无
”爬虫,python“ 的搜索结果
这是一篇详细介绍Python爬虫入门的教程,从实战出发,适合初学者。读者只需在阅读过程紧跟文章思路,理清相应的实现代码,30 分钟即可学会编写简单的 Python 爬虫。 这篇 Python 爬虫教程主要讲解以下 5 部分内容: ...
以下是爬虫Python基础知识的一些要点: 网络请求库:Python中常用的网络请求库有urllib和requests,它们可以发送HTTP请求并获取响应内容。 解析库:解析库用于解析HTML或XML等页面文档,提取出所需的数据。Python...
1、python爬取企查查公司信息 2、添加应对反爬的设置 3、开箱即用,有示例数据文件 4、windows版本 5、需要登录或者人工验证 6、采用selenium模块+chromedriver驱动
利用Python来实现的爬虫,高效且可靠。
书籍资源
网络爬虫-Python和数据分析,非常好的python 学习书籍
Python爬虫利器二之Beautiful Soup的用法
爬虫python入门 爬虫python入门实战源码 爬虫python入门实战源码 爬虫python入门实战源码
爬虫python,巨细!Python爬虫详解

讲诉python爬虫的20个案例 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
81个Python爬虫源代码
标签: 爬虫
81个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础python爬虫基础...

基于Python+MongoDB的可配置异步爬虫
该资源为完整版的python代码,python2.7.实现简单的网络爬虫,爬去目标数据
百度贴吧的爬虫制作和糗百的爬虫制作原理...用Python写的百度贴吧的网络爬虫。 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行。 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地。 ...
基于Python网络爬虫的设计,可以爬取360新闻,百度贴吧等,百分百可用
对于新手做Python爬虫来说是有点难处的,前期练习的时候可以直接套用模板,这样省时省力还很方便。
抓取程序员宅基地文章的简单爬虫python源码
python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫python爬虫,拉勾网爬虫...

用多线程的方法来加速爬虫。
python简单实现网络爬虫
标签: python
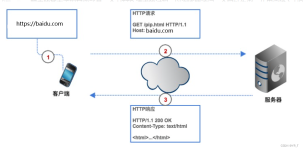
爬虫就是一个自动化数据采集工作,你只需要告诉它需要采取哪些数据,给它一个url,就可以自动的抓取数据。其背后的基本原理就是爬虫模拟浏览器向目标服务器发送http请求,然后目标服务器返回响应结果,爬虫客户端...
推荐文章
- C++语法基础--标准库类型--bitset-程序员宅基地
- [C++] 第三方线程池库BS::thread_pool介绍和使用-程序员宅基地
- 如何使用openssl dgst生成哈希、签名、验签-程序员宅基地
- ios---剪裁圆形图片方法_ios软件圆形剪裁-程序员宅基地
- No module named 'matplotlib.finance'及name 'candlestick_ochl' is not defined强力解决办法-程序员宅基地
- 基于java快递代取计算机毕业设计源码+系统+lw文档+mysql数据库+调试部署_快递企业涉及到的计算机语言-程序员宅基地
- RedisTemplate与zset redis_redistemplate zset-程序员宅基地
- 服务器虚拟化培训计划,vmware虚拟机使用培训(一)概要.ppt-程序员宅基地
- application/x-www-form-urlencoded方式对post请求传参-程序员宅基地
- 网络安全常见十大漏洞总结(原理、危害、防御)-程序员宅基地