
”爬虫总结和详解“ 的搜索结果
使用lxml包,从简单的网页中获取文本和图片 爬取网址:http://www.pythonscraping.com/pages/page3.htm 第一步 ,看网页结构 F12打开开发者模式,大致网页结构如下,看图: 下面这个图片是针对一个tr标签的...
技术维度:详细讲解了 Python 网络爬虫实现的核心技术,包括网络爬虫的工作原理、如何用 urllib 库编写网络爬虫、爬虫的异常处理、正则表达式、爬虫中 Cookie 的使用、爬虫的浏览器伪装技术、定向爬取技术、反爬虫...
爬虫也了解了一段时间了希望在半个月的时间内结束它的学习,开启python的新大陆,今天大致总结一下爬虫基础相关的类库---Urllib。 Urllib 官方文档地址:https://docs.python.org/3/library/urllib.html urllib...


HttpClient+JSoup详解 (附各种Demo) 写在前面:记录了学习数据挖掘以来的学习历程,先上之前的一些总结,随着学习的加深会慢慢更新。 Java爬虫-快速入门 目录 1.所需环境 2.HttpClient与Jsoup简介 3.为什么要...


最近,为了提取裁判文书网的有关信息,自己迈入Python的学习之路,写了快两周的代码,自己写这篇文章总结下踩过的坑,还有遇到一些好的资料和博客等总结下(站在巨人肩膀上,减少重复工作),以便自己后期复习和...
以下是个人在学习beautifulSoup过程中的一些总结,目前我在使用爬虫数据时使用的方法的是:先用find_all()找出需要内容所在的标签,如果所需内容一个find_all()不能满足,那就用两个或者多个。接下来遍历find_all的...
通过使用DB-API 2.0规范,可以轻松地执行SQL命令、查询数据和管理数据库连接。尽管SQLite是一个轻量级的数据库,但它提供了许多关系型数据库的功能,如事务处理、索引和约束等。这使得它成为许多应用程序的理想选择...





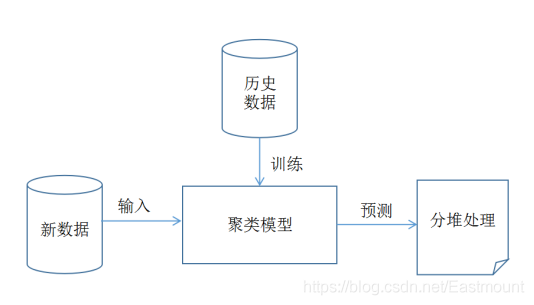
Python-玩转数据-爬虫基本原理 一、说明: 网络爬虫,又名网页蜘蛛或网络机器人,是请求网站并提取数据的自动化程序,爬虫程序只提取网页代码中对我们有用的数据。 二、爬虫基本流程一般分四步 1、发起请求:用程序...
爬虫python,巨细!Python爬虫详解
接下来,我们将详细介绍这种解决方案的步骤、监控指标以及数据来源,最后对整个方案进行总结并讨论可能的改进或扩展。该方法通过Python编写爬虫程序,自动抓取网易buff网页版上的物品价格信息,并将其存储到数据库中...



scrapy部署介绍相关的中文文档地址 ... 安装相关库 scrapyd 是运行scrapy爬虫的服务程序,它支持...而且scrapyd可以同时管理多个爬虫,每个爬虫还可以有多个版本 pip3 install scrapyd scrapyd-client 发布爬虫需要使用...
在定义pipline时,只需要定义一个类并实现process_item(self, item, spider)方法,参数中的item就是爬取到的每一个数据对象,spider是爬虫的实例。该方法主要有两种返回值: item对象 DropItem 异常:即抛弃当前的...
反爬虫机制与反爬虫技术(一)上篇中,我们详细介绍和使用了User-Agent伪装、代理IP、请求频率控制等反爬虫技术,本篇将重点针对动态页面处理和验证码识别进行介绍和案件详解近年来,网站安全性越来越高,许多网站为了...

推荐文章
- 使用tomcat打开html文件,为什么tomcat可以打开html文件,不能打开jsp文件呢?-程序员宅基地
- 使用delphi 10.2 开发linux 上的webservice-程序员宅基地
- python学习第三个坑-程序员宅基地
- PytorchTotrial5_ModernCNN_torch trial-程序员宅基地
- NP管理器和MT哪个强_MT管理器相信大家都很熟悉的[勉强],功能可以说非常强大,开发逆向的时候经常需要用到。...-程序员宅基地
- unity学习笔记_unity .autodestruct-程序员宅基地
- 网络算法——基于堆的Prim算法和基于并查集的Kruskal算法_prim算法用并查集吗-程序员宅基地
- RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1-程序员宅基地
- 数组的两种传递方式_数组传递-程序员宅基地
- html点击按钮跳转到另一个界面_网页制作:一个简易美观的登录界面-程序员宅基地