"Kafka与HDFS在海量数据存储中的选择关键":Kafka提供高吞吐、低延迟、无限堆积能力,技术根本原因在于其分布式架构和消息队列机制;HDFS适合长期存储,提供无限容量和更强查询能力。未来关注分布式流数据存储和时序...
”海量数据“ 的搜索结果
Flink 海量数据如何高效去重
互联网 Java 工程师进阶知识完全扫盲:涵盖高并发、分布式、高可用、微服务、海量数据处理等领域知识
人工智能-Hadoop

从海量素剧中查找中位数,从海量数据中查找一个数,海量数据问题

服务器之间传输海量数据文件的解决方案
海量数据介绍-欢迎加入&合作
海量数据划分内存不足问题解决方法
标签: 内存不足
所谓海量数据处理,是指基于海量数据的存储、处理和操作等。因为数据量太大无法在短时间迅速解决,或者不能一次性读入内存中。在解决海量数据的问题的时候,我们需要什么样的策略和技术,是每一个人都会关心的问题。...
例如:随着高并发和互联网技术的不断发展,海量数据的缓存这门技术也越来越重要,很多人都开启了怎么用Redis去搭建多主多从的海量数据缓存,本文就介绍了怎么利用Docker去搭建三主三从的数据缓存案例。提示:以下是...
基于高校海量数据的数据挖掘技术研究.pdf
基于云计算的海量数据挖掘分类算法研究.pptx
亿矿云大数据处理框架:借助Hadoop、Spark、Storm等分布式处理架构,满足海量数据的批处理和流处理计算需求
人工智能-机器学习-数据预处理
主要介绍了Hibernate批量处理海量数据的方法,较为详细的分析了Hibernate批量处理海量数据的原理与相关实现技巧,需要的朋友可以参考下

它提供了一种简单而强大的方式来处理批处理作业,如数据导入/导出、报表生成、批量处理等。什么是Spring Batch?Spring Batch旨在简化批处理作业的开发和管理。它提供了一种可扩展的模型来定义和执行批处理作业,将...
我工作中的一部分是数据采集,可能会有点复杂,但我乐于其中。我扮演着“数据捕手”的角色,负责收集各种数据然后转化为可用的信息。接下来让我跟大家分享一个关于数据采集的亲自经历。1.任务开始:追逐目标在着手...
大数据量,海量数据 处理方法总结 包括Bloom filter 哈希 bit-map 堆 双层桶划分 数据库索引 倒排索引 外排序 trie树等。细分为适用范围、要点、实例等。
海量数据干扰下Web数据挖掘技术分析.pdf
戴汝为:用大数据挖掘海量数据金矿.pdf
大数据技术分享大数据处理与分析 AdMaster海量数据分析架构 共18页.pptx
Openlayers憋了好久,终于憋出了WebGL的渲染器,然而只支持点要素类型,要是线和面类型的要素,数据量级一上去,就没法用了。我们看看隔壁的Mapboxgl,诞生之日起就是WebGL渲染,而且openlayers新出的WebGLPoint ...
铁路BIM海量数据实时压缩方法研究.pdf
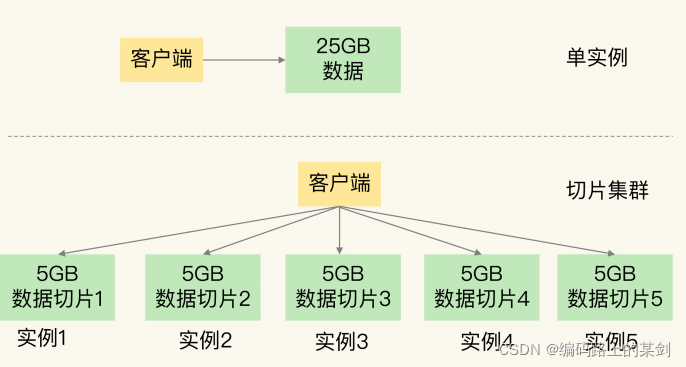
1. 处理海量数据问题的四种方式 分治 基本上处理海量数据的问题,分治思想都是能够解决的,只不过一般情况下不会是最优方案,但可以作为一个baseline,可以逐渐优化子问题来达到一个较优解。传统的归并排序...
海量数据导入与导出MATLAB的有效方法.pdf
easyExcel 导出百万数据
推荐文章
- linux查看系统编码和修改系统编码的方法_linux 机器编码设置-程序员宅基地
- 企业微信小程序_小程序开发工具及真机调试_host配置及代理_微信开发者工具 本地代理-程序员宅基地
- 详解C语言自定义类型——结构体struct_struct结构体定义和声明-程序员宅基地
- kettle-基本使用_kettle箭头-程序员宅基地
- python输入两个数值区间若能合并区间_【python-leetcode57-区间合并】插入区间-程序员宅基地
- IDM免费安装注册使用,两步注册成功_idm注册-程序员宅基地
- SM4国密算法原理及python代码实现_根据sm4_s计算sm4_sbox_t-程序员宅基地
- DMA映射 dma_addr_t-程序员宅基地
- XSS跨站脚本攻击漏洞_小明是公司的开发工程师,发现公司网站存在xss漏洞,通过修改javascript代码进-程序员宅基地
- 软件体系结构_采用结构化技术开发的软件是否具有体系结构?-程序员宅基地