在机器学习中,我们经常需要计算样本之间的差异,进而评价个体的相似性和类别等信息。特征空间中两个样本之间的距离就是两个样本相似性的一种反映。常见的分类和聚类算法,如k近邻、k-means、层次聚类等、等都会选择...
”机器学习与知识发现“ 的搜索结果
目录简介一、监督学习1、决策树(Decision Tree,DT)2、朴素贝叶斯分类器(Naive Bayesian Model,NBM)3、最小二乘法(Least squares)4、逻辑回归(Logistic Regression)5、支持向量机(SVM)6、K最近邻算法...

整理了一下机器学习-算法工程师需要掌握的机器学习基本知识点,并附上了网上笔者认为写得比较好的博文地址,供参考。(持续更新) 机器学习相关基础概念 Variance(方差)与bias(偏差) ...
监督学习是一种使用标记数据来训练机器学习模型的机器学习类型。在标记数据中,输出已经是已知的。模型只需要将输入映射到相应的输出。例如,监督学习的一个例子是训练一个识别动物图像的系统。下面附上我们训练的...


随着机器学习的激增,越来越多的专业人士选择从事机器学习工程师的职业。而成为机器学习工程师最好的入门方法之一就是亲自动手开发一个项目,今天我们就来简单聊一聊10个机器学习项目。

数学与机器学习的联系
标签: 机器学习
数学又是现代科学的基石,几乎所有现代科学都与数学密不可分,尤其是数据科学与机器学习。 要想成为机器学习算法工程师,必须具备一定的数学知识。众所周知,机器学习是计算机技术,但它的底层是数学。更何况,机器...
本项目使用Flask框架搭建基于机器学习的南昌市租房价格预测系统 (简易版)其中关于Flask知识点可参考文章Flask全套知识点从入门到精通,学完可直接做项目其中关于南昌市租房价格预测可参考文章基于XGBoost算法构造...

在本文中,我们一起学习如何将机器学习应用于癌症数据集。 1.摘要 支持向量机(SVM)是机器学习中最流行的有监督学习算法之一。许多研究人员都通过实践证明了该算法的优异性。 SVM既可以应用于回归问题,也可以应用...

定义: 统计学: 统计学是通过搜索、整理、分析、描述数据等手段,以达到推断所测对象的本质,甚至预测对象未来的一门综合性科学。...它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声
欢迎大家移步我的公众号查看,更新进度更快,其中不只有机器学习的内容,还有大数据、生物信息学、NLP等知识板块: 机器学习 | 基本概念(一)http://burningcloud.cn/article/102/index.html 机器学习 | 基本概念...



弱人工智能近几年取得了重大突破,悄然间,已经成为每个人生活中必不可少的一部分。以我们的智能手机为例,看看到底温...传统的机器学习算法包括决策树、聚类、贝叶斯分类、支持向量机、EM、Adaboost等等。这篇文章将对
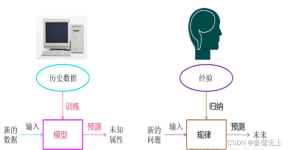
在36氪上看到一篇很好的关于机器学习的文章,对机器学习与各个领域的结合讲得非常清晰。 现小结一下如下。 基本定义: 机器学习方法是计算机利用已有的数据(经验),得出了某种模型(迟到的规律),并利用此模型...
在机器学习中,模型的实质是一个假设空间(hypothesis space),这个假设空间是“输入空间到输出空间所有映射”的一个集合,这个空间的假设属于我们的先验知识。然后,机器学习通过“数据+三要素”的训练,目标是...
向AI转型的程序员都关注了这个号☝☝☝整理 | suiling本文是对作者@Daniel Martinez(https://twitter.com/danielmartinezf)在GitHub上的开源项目介绍,作者通过思维导图对深度学习和机器学习中的一些重点和架构...
机器学习、深度学习选题方向 2.毕业论文命题(选题)技巧 3. 难度把控 3 最后 1 .机器学习、深度学习选题方向 深度学习已经在语音识别、图像处理等方面取得了巨大成功。其研究方向可以大致分为以下几个域:(标...
机器学习高频面试题(41道)
标签: 机器学习
它反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,即算法本身的拟合能力。Bias 可能会导致模型欠拟合,使其难以具有较高的预测准确性,也很难将你的知识从训练集推广到测试集。 Variance 是...
本文从机器学习平台的架构开始,再到具体的功能,然后从需求的角度带给读者思考,找到合适的机器学习平台建设之路。...如果读者对大数据、计算平台比较了解,能看到许多熟悉的内容,发现大数据平台与机器学习平...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地