“爬虫”是一种形象的说法。互联网比喻成一张大网,爬虫是一个程序或脚本在这种大网上爬走。碰到虫子(资源),若是所需的资源就获取或下载下来。这个资源通常是网页、文件等等。可以通过该资源里面的url链接,...
”爬虫入门“ 的搜索结果
对于Python爬虫爱好者来说,寻找美丽的姑娘是最喜欢做的事情之一了
爬虫指的是一种自动化程序,能够模拟人类在互联网上的浏览行为,自动从互联网上抓取、预处理并保存所需要的信息。爬虫运行的过程一般是先制定规则(如指定要抓取的网址、要抓取的信息的类型等),紧接着获取该网址的...
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了
什么是网络爬虫 网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。 优先申明:...
要成功编写一个Python爬虫,关键在于对目标网站进行精确的定制化设计。同时,面对常见的反爬虫机制,你还需要具备应对策略的准备。Python爬虫的技能树广泛而深入,即使是最基础的爬虫,也涉及到HTML、CSS和...
Python 爬虫实战入门教程 州的先生《Python 爬虫实战入门教程》作者:州的先生微信公众号:州的先生 博客:2018/3/241Python 爬虫实战入门教程 州的先生目录目录 2第一章:工具准备 31.1、基础知识 31.2、开发环境、...
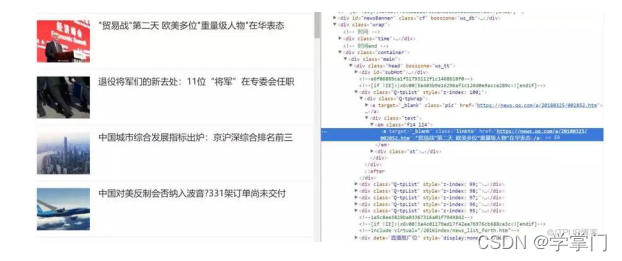
F12打开调试控制台,点击“Network”,点击打开的那个页面“news.baidu.com”,右边的“Header”里面会显示出来响应头和请求头。 参考: https://www.cnblogs.com/wzk153/p/9145684.html ...
而第三篇则让我们迈入了更高级的领域,学习了如何使用Scrapy库来处理更大规模的爬虫任务。Scrapy让我们更高效、更自动化地抓取了目标网站的宝可梦图片,为我们的爬虫之旅增添了更多神奇的色彩,并为之后更复杂的任务...
本文介绍了Python网络爬虫的入门和基础知识,涵盖了Requests和Beautiful Soup库的使用,以及一个简单的爬虫示例。网络爬虫是一项强大的技术,可以帮助您自动从互联网上收集数据,但请务必遵守网站的使用条款和法律...
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成...

文章同步:http://blog.csdn.net/wgyscsf



恭喜你,你已经能够应付大多数的爬虫场景了,已经基本入门了python 网络爬虫的世界φ(゜▽゜*)♪接下来,本系列课程的第三课,将讲述本系列课程的提高内容:利用scrapy库以应对更多更复杂的爬虫场景。已经基本入门了...

Python爬虫入门教程10:彼岸壁纸爬取Python爬虫入门教程11:新版王者荣耀皮肤图片的爬取Python爬虫入门教程12:英雄联盟皮肤图片的爬取Python爬虫入门教程13:高质量电脑桌面壁纸爬取Python爬虫入门教程14:有声书...
手把手教你如何入门,如何进阶。 目录 1. BeautifulSoup是什么? 2. BeautifulSoup怎么用? 2.1 解析数据 2.2 提取数据 2.3 find() 方法 和 find_all() 方法 2.4 Tag标签 和 css 选择器 练习题 联系我们,...
马哥高薪实战学员 【Python爬虫入门到实战-史上最详细的爬虫教程,限时免费领取】 爬虫分类和ROBOTS协议 爬虫URLLIB使用和进阶 爬虫URL编码和GETPOST请求 转载于:https://blog.51cto.com/10515215/2385329...
Python爬虫入门基本代码


https://zhuanlan.zhihu.com/p/21377121?refer=xmucpp
此文属于入门级级别的爬虫,老司机们就不用看了。 本次主要是爬取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。 首先我们打开163的网站,我们随意选择一个分类,这里我选的分类是国内新闻。然后鼠标...
Python爬虫入门之 初识爬虫 简单介绍Python爬虫相关的知识 文章目录Python爬虫入门之 初识爬虫1. 什么是爬虫?2. requests的基本使用2.1 你的第一个爬虫程序2.2 headers请求头的重要性3. 案例:豆瓣电影`Top250`...
#-*-coding:utf8-*-import requests import re # url = 'https://www.crowdfunder.com/browse/deals' url = 'https://www.crowdfunder.com/browse/deals&template=false' # html = requests.get(url).text...# print ht
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地