DataFrame基础知识-程序员宅基地
技术标签: 云原生 Linux spark linux hadoop 大数据
目录
一.DataFrame 简介
Spark SQL使用的数据首先并非RDD,而是DataFrame
DataFrame是一种以RDD为基础的分布式数据集,DataFrame可以完成RDD的绝大多数功能。
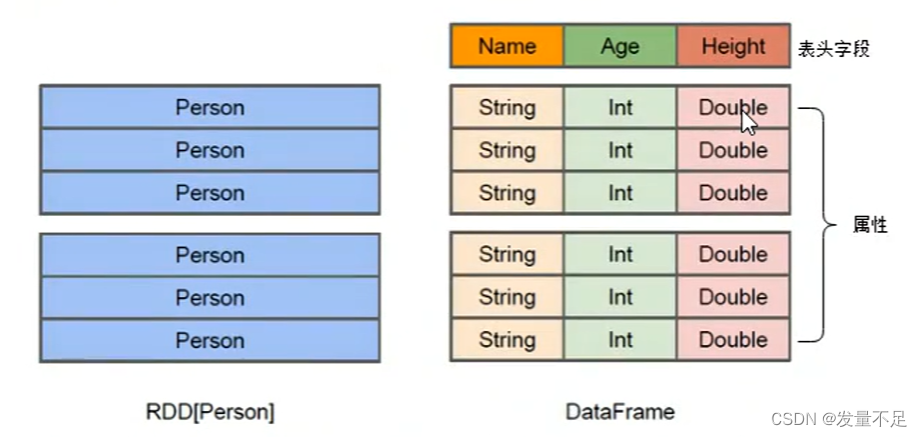
DataFrame的结构类似于传统数据库的二维表格,并且可以从很多数据源中创建,如结构化文件、外部数据库、Hive表等数据源。
RDD:分布式弹性数据集,分布式Java对象存储。
DataFrame:可以看出分布式Row对象的集合,在二维表数据集的每一列都带有名称和类型,这些就是schema(元数据)
DataFrame与Hive类似支持嵌套数据类型(如Struct、Array、Map)
DataFrame:除了提供比RDD更丰富的算子外,更重要的特点是提升Spark框架执行效率,减少数据的读取时间,和优化执行结果。
二.DataFrame 的创建
先启动集群和Spark
zkServer.sh start(在opt目录下)
start-all.sh(随意目录下)
sbin/start-all.sh(在spark目录下启动)
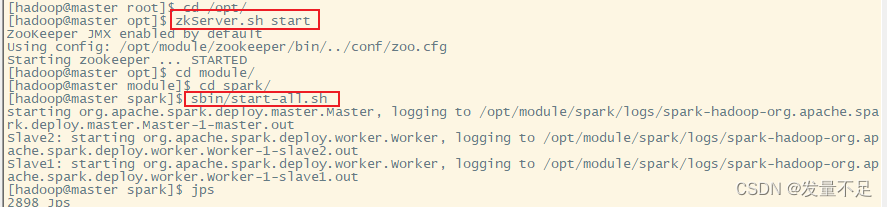 在slave1和slave2下启动zkServer.sh start
在slave1和slave2下启动zkServer.sh start

数据准备
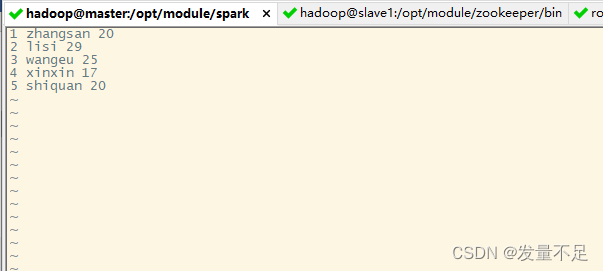
在spark目录下创建文本
vi person.txt
输入如下内容
hadoop fs -put person.txt /spark/
hadoop fs -ls /spark/ (查看是否成功)

#启动Spark-Shell
#Spark-shell –master local[2]
或者如下
Step 3 启动Spark
bin/spark-shell spark://master:7077,slave1:7077,slave2:7077
直接创建DataFrame
val personDataFrame = spark.read.text("/spark/person.txt")
personDataFrame.printSchema()
personDataFrame.show()

RDD转换DataFrame
通过RDD的toDF()方法,可以将RDD转换为DataFrame对象,具体代码如下所示:
//读文件并按空格分割成 数组RDD
val lineRDD = sc.textFile("/spark/person.txt").map(_.split(" "))
//定义样式类
case class Person(id:Int,name:String,age:Int)
//转换成lineRDD
val personRDD = lineRDD.map(x=>Person(x(0).toInt, x(1),x(2).toInt))
//转换DataFrame
val personDataFrame = personRDD.toDF()![]()
//显示DataFrame
personDataFrame.show
三.DataFrame 的常用操作
DataFrame提供了两种语法风格,1 DSL风格语法,2 SQL语法风格
DSL风格语法:
1 show:查看DataFrame中具体类容信息
2 printSchema:查看DataFrame中Schema信息
3 select:查看DataFrame中选取部分列的数据
personDataFrame.show
personDataFrame.printSchema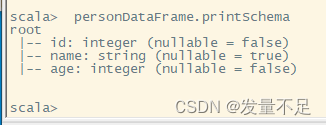
Select:col:某一列,as:重命名 filter:过滤groupBy() ,对记录进行分组sort排序
personDataFrame.select(personDataFrame.col("name")).show
personDataFrame.filter (personDataFrame.col("age")>=25).show
personDataFrame.sort (personDataFrame.col("age").desc).show
智能推荐
anaconda spyder闪退_spyder闪退 用户名汉字-程序员宅基地
文章浏览阅读52次。在试过很多方法后,包括但不限于新建环境变量,改变下载的版本,改变下载的网站等,都不能解决闪退的问题。于是我又改回来了,然后创建了一个新账户,并把它设置为管理员。(具体怎么操作,自己去搜一下吧。如果你的用户名是中文,请先把它改成英文,还是不行的话,再去找其他办法吧。然而改用户名后,我的文件都找不到了,桌面又回到了刚买的时候,就两图标了。在新账户重新下载了anaconda,spyder可以正常打开了。然后我发现,是因为我的用户名是中文。_spyder闪退 用户名汉字
framework学习路线和方法_framework开发-程序员宅基地
文章浏览阅读5.8k次,点赞30次,收藏107次。之前分享过我转framework的经历,可以看这里《我是如何从Android开发转framework开发的》,今天根据自己实际工作感受整理出一份framework的学习路线和方法,仅供参考,如有不足,还望指正。学习framework是一件非常枯燥的事情,原因在于相比于app开发的coding,framework更侧重于对源码的reading,但学习它能让我们更深入的了解Android系统,增加自身的知识储备,降低自己在行业中的可替代性,延长自己的职业生涯,提高自身身价。_framework开发
Mac电脑联网快捷键恢复系统_option+command+r-程序员宅基地
文章浏览阅读2.8k次,点赞4次,收藏4次。Mac电脑联网快捷键恢复系统_option+command+r
自定义控件_继承cwnd 自定义控件-程序员宅基地
文章浏览阅读723次。新建自定义控件: 添加类->MFC类->选基类(可以选各种基类,如果要全部实现功能全新控件,就选CWnd)。输入类名 CxxxxWnd 生成2个文件 xxxxWnd.cpp, xxxxWnd.h;在里面添加消息的响应处理功能,尤其添加wm_paint消息的处理用来绘制控件的外观。 使用自定义控件: 1.包含xxxxWnd.h头文件。 2.如果是从 CWnd继承的自定义控件,需要动态生成控件。如_继承cwnd 自定义控件
BSN合作伙伴大会 | 赵会义:粮食行业信息化发展现状与区块链技术应用展望_bsn发展现状-程序员宅基地
文章浏览阅读313次。本期为国家粮食和物资储备局信息化推进办处长赵会义的分享,题为《粮食行业信息化探索现状与区块链技术应用展望》。_bsn发展现状
Elastic:如何成为一名 Elastic 认证工程师,Elastic 认证分析师及 Elastic 认证可观测性工程师_elasticsearch认证-程序员宅基地
文章浏览阅读2.2w次,点赞33次,收藏109次。Elasticsearch 无疑是是目前世界上最为流行的大数据搜索引擎。根据 DB - Engines 的统计,Elasticsearch 雄踞排行榜第一名,并且市场还在不断地扩大:能够成为一名 Elastic 认证工程师也是很多开发者的梦想。这个代表了 Elastic 的最高认证,在业界也得到了很高的认知度。得到认证的工程师,必须除了具有丰富的 Elastic Stack 知识,而且必须有丰富的操作及有效的解决问题的能力。拥有这个认证证书,也代表了个人及公司的荣誉。针对个人的好处是,你可以.._elasticsearch认证
随便推点
19.相机,棱镜和光场_相机视野经过棱镜后-程序员宅基地
文章浏览阅读1k次,点赞20次,收藏23次。1.Synthesis(图形学上)合成:比如之前学过的光线追踪或者光栅化2.Capture(捕捉):把真实世界存在的东西捕捉成为照片。_相机视野经过棱镜后
Docker多机集群部署之MySQL集群(PXC)_不同云服务器搭建pxc集群-程序员宅基地
文章浏览阅读1.2k次。一、环境说明:宿主机:Win10虚拟机工具:VMware Workstation 15系统及版本:Ubuntu16.04Docker版本:18.09.3涉及到的虚拟主机:192.168.1.100 haproxy192.168.1.101 node1192.168.1.102 node2192.168.1.103 node3二、准备镜像#拉取percona/percona-xtradb-cluster:5.6#pxc5.7版本不支持不使用k8s或者et.._不同云服务器搭建pxc集群
AT命令_at命令默认采用的是text模式吗?-程序员宅基地
文章浏览阅读2.3k次,点赞2次,收藏10次。AT命令最常见的应用场景:1、智能手机:一般智能手机都是一个主芯片控制一个通信模块,这个通信模块就是一个完整的、简单的手机,包括手机应该有的射频、基带等部分,还有GSM协议栈,完全可以独立打电话、发短信、用GPRS上网等。主芯片实现复杂的应用软件。主芯片和通信模块之间通过AT命令,也就是做主芯片通过AT命令控制通信模块打电话,发短信等。2、其他通信模块。例如出租车上的车载台,通信模块可以接收控..._at命令默认采用的是text模式吗?
虚拟机上安装ubuntu18.04.4_ubuntu-18.04.4-desktop-amd64.iso-程序员宅基地
文章浏览阅读1.7k次,点赞2次,收藏21次。准备:主机系统为win10,虚拟机版本为:VMware Workstation 15 Pro系统镜像:ubuntu-18.04.4-desktop-amd64.iso1.配置VMware1.1 创建新的虚拟机 在文件下拉菜单选择新建虚拟机,出现的新建虚拟机想到选择自定义;点击下一步; 硬件兼容性选择默认的就好,我的虚拟机是workstation15,..._ubuntu-18.04.4-desktop-amd64.iso
windbg(蓝屏调试分析教程)_蓝屏调试工具-程序员宅基地
文章浏览阅读2.9k次。一、WinDbg是什么?它能做什么?WinDbg是在windows平台下,强大的用户态和内核态调试工具。它能够通过dmp文件轻松的定位到问题根源,可用于分析蓝屏、程序崩溃(IE崩溃)原因,是我们日常工作中必不可少的一个有力工具,学会使用它,将有效提升我们的问题解决效率和准确率。二、WinDbg6.7下载1.WinDbg(蓝屏分析修复工具) 6.7 免费版(32位)_蓝屏调试工具
OVN Southbound DB简介及其相关命令示例_southbound databus-程序员宅基地
文章浏览阅读3k次。Southbound DB 里面有如下几张表:Chassis:chassis这个概念, Chassis 是 OVN 新增的概念,OVS 里面没有这个概念。 chassis表的每一行表示一个 HV 或者 VTEP 网关,由 ovn-controller/ovn-controller-vtep 填写,包含 chassis 的名字和 chassis 支持的封装的配置(指向表 Encap),如_southbound databus