2019独角兽企业重金招聘Python工程师标准>>> ...
”重置offset“ 的搜索结果
kafka-manager1.3.0.8 可修改offset值
源码解析:Apache RocketMQ重置offset解析。
新版本的kafka,groupid的信息是当成主题存储的在__consumer_offsets中的,所以7天后(默认),会自动帮你清理的
Kaffa 按照时间重置 Topic 的所有分区 offset,时区问题?重置命令无效? 一、问题原因 本质是 Timestamp 转成 DateTime 会默认读取 JVM 的时区,导致我们指定参数的时间比实际 Kafka 重置 offset 时间早了 8 小时。...
kafka-0.9.0-重置offset-ResetOff.java; 相关下载链接://download.csdn.net/download/kliners/10770341?utm_source=bbsseo
之前写过两篇关于重置offset的博文,后来使用过程中都有问题。 经过各种尝试,终于找到了解决方案。 直接上代码: # coding=utf8 from confluent_kafka import Consumer, KafkaError, TopicPartition def reset...
如果使用的自动提交偏移量的模式,偏移量会给到kafka或者zk进行管理,其中kafka的偏移量重置给了重新消费kafka内未过期的数据提供了机会,当消费者出错,比如消费了数据,但是中途处理失败,导致数据丢失,这时候...

1.可以将kafka中的偏移量自动重置为最新的2.使用于kafka有积压,但是也不想处理积压,直接消费最新的数据3.此版本只支持offset存储在zk中, 暂未提供offset存储在kafka中的版本# -*- coding:utf-8 -*-import timeimport...
最近在spark读取kafka消息时,每次读取都会从kafka最新的offset读取。但是如果数据丢失,如果在使用Kafka来分发消息,在数据处理的过程中可能会出现处理程序出异常或者是其它的错误,会造成数据丢失或不一致。这个...
此命令将重置所有分区的消费者偏移量。此命令将将分区数增加到 3。此命令将将分区的副本数设置为 1、2 和 3。
为什么80%的码农都做不了架构师?>>> ...
每次启动Topic-A都会出现这一行信息,把offset重置到25143。 如果就算我运行一段时间,消费到25200,然后关闭程序,下次启动又自动给我重置到25143。 多次启动都是用的group-5. 启动程序后用groups.list命令可以...
昨天在写一个 java 消费kafka数据的实例,明明设置auto.offset.reset为 earliest,但还是不从头开始消费,官网给出的含义太抽象了。earliest: automatically reset the offset to the earliest offset,自动将偏移量...
可以直接监听一个消费组,然后给消费组设置多个topic,并且设置里面的分区——>除此之外,可对目标主题里的分区设置offset。MANUAL_IMMEDIATE:消费者消费完消息后再提交offset。MANUAL:消费者消费一条提交一条,...
kafka 重置偏移量
如果kafka服务器记录有消费者消费到的offset,那么消费者会从该offset开始消费。如果Kafka中没有初始偏移量,或者当前偏移量在服务器上不再存在(例如,因为该数据已被删除),那么这时 auto.offset.reset 配置项就会...
Pulsar 消费重置,移动偏移量有6种方法 设置subscriptionInitialPosition,在创建consume的时候处理。 consumer.seek(messageId)方式。 admin.topics().peekMessages(topicName,subsciptionName,numMessages)方式。...
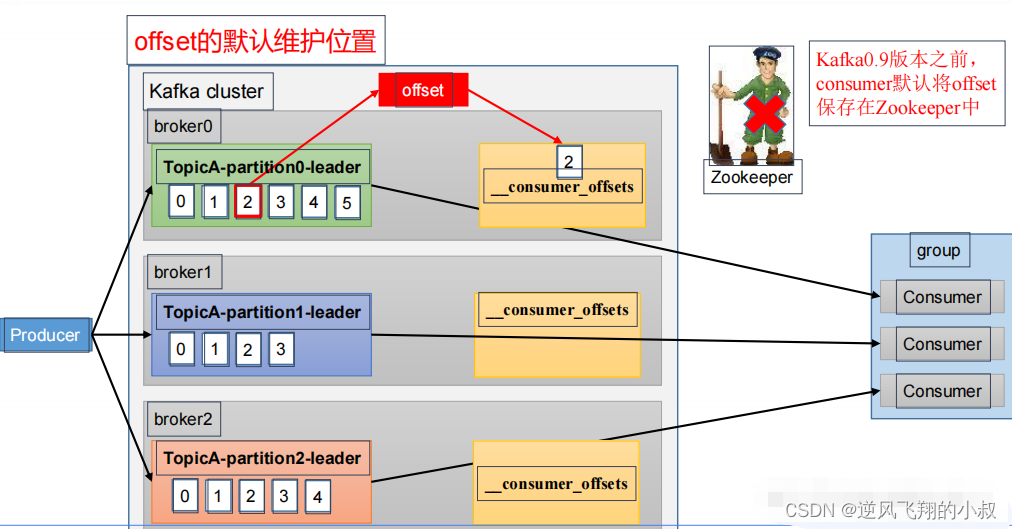

不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!什么参数都不加:只是打印出位移调整方案,不具体执行。
配置文件: groupId = new setGroupId = asd topics = kafkaTest1 servers =IP:port,IP:port time=20200714230000 public class SetOffset { private static int partitionNum; ...private static String groupId;...


Flink手动维护offset 引言 对比spark来说一下,flink是如何像spark一样将kafka的offset维护到redis中,从而保证数据的一次仅一次消费,做到数据不丢失、不重复,用过spark的同学都知道,spark在读取kafka数据后,...
更新kafka的offset到最新的位置 1.进入docker容器,用来执行kafka相关的更新offset的命令; docker ps | grep kafka | awk '{print $1}' 2.执行如下命令,用来将执行kafka集群中的groupId的offset更新为最新; /opt...
最近项目出现问题,产生了很多无用的topic消息到kafka集群,需要手动设置某个topic的consumer的Offset。 网上查了查资料,这里记录一下。 Using kafka-consumer-groups.sh With the setup done, you should be ...
推荐文章
- Vite 的好与坏,你怎么看?-程序员宅基地
- python基础之运算符(五)_python使用赋值运算符将num1增加5-程序员宅基地
- 启动计算机引导windows10,Win10系统引导项丢失了怎么办?修复Win10系统启动引导项的方法...-程序员宅基地
- Word报告自动生成(例如 导出数据库结构),理论+实战双管齐下_一键生成word报告-程序员宅基地
- 人脸识别(一)调用face++实现人脸检测。_face px-程序员宅基地
- uniapp或者vue循环列表点击事件传参获取不到值得情况解决问题_uniapp 对象里有值,属性获取不到值-程序员宅基地
- Faith学习笔记:JAVA基础(2)-- 常量、变量和数据类型_数据faithfuld 变量解释-程序员宅基地
- css中calc属性不起作用_width: calc(100%-234px);属性值无效-程序员宅基地
- 如何安装p4vasp-程序员宅基地
- 天梯赛 打印沙漏-程序员宅基地