Databricks文档01----Azure Databricks初探-程序员宅基地
技术标签: Azure bigdata 机器学习 datalake spark databricks Databricks 大数据
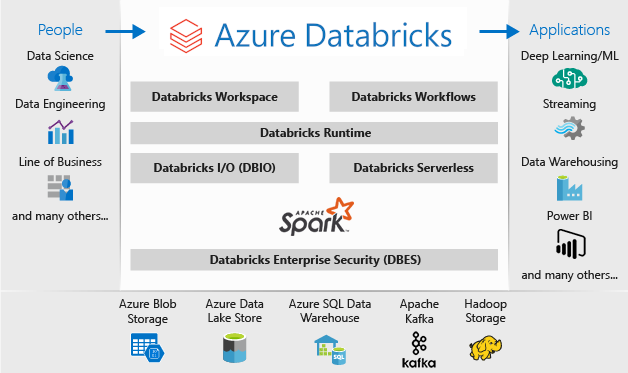
Azure Databricks 是一个已针对 Microsoft Azure 云服务平台进行优化的数据分析平台。
Azure Databricks 提供了三种用于开发数据密集型应用程序的环境:
-
Databricks 数据科学工程
-
Databricks 机器学习
-
Databricks SQL
Databricks SQL 为想要针对数据湖运行 SQL 查询、创建多种可视化类型以从不同角度探索查询结果,以及生成和共享仪表板的分析员提供了一个易于使用的平台。
Databricks 数据科学 工程 提供了一个交互式工作区,可在数据工程师、数据科学家和机器学习工程师之间实现协作。 使用大数据管道时,原始或结构化的数据将通过 Azure 数据工厂以批的形式引入 Azure,或者通过 Apache Kafka、事件中心或 IoT 中心进行准实时的流式传输。 此数据将驻留在 Data Lake(长久存储)、Azure Blob 存储或 Azure Data Lake Storage 中。 在分析工作流中,使用 Azure Databricks 从多个数据源读取数据,并使用 Spark 将数据转换为突破性见解。
Databricks 机器学习是一个集成式端到端机器学习环境,其中整合了用于试验跟踪、模型训练、特征开发和管理以及特征与模型传送的托管服务。
若要选择环境,启动一个 Azure Databricks 工作区并使用边栏中的角色切换器:

什么是Databricks Data Science & Engineering
Databricks Data Science & Engineering (有时只称为"工作区",) 是基于工作区的分析Apache Spark。 它与 Azure 集成,以提供一键式安装程序、简化的工作流程以及交互式工作区,从而使数据工程师、数据科学家和机器学习工程师之间可以进行协作。
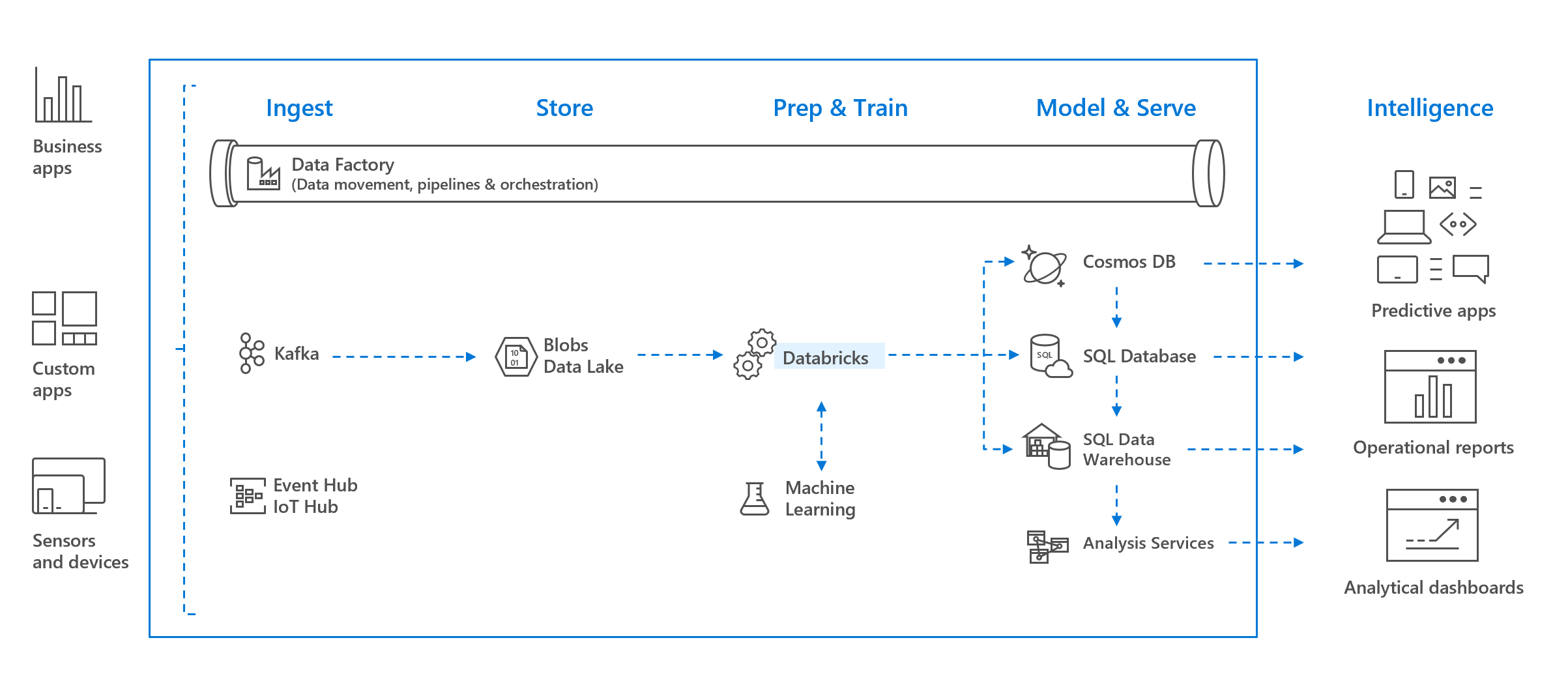
使用大数据管道时,原始或结构化的数据将通过 Azure 数据工厂以批的形式引入 Azure,或者通过 Apache Kafka、事件中心或 IoT 中心进行准实时的流式传输。 此数据将驻留在 Data Lake(长久存储)、Azure Blob 存储或 Azure Data Lake Storage 中。 在运行分析工作流的过程中,可以使用 Azure Databricks 从 Azure Blob 存储、Azure Data Lake Storage、Azure Cosmos DB 或 Azure SQL 数据仓库等多个数据源读取数据,并使用 Spark 将数据转化为前所未有的见解。
Apache Spark 分析平台
Databricks Data Science & Engineering 包含完整的开源Apache Spark群集技术和功能。 Databricks Data Science Engineering 中的 & Spark 包括以下组件:

-
Spark SQL 和数据帧:Spark SQL 是用于处理结构化数据的 Spark 模块。 数据帧是已组织成命名列的分布式数据集合。 它在概念上相当于关系型数据库中的表,或 R/Python 中的数据帧。
-
流式处理:实时数据处理和分析,适用于分析与交互式应用程序。 与 HDFS、Flume 和 Kafka 集成。
-
MLlib:由常见学习算法和实用工具(包括分类、回归、群集、协作筛选、维数约简以及底层优化基元)组成的机器学习库。
-
GraphX:图形和图形计算,适用于从认知分析到数据探索的广泛用例。
-
Spark Core API:包含对 R、SQL、Python、Scala 和 Java 的支持。
Azure Databricks 中的 Apache Spark
Azure Databricks 构建在 Spark 功能的基础之上,提供一个无管理云平台,其中包括:
-
完全托管的 Spark 群集
-
可浏览和可视化数据的交互式工作区
-
一个为你喜爱的 Spark 应用程序提供支持的平台
在云中完全托管的 Apache Spark 群集
Azure Databricks 在云中拥有安全可靠的生产环境,由 Spark 专家进行管理和提供支持。 可以:
-
在几秒钟内创建群集。
-
动态自动扩展和缩减群集并在团队中共享群集。
-
通过调用 REST API 以编程方式使用群集。
-
使用基于 Spark 的安全数据集成功能,在无需集中化的情况下统一数据。
-
即时获得每个版本中的最新 Apache Spark 功能。
Databricks Runtime
Databricks 运行时构建在 Apache Spark 的基础之上,是针对 Azure 云以原生方式构建的。
Azure Databricks 通过高度抽象化彻底消除了基础结构复杂性,无需专业知识就能设置和配置数据基础结构。
对于关注生产作业性能的数据工程师而言,Azure Databricks 通过 I/O 层和处理层 (Databricks I/O) 的各种优化提供了一个更快速、更高效的 Spark 引擎。
实现协作的工作区
Databricks Data Science & Engineering 通过协作和集成环境简化了在 Spark 中浏览数据、原型制作和运行数据驱动应用程序的过程。
-
通过简单的数据浏览确定如何使用数据。
-
在以 R、Python、Scala 或 SQL 编写的笔记本中记录进度。
-
几步内即可实现数据可视化,可使用熟悉的工具,例如 Matplotlib、ggplot 或 d3。
-
使用交互式仪表板创建动态报告。
-
在使用 Spark 的同时与数据交互。
企业安全性
Azure Databricks 提供企业级的 Azure 安全性,包括 Azure Active Directory 集成、基于角色的控制,以及可保护数据和业务的 SLA。
-
与 Azure Active Directory 集成后,可以使用 Azure Databricks 运行基于 Azure 的完整解决方案。
-
Azure Databricks 基于角色的访问可以细化用户对笔记本、群集、作业和数据的权限。
-
企业级 SLA。
与 Azure 服务集成
Databricks Data Science & Engineering 与 Azure 数据库和存储深度集成:Synapse Analytics、Cosmos DB、Data Lake Store和 Blob 存储。
与 Power BI 集成
通过与 Power BI 的丰富集成,Databricks 数据&科学工程可让你快速轻松地发现和共享具有影响力的见解。 还可以使用其他 BI 工具,例如 Tableau 软件。
什么是 Databricks 机器学习
Databricks 机器学习(预览版)是一个集成式端到端机器学习平台,其中整合了用于试验跟踪、模型训练、特征开发和管理、特征与模型传送的托管服务。 此图显示了 Databricks 的功能如何与模型开发和部署过程的各个步骤相契合。

利用 Databricks 机器学习,可以:
对于机器学习应用程序,Databricks 提供了用于机器学习的 Databricks Runtime,这是 Databricks Runtime 的一种变型,包含许多常见的机器学习库。
Databricks 机器学习特征
特征存储
借助特征存储,可对 ML 特征进行分类,并使其可用于训练和传送,从而提高重用性。 通过基于数据世系的特征搜索来利用自动记录的数据源,可使用无需对客户端应用程序进行更改的简化模型部署来提供特征用于训练和传送。
试验
通过 MLflow 试验,可直观呈现、搜索和比较运行,还可下载运行项目和元数据,便于在其他工具中进行分析。 通过试验页面可快速访问组织中的 MLflow 试验。 可通过从 Azure Databricks 笔记本和作业中记录到这些试验来跟踪机器学习模型开发。
模型
Azure Databricks 提供一种托管版本的 MLflow 模型注册表来帮助你管理 MLflow 模型的完整生命周期。 模型注册表提供按时间顺序记录的模型世系(MLflow 试验和运行在给定时间生成模型)、模型版本控制、阶段转换(例如从“暂存”到“生产”或“已存档”),以及模型事件的电子邮件通知。 你还可创建和查看模型说明,并留下注释。
自动化 ML
通过 AutoML 可根据数据自动生成机器学习模型,并更快投入生产环境。 它为模型训练准备数据集,然后执行并记录一组试验,从而创建、优化和评估多个模型。 它会显示结果,并提供一个 Python 笔记本,里面有每个试验运行的源代码,使你可查看、重现和修改代码。 AutoML 还会计算数据集的汇总统计信息,并将此信息保存在稍后可查看的笔记本中。
用于机器学习的 Databricks Runtime
用于机器学习的 Databricks Runtime (Databricks Runtime ML) 自动创建针对机器学习优化的群集。 Databricks Runtime ML 群集包括最常见的机器学习库,例如 TensorFlow、PyTorch、Keras 和 XGBoost,还包括分布式训练所需的库,如 Horovod。 使用 Databricks Runtime ML 可以加快群集创建速度,并确保已安装的库版本兼容。
什么是 Databricks SQL?
Databricks SQL 用于对数据湖运行快速临时 SQL 查询。 查询支持多种可视化类型,有助于从不同角度探索查询结果。
云中完全托管的 SQL 终结点
SQL 查询在完全托管的 SQL 终结点上运行,这些终结点的大小根据查询延迟需求和并发用户数进行了调整。 为了帮助你快速入门,每个工作区都预配置了一个小型初学者 SQL 终结点。
用于共享见解的仪表板
仪表板支持合并可视化效果和文本,用于共享通过查询获取的见解。
警报可助力监视和集成
查询返回的字段达到阈值时,你会收到警报。 使用警报来监视业务或将其与工具集成,以启动用户加入或支持工单等工作流。
企业安全性
Databricks SQL 提供企业级的 Azure 安全性,包括 Azure Active Directory 集成、基于角色的控制,以及可保护数据和业务的 SLA。
-
它与 Azure Active Directory 集成,因此你可以使用 Databricks SQL 运行基于 Azure 的完整解决方案。
-
基于角色的访问可实现针对警报、仪表板、SQL 终结点、查询和数据的精细化用户权限。
-
企业级 SLA。
与 Azure 服务集成
Databricks SQL 与以下 Azure 数据库和存储集成:Synapse Analytics、Cosmos DB、Data Lake Store 和 Blob 存储。
与 Power BI 集成
通过与 Power BI 的多样化集成,Databricks SQL 让你可以快速轻松地发现和共享有影响力的见解。 还可以使用其他 BI 工具,例如 Tableau 软件。
智能推荐
新玺配资:尚未形成趋势主线 困境下的策略曝光-程序员宅基地
文章浏览阅读66次。 回顾周二A股行情,沪深两市整体呈现震荡反弹格局。沪指和深成指表现较为强势,全天呈现脉冲式上行格局,其中深成指涨幅超过1%,上证指数距离 3600点仅一步之遥;而创业板指开盘快速冲高,随后逐步回落,全天表现相对分化。 当前在成交量持续回落、宏观经济增速趋缓、海外风险仍存的背景下,建议更多关注具备防御性质的方向,业绩稳定、前期涨幅较小、三季报预计良好的方向存在一定的机会。 从技术面来看,周二沪指震荡走高收红,个股板块涨多跌少,赚钱效应偏好,两市成交额表现温和,预计短线大盘有望逐步震荡企稳,关注板块
控制台-程序员宅基地
文章浏览阅读783次。windowsAllocConsole FreeConsole AttachConsole GetStdHandleAttachConsole(ATTACH_PARENT_PROCESS);// 将当前程序附着到父进程上,因为是从控制台启动的,所以当前程序的父进程就是那个控制台。freopen("CONIN$", "r+t", stdin); // 重定向 STDINfreopen("CONOUT$", "w+t", stdout); // 重定向STDOUTConsole FunctionsGetCons
直流充电机TK22010Z电源模块TK22020F_eds230d10zz-程序员宅基地
文章浏览阅读53次。直流充电机TK22010Z电源模块TK22020F,电源模块TK22010F,直流屏整流模块TK22020F,TK11010F,充电模块TK11020F_eds230d10zz
数据流中的中位数_输入是一个很长的数据流,如何返回它的中位数-程序员宅基地
文章浏览阅读162次。数据流中的中位数如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。样例输入:1, 2, 3, 4输出:1,1.5,2,2.5解释:每当数据流读入一个数据,就进行一次判断并输出当前的中位数。优先级队列时间复杂度O(logn)class Solution { PriorityQueue<Integer> minheap = new_输入是一个很长的数据流,如何返回它的中位数
log4js-node在VisualStudioCode内置调试控制台无输出解决_nodejs vscode stdout-程序员宅基地
文章浏览阅读6.3k次。最近学习到了nodejs的日志输出模块,选择了log4js-node这个模块,但是当我兴高采烈的在vsc中写好log输出的时候,debug的时候在调试控制台(debug console)却没有任何显示,最后经过在官方github里询问查找得到如下解决方案1: log4js的输出采用的是stdout的方式,而vsc目前的内置调试控制台还默认不从stdout的输出流中抓取内容,需要在vsc的启动配_nodejs vscode stdout
anaconda spyder闪退_spyder闪退 用户名汉字-程序员宅基地
文章浏览阅读52次。在试过很多方法后,包括但不限于新建环境变量,改变下载的版本,改变下载的网站等,都不能解决闪退的问题。于是我又改回来了,然后创建了一个新账户,并把它设置为管理员。(具体怎么操作,自己去搜一下吧。如果你的用户名是中文,请先把它改成英文,还是不行的话,再去找其他办法吧。然而改用户名后,我的文件都找不到了,桌面又回到了刚买的时候,就两图标了。在新账户重新下载了anaconda,spyder可以正常打开了。然后我发现,是因为我的用户名是中文。_spyder闪退 用户名汉字
随便推点
从SRA数据下载开始学习ATACseq数据分析_sra文件怎么打开-程序员宅基地
文章浏览阅读765次。第2行储存的是序列信息,正常情况都是用ATCG四个字母表示,但是当测序仪无法准确分辨该位置的序列信息时,会以N来代指此处的序列信息;第4行存储的就是第2行每一个碱基的测序质量信息,其中的每一个符号所对应计算机的ASCII值是经过换算的phred值,而phred值等于33-10*logP,这里的P代表该位置测序发生错误的概率,简单来说,如果某个位置测得的序列十分可信,那么意味着该位置发生错误的概率极小,所以phred值就很大,即该值越大,说明测序的质量越好。明码标价之ATACseq|生信菜鸟团。_sra文件怎么打开
C语言打印转义字符-程序员宅基地
文章浏览阅读362次,点赞5次,收藏10次。打印转义字符、\ddd,表示1~3个八进制的数字
技术点记录_hive timediff-程序员宅基地
文章浏览阅读965次。函数Hive的内置函数数学函数取整函数:round、floor、ceil、fixfix朝零方向取整,如fix(-1.3)=-1; fix(1.3)=1;floor:地板数,所以是取比它小的整数,即朝负无穷方向取整,如floor(-1.3)=-2; floor(1.3)=1; floor(-1.8)=-2; floor(1.8)=1。ceil:天花板数,也就是取比它大的最小整数,即朝正无穷方向取整,如ceil(-1.3)=-1; ceil(1.3)=2; ceil(-1.8)=-1; ceil_hive timediff
19.相机,棱镜和光场_相机视野经过棱镜后-程序员宅基地
文章浏览阅读1k次,点赞20次,收藏23次。1.Synthesis(图形学上)合成:比如之前学过的光线追踪或者光栅化2.Capture(捕捉):把真实世界存在的东西捕捉成为照片。_相机视野经过棱镜后
Docker多机集群部署之MySQL集群(PXC)_不同云服务器搭建pxc集群-程序员宅基地
文章浏览阅读1.2k次。一、环境说明:宿主机:Win10虚拟机工具:VMware Workstation 15系统及版本:Ubuntu16.04Docker版本:18.09.3涉及到的虚拟主机:192.168.1.100 haproxy192.168.1.101 node1192.168.1.102 node2192.168.1.103 node3二、准备镜像#拉取percona/percona-xtradb-cluster:5.6#pxc5.7版本不支持不使用k8s或者et.._不同云服务器搭建pxc集群
AT命令_at命令默认采用的是text模式吗?-程序员宅基地
文章浏览阅读2.3k次,点赞2次,收藏10次。AT命令最常见的应用场景:1、智能手机:一般智能手机都是一个主芯片控制一个通信模块,这个通信模块就是一个完整的、简单的手机,包括手机应该有的射频、基带等部分,还有GSM协议栈,完全可以独立打电话、发短信、用GPRS上网等。主芯片实现复杂的应用软件。主芯片和通信模块之间通过AT命令,也就是做主芯片通过AT命令控制通信模块打电话,发短信等。2、其他通信模块。例如出租车上的车载台,通信模块可以接收控..._at命令默认采用的是text模式吗?