这里整理了python爬虫详解教程和Python爬虫教程知识点总结,中文PDF文档。例外,python爬虫实例详解主要为大家详细介绍了python爬虫实例,包括爬虫技术架构,组成爬虫的关键模块,具有一定的参考价值。需要的朋友可...
”爬虫总结和详解“ 的搜索结果
Python爬⾍基础教程-Urllib详解 前⾔ 爬⾍也了解了⼀段时间了希望在半个⽉的时间内结束它的学习,开启python的新⼤陆,今天⼤致总结⼀下爬⾍基础相关的类库---。 Urllib urllib提供了⼀系列⽤于操作URL的功能。 ...
BeautifulSoup讲解。标签选择筛选功能弱但是速度快 建议使用find()、find_all() 查询匹配单个结果或者多个结果 如果对CSS选择器熟悉建议使用select() 记住常用的获取属性和文本值的方法。语言python



无论你是在进行数据挖掘、爬虫开发还是测试自动化,XPath都是一个非常有用的工具。选择难度: 如果需要处理复杂的文档结构或选择操作,XPath可能更适合,但对于简单的操作,CSS选择器更直观。性能: 在处理大型文档时...
原理 中文分词,即 Chinese Word Segmentation,即将一个汉字序列进行切分,得到一个个单独的词。表面上看,分词其实就是...下面我们对这几种方法分别进行总结。 基于规则的分词方法 这种方法又叫作机械分词方法、基于


随着互联网的快速发展,网络上的信息爆炸式增长,而爬虫技术成为了获取和处理大量数据的重要手段之一。在Python中,`requests`模块是一个强大而灵活的工具,用于发送HTTP请求,获取网页内容。本文将介绍`requests`...
导语:网络爬虫是一种重要的数据...本文将详细介绍两个知名的Python网络爬虫框架:Scrapy和PySpider。我们将分别探讨它们的特点、用法以及示例代码,帮助你选择适合的框架来开发高效的网络爬虫。一、Scrapy框架简介。
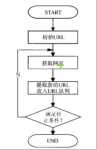
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网 页下载到本地,形成一个互联网内容的镜像备份。通用...

由此,网络爬虫技术应运而生。 网络爬虫简介 网络爬虫(web crawler,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种用来自动浏览万维网的程序或者脚本。爬虫可以验证...
总结来说,爬虫是一种利用编写程序自动获取互联网信息的技术手段。Python是一种常用的编程语言,也是爬虫开发中广泛使用的语言之一。通过使用第三方库来发送HTTP请求、解析网页内容、处理和存储数据,我们可以编写出...
这篇文章主要介绍了使用正则表达式实现网页爬虫的思路详解,需要的朋友可以参考下网页爬虫:就是一个程序用于在互联网中获取指定规则的数据。思路:1.为模拟网页爬虫,我们可以现在我们的tomcat服务器端部署一个1....
详解用User-Agent进行反爬虫的原理和绕过 随着 Python 和大数据的火热,大量的工程师蜂拥而上,爬虫技术由于易学、效果显著首当其冲的成为了大家追捧的对象,爬虫的发展进入了高峰期,因此给服务器带来的压力则是...
这篇文章主要介绍了使用正则表达式实现网页爬虫的思路详解,需要的朋友可以参考下网页爬虫:就是一个程序用于在互联网中获取指定规则的数据。思路:1.为模拟网页爬虫,我们可以现在我们的tomcat服务器端部署一个1....
Scrapyd部署爬虫项目 博客目的:本博客介绍了如何安装和配置Scrapyd,以部署和运行Scrapy spider。 Scrapyd简介: Scrapyd是一个部署和运行Scrapy spider的应用程序。它使您能够使用JSON API部署(上载)项目并控制...

requests是一种Python的HTTP模块,requests模块可以处理URL编码,会话cookie和HTTP基本身份验证等功能。与urllib库相比,requests提供了简便易用的API,使用更加方便。同时requests是一种流行的Python网络请求库,它...
scrapy爬虫详解
lxml是一款功能强大且高效的网络爬虫工具,可以帮助你轻松地进行数据采集和信息提取。在Python中,lxml库是一款功能强大且高效的网络爬虫工具,具有解析HTML和XML文档、XPath定位、数据提取等功能。除了HTML文档,...

爬虫的工作原理主要包括网页请求、数据解析和数据存储等步骤。首先,爬虫需要确定要爬取的目标网址,并向目标网站发送HTTP请求获取网页的内容。在发送请求之前,爬虫可以选择合适的请求方法(如GET或POST),并可以...
平时我们使用 requests 时, 通过两种方法拿到响应的内容: import requests ...a = response.content # type: bytes b = response.text # type: str 其中 response.text 是我们常用的. requests 的...
1-1课程介绍视频ev4.mp4 ...8-2 Scrap教程和第一个爬虫ev4.mp4 8-3 firefox firebug以及 chrome工具.ev4.mp4 8-4 scrap shel分析应用宝网站结构.ev4.mp4 8-5 python实现 scrap爬取应用宝网主页ev4,mp4
推荐文章
- Codeforces-学校排队-程序员宅基地
- 计算机毕业设计ssm基于JAVA的图书馆自习室座位预约系统194fd9 (附源码)轻松不求人_基于ssm的图书馆预约座位-程序员宅基地
- 实值复变函数求导 ——(Wirtinger derivatives)_wirtinger导数-程序员宅基地
- VMWare虚拟机设置固定IP上网方法_vm虚拟机只允许指定ip访问-程序员宅基地
- 深度学习修炼(一)线性分类器 | 权值理解、支撑向量机损失、梯度下降算法通俗理解-程序员宅基地
- 基于SpringBoot的社区团购APP+02043(免费领源码)可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案-程序员宅基地
- 如何在无公网IP环境下远程访问Serv-U FTP服务器共享文件-程序员宅基地
- uniapp的navigateTo页面跳转参数传递问题_uni.navigateto刷新携带参数丢失-程序员宅基地
- C++中std::getline()函数的用法-程序员宅基地
- vue 工作中的一些小总结(基础知识供刚入门的小伙伴看 vue+elementUi+vsCode+vue-router+iconfont )_mac+elementui+vscode-程序员宅基地