词频统计 在很多情况下我们会遇到这样的问题·,给你一篇文章,让你统计其中多次出现的词语。这就是词频统计问题。当然不我们的文本可以是英文、可以是中文、也可以是其他国家的文字。首先我们来分析这个问题的IPO:...
”词频统计“ 的搜索结果
词频统计以及TF-IDF原理以及代码实现,在TF-IDF中常被问的问题:为什么TF要进行标准化操作?为什么要取对数?为什么IDF分母中要进行+1(IDF如何进行平滑处理的)?为什么要词频 * 逆文档频率(TF-IDF要用乘法)?

如何对大数据进行词频统计.pdf
标签: 文档资料
如何对⼤数据进⾏词频统计 假设有40亿个整数,每个整数占4字节,但是内存只有1G,问如何得到TOP10出现频率最⾼的整数。 ⾸先统计词频需要⽤到HashMap,key是整数值,value是出现次数,假如直接遍历40亿个整数,并⽤...

1.资料名称:2023-2000年中国地级市城市绿色环保词频统计数据 2.数据指 标:参考C刊《商业经济与管理》王竞达(2023)老师研究的做法,通过对全国各地级 市政府工作报告中生态环境相关的关键词进行统计,分别从环境...
读取txt文件进行词频统计
Python实例10:文本词频统计6.6.1 问题分析在英文中文中,出现哪些词,出现多少次?6.6.2 hamlet英文词频统计CalHamletV1.py6.6.3 三国演义人物出场统计CalThreeKingdomsV1.pyCalThreeKingdomsV2.py# CalHamletV1.py...


主要是读取文本,然后进行分词、词干提取、去停用词、计算词频,有界面,很实用

在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的次数。一个词语出现的次数越多,...词频统计是自然语言处理技术中最基础的技术之一,在词频统计中,如何区分词是很关键的一环。
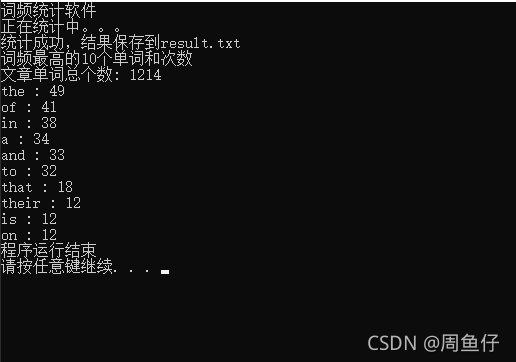
在学习了组合数据类型和文件操作之后就可以做出下面的文本词频统计的小程序了:1. 下面是英文文本的词频统计,统计了作者的一篇英文论文#文本词频统计:英文文本def gettext():#从文件中获取文本text = open("target...


实现文章的词频统计,用c语言编写的程序,北航OJ题目
自然语言理解 关于词频统计的代码 利用treemap来完成

1、词频统计(1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本挖掘的重要手段。它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其变化趋势...

MapReduce 程序是一种用于大规模数据处理的编程模型。它的基本思路是将大型数据集分成若干个小型数据块,然后将这些小型数据块分发给计算机集群中的若干台机器进行处理。...对于词频统计的 MapRedu...
切换到mapreduce目录(/usr/Java/是我存放Hadoop文件的目录,可自行更换)对word.txt进行词频统计,并且将统计后生成的文件放在output目录中。将word.txt放到input文件夹中。编辑该文件,写入一些字符串。创建一个...
词频统计是自然语言处理领域中的一项基础且重要的任务。通过本文的介绍,相信读者已经对词频统计的基本原理、常用方法以及实践应用有了深入的了解。在未来,随着自然语言处理技术的不断发展,词频统计将会在更多的...
1 #CalHamletV1.py2 def getText(): #定义函数读取文件3 txt = open("hamlet.txt","r").read()4 txt = txt.lower() #将所有字符转换为小写5 for ch in '!@#$%^&*(_)-+=[...

推荐文章
- Springboot——mybatis配置_springboot配置mybatis-程序员宅基地
- 计算机网络体系结构-程序员宅基地
- 韶音、南卡、Oladance开放式耳机值得买吗?多维度测评实力最强品牌-程序员宅基地
- bert简介_tensorflow 2.0+ 基于BERT的多标签文本分类-程序员宅基地
- jupyter notebook常用快捷键和语法_jupyter notebook怎么换行-程序员宅基地
- 教材编者,请多点儿“钻研”精神-程序员宅基地
- MySQL如何更改数据库名字_mysql update数据库名称-程序员宅基地
- windows上最好用的文件管理软件 Directory Opus_directory ops-程序员宅基地
- AWT图形界面设计编程——1.AWT容器_awt容器定义-程序员宅基地
- 一文看懂mybatis底层运行原理解析-程序员宅基地