Hadoop 自定义序列化编程_1.package tem_com; 2.import java.io.ioexception; 3-程序员宅基地
package com.cakin.hadoop.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class UserWritable implements WritableComparable<UserWritable> {
private Integer id;
private Integer income;
private Integer expenses;
private Integer sum;
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(id);
out.writeInt(income);
out.writeInt(expenses);
out.writeInt(sum);
}
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.id=in.readInt();
this.income=in.readInt();
this.expenses=in.readInt();
this.sum=in.readInt();
}
public Integer getId() {
return id;
}
public UserWritable setId(Integer id) {
this.id = id;
return this;
}
public Integer getIncome() {
return income;
}
public UserWritable setIncome(Integer income) {
this.income = income;
return this;
}
public Integer getExpenses() {
return expenses;
}
public UserWritable setExpenses(Integer expenses) {
this.expenses = expenses;
return this;
}
public Integer getSum() {
return sum;
}
public UserWritable setSum(Integer sum) {
this.sum = sum;
return this;
}
public int compareTo(UserWritable o) {
// TODO Auto-generated method stub
return this.id>o.getId()?1:-1;
}
@Override
public String toString() {
return id + "\t"+income+"\t"+expenses+"\t"+sum;
}
}package com.cakin.hadoop.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
/*
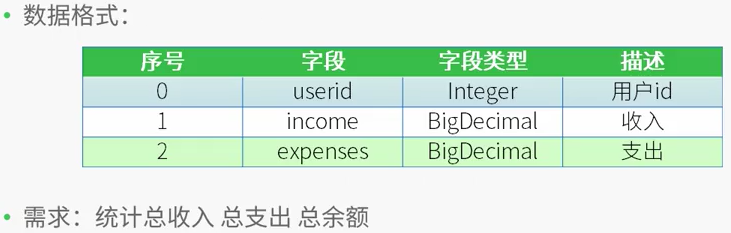
* 测试数据
* 用户id 收入 支出
* 1 1000 0
* 2 500 300
* 1 2000 1000
* 2 500 200
*
* 需求:
* 用户id 总收入 总支出 总的余额
* 1 3000 1000 2000
* 2 1000 500 500
* */
public class CountMapReduce {
public static class CountMapper extends Mapper<LongWritable,Text,IntWritable,UserWritable>
{
private UserWritable userWritable =new UserWritable();
private IntWritable id =new IntWritable();
@Override
protected void map(LongWritable key,Text value,
Mapper<LongWritable,Text,IntWritable,UserWritable>.Context context) throws IOException, InterruptedException{
String line = value.toString();
String[] words = line.split("\t");
if(words.length ==3)
{
userWritable.setId(Integer.parseInt(words[0]))
.setIncome(Integer.parseInt(words[1]))
.setExpenses(Integer.parseInt(words[2]))
.setSum(Integer.parseInt(words[1])-Integer.parseInt(words[2]));
id.set(Integer.parseInt(words[0]));
}
context.write(id, userWritable);
}
}
public static class CountReducer extends Reducer<IntWritable,UserWritable,UserWritable,NullWritable>
{
/*
* 输入数据
* <1,{[1,1000,0,1000],[1,2000,1000,1000]}>
* <2,[2,500,300,200],[2,500,200,300]>
*
* */
private UserWritable userWritable = new UserWritable();
private NullWritable n = NullWritable.get();
protected void reduce(IntWritable key,Iterable<UserWritable> values,
Reducer<IntWritable,UserWritable,UserWritable,NullWritable>.Context context) throws IOException, InterruptedException{
Integer income=0;
Integer expenses = 0;
Integer sum =0;
for(UserWritable u:values)
{
income += u.getIncome();
expenses+=u.getExpenses();
}
sum = income - expenses;
userWritable.setId(key.get())
.setIncome(income)
.setExpenses(expenses)
.setSum(sum);
context.write(userWritable, n);
}
}
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
/*
* 集群中节点都有配置文件
conf.set("mapreduce.framework.name.", "yarn");
conf.set("yarn.resourcemanager.hostname", "mini1");
*/
Job job=Job.getInstance(conf,"countMR");
//jar包在哪里,现在在客户端,传递参数
//任意运行,类加载器知道这个类的路径,就可以知道jar包所在的本地路径
job.setJarByClass(CountMapReduce.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(UserWritable.class);
//指定最终输出的数据kv类型
job.setOutputKeyClass(UserWritable.class);
job.setOutputKeyClass(NullWritable.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数及job所用的java类在的jar包,提交给yarn去运行
//提交之后,此时客户端代码就执行完毕,退出
//job.submit();
//等集群返回结果在退出
boolean res=job.waitForCompletion(true);
System.exit(res?0:1);
//类似于shell中的$?
}
}[root@centos hadoop-2.7.4]# bin/hdfs dfs -cat /input/data
1 1000 0
2 500 300
1 2000 1000
2 500 200[root@centos hadoop-2.7.4]# bin/yarn jar /root/jar/mapreduce.jar /input/data /output3
17/12/20 21:24:45 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/12/20 21:24:46 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/12/20 21:24:47 INFO input.FileInputFormat: Total input paths to process : 1
17/12/20 21:24:47 INFO mapreduce.JobSubmitter: number of splits:1
17/12/20 21:24:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513775596077_0001
17/12/20 21:24:49 INFO impl.YarnClientImpl: Submitted application application_1513775596077_0001
17/12/20 21:24:49 INFO mapreduce.Job: The url to track the job: http://centos:8088/proxy/application_1513775596077_0001/
17/12/20 21:24:49 INFO mapreduce.Job: Running job: job_1513775596077_0001
17/12/20 21:25:13 INFO mapreduce.Job: Job job_1513775596077_0001 running in uber mode : false
17/12/20 21:25:13 INFO mapreduce.Job: map 0% reduce 0%
17/12/20 21:25:38 INFO mapreduce.Job: map 100% reduce 0%
17/12/20 21:25:54 INFO mapreduce.Job: map 100% reduce 100%
17/12/20 21:25:56 INFO mapreduce.Job: Job job_1513775596077_0001 completed successfully
17/12/20 21:25:57 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=94
FILE: Number of bytes written=241391
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=135
HDFS: Number of bytes written=32
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=23672
Total time spent by all reduces in occupied slots (ms)=11815
Total time spent by all map tasks (ms)=23672
Total time spent by all reduce tasks (ms)=11815
Total vcore-milliseconds taken by all map tasks=23672
Total vcore-milliseconds taken by all reduce tasks=11815
Total megabyte-milliseconds taken by all map tasks=24240128
Total megabyte-milliseconds taken by all reduce tasks=12098560
Map-Reduce Framework
Map input records=4
Map output records=4
Map output bytes=80
Map output materialized bytes=94
Input split bytes=94
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=94
Reduce input records=4
Reduce output records=2
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=157
CPU time spent (ms)=1090
Physical memory (bytes) snapshot=275660800
Virtual memory (bytes) snapshot=4160692224
Total committed heap usage (bytes)=139264000
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=41
File Output Format Counters
Bytes Written=32[root@centos hadoop-2.7.4]# bin/hdfs dfs -cat /output3/part-r-00000
1 3000 1000 2000
2 1000 500 500智能推荐
info级别日志与debug_debug中的计算是否在info级别也会跑-程序员宅基地
文章浏览阅读6.3k次。日志默认info级别debug日志不会打印,但是会执行日志填充的数据例如:logger.debug("日志输出",2*10); 1. 2*10会先执行出结果,然后继续往下走2. 在ch.qos.logback.classic.Logger#filterAndLog_1方法中判断是否符合级别要求是否需要输出3.如图:..._debug中的计算是否在info级别也会跑
Third calibration example - Calibration using Heikkil�'s data (planar and non-planar calibration rig-程序员宅基地
文章浏览阅读1.4k次。Similarly to the previous example, let us apply our calibration engine onto the data that comes with the originalcalibration toolbox of Heikkil� from the University of Oulu. Once again. do not bothe_non-planar calibration
物联网常用的网络协议:MQTT、AMQP、HTTP、CoAP、LwM2M_lmm2m和mqtt-程序员宅基地
文章浏览阅读1w次,点赞10次,收藏63次。物联网常用的网络协议:MQTT、AMQP、HTTP、CoAP、LwM2M物联网设备间沟通的语言,就是网络协议。设备间想相互交流,通信双方必须使用同一种“语言”。比如说你和中国人问好说’你好‘、日本人问好要说‘こんにちは’、和英国人问好要说‘hello’.说起网络协议,你可能马上就想到了 HTTP 协议。是的,在日常的 Web 开发中,我们总是需要跟它打交道,因为 HTTP 协议是互联网的主流网络协议。类似地,应用在互联网中的网络协议,还有收发电子邮件的 POP3 、SMTP 和 IMAP 协议,以及_lmm2m和mqtt
fortran使用MKL函数库中的geev计算一般矩阵的特征值与特征向量_fortran求矩阵特征值-程序员宅基地
文章浏览阅读7.4k次,点赞4次,收藏20次。这篇博文简要记录一下使用MKL函数库计算一般矩阵的特征值与特征向量对形如对称矩阵或是埃尔米特等特殊矩阵有其对应的子程序,在这里先不涉及。有需求的可以自行查阅MKL官方文档下面给出本次示例代码:代码使用f95接口。f77借口参数太多,笔者太懒<不过懒惰是创新的原动力^_^>program testGeev use lapack95 implicit..._fortran求矩阵特征值
Numpy, Scipy, Matplotlib基本用法_np.imresize-程序员宅基地
文章浏览阅读147次。学习内容来自:Numpy Tutorial文章目录Array SlicingArray IndexingMathematical ManipulationBroadcastingImage Processing基本的用法课程里面说的挺详细了。 特别记录一些需要关注的点。Array Slicing使用固定数字进行array寻址会导致数组降维。y = np.random.random((3,..._np.imresize
蓝桥杯 历届试题 回文数字 C++_c++蓝桥杯 回文数-程序员宅基地
文章浏览阅读355次。题目阅览 观察数字:12321,123321 都有一个共同的特征,无论从左到右读还是从右向左读,都是相同的。这样的数字叫做:回文数字。 本题要求你找到一些5位或6位的十进制数字。满足如下要求: 该数字的各个数位之和等于输入的整数。 输入格式 一个正整数 n (10<n<100), 表示要求满足的数位和。 输出格式若干行,每行包含一个满足要求的5位或6位整数。 数字按从小到大的顺序排列。 如果没有满足条件的,输出:-1样例输入144样例输出199899_c++蓝桥杯 回文数
随便推点
Java生成二维码,扫描并跳转到指定的网站_java扫二维码进入自己制作的网页-程序员宅基地
文章浏览阅读6.2k次,点赞3次,收藏13次。需要的pom文件 <dependency> <groupId>com.google.zxing</groupId> <artifactId>core</artifactId> <version>3.1.0</version>_java扫二维码进入自己制作的网页
python:多波段遥感影像分离成单波段影像_一个多波段影像分解成多个单波段影像-程序员宅基地
文章浏览阅读650次。在遥感图像处理中,我们经常需要将多波段遥感影像拆分成多个单波段图像,以便进行各种分析和后续处理。本篇博客将介绍一个用Python编写的程序,该程序可以读取多波段遥感影像,将其拆分为单波段图像,并保存为单独的文件。本程序使用GDAL库来处理遥感影像数据,以及NumPy库来进行数组操作。结果如下图所示,选中的影像为输入的多波段影像,其他影像分别为拆分后的多波段影像。_一个多波段影像分解成多个单波段影像
移动硬盘突然在电脑上无法显示_电脑无法显示移动硬盘-程序员宅基地
文章浏览阅读5.1k次,点赞2次,收藏4次。0前言一直用的好好的移动硬盘突然不显示了,前段时间因为比较忙,一直没顾得上管它,趁这个假期,好好捅咕了一番,总算是弄好了,特此将解决的过程记录如下:1.问题描述 1.我的移动硬盘在其他人的电脑上能够正常显示和使用 2.其他移动硬盘在我电脑上能够正常的显示和使用 3.在我的电脑上,该移动硬盘,既不显示盘符,磁盘管理 又不显示该磁盘2.问题分析1.我的移动硬盘能够在其他人电脑上_电脑无法显示移动硬盘
Linux开机启动过程(16):start_kernel()->rest_init()启动成功_linux 标志着kernel启动完成-程序员宅基地
文章浏览阅读1k次。Kernel initialization. Part 10.在原文的基础上添加了5.10.13部分的源码解读。End of the linux kernel initialization processThis is tenth part of the chapter about linux kernel initialization process and in the previous part we saw the initialization of the RCU and stopped o_linux 标志着kernel启动完成
Scala安装和开发环境配置教程_scala安装及环境配置-程序员宅基地
文章浏览阅读5.3k次,点赞5次,收藏23次。Scala语言概述:Scala语言是一门以Java虚拟机为运行环境,支持面向对象和函数式编程的静态语言,java语言是面向对象的,所以代码写起来就会相对比较模块儿,而函数式编程语言相对比较简洁_scala安装及环境配置
深扒人脸识别60年技术发展史_人脸识别发展历史-程序员宅基地
文章浏览阅读2.4k次。“他来听我的演唱会,门票换了手铐一对”。最近歌神张学友变阿SIR,演唱会上频频抓到罪犯,将人脸识别技术又一次推到了大众的视线中。要说人脸识别技术的爆发,当属去年9月份苹果iPhone x的发布,不再需要指纹,只需要扫描面部就可以轻松解锁手机。任何技术一旦进入智能手机这个消费市场,尤其是被苹果这个标志性的品牌采用,就意味着它将成为一种趋势,一个智能设备的标配。在智能手机快速崛起的这几年,其密码锁..._人脸识别发展历史