭建环境安装windows安装下载安装 下载地址创建数据目录MongoDB将数据目录存储在 db 目录下。但是这个数据目录不会主动创建,我 们在安装完成后需要创建它。请注意,数据目录应该放在根目录下( (如: C:\ 或者 D: \ 等 )。 c:\data\db启动服务器 C:\mongodb\bin\mongod --dbpat..._mongo dbowner