分类器的作用:常规任务是利用给定的类别、已知的训练数据来学习分类规则和分类器,然后对未知数据进行分类(或预测)。逻辑回归(logistics)、SVM等常用于解决二分类问题,对于多分类问题(multi-class ...
”分类器“ 的搜索结果
随机森林是一种基于决策树的集成分类器,它通过随机选择特征和样本来构建多个决策树,并将多个决策树的结果进行投票来确定最终的分类结果。总的来说,分类器在数据分析中有着广泛的应用,可以帮助我们处理各种类型的...
使用场景方面,本资源可帮助您在处理分类或回归问题时,使用随机森林算法进行预测。例如,在金融、医疗、营销等领域,随机森林算法可以用于客户流失预测、疾病诊断、市场趋势分析等任务。 本资源的目标是帮助您掌握...
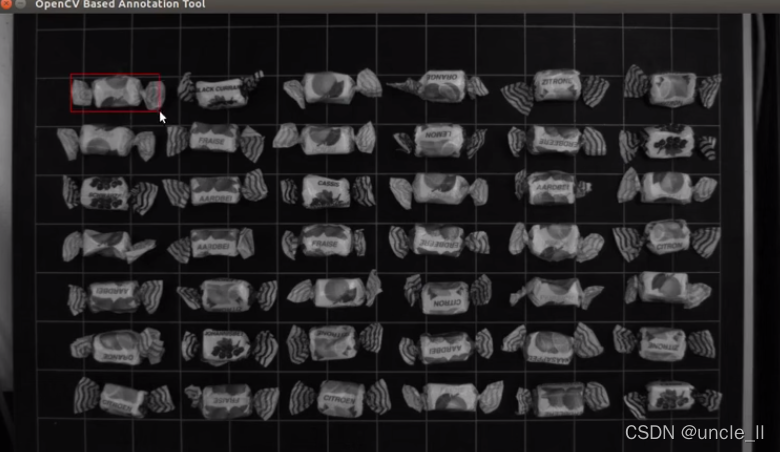
python 训练自己的分类器
在上一篇文章中,主要介绍了组学和pyradiomics的大致概念以及实现了一个最简单的代码(用pyradiomics进行组学特征提取并输出结果)。接下来这篇,我们主要讲,如何在之前的基础上使用分类器训练模型,实现图像分类。

分类器示例代码
标签: sklear 分类器
基于sklearn包实现的分类器代码,NB,AdaBoost,XGBoost,LR,RF,SVM,DT,GBDT,KNN
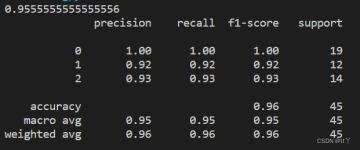
分类器的比较
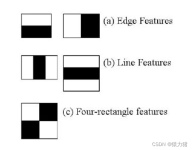
Haar特征和级联分类器是一种经典的目标检测算法,适用于检测物体在图像中的位置、大小和姿态等。本教程将详细介绍Haar特征和级联分类器的原理、实现和应用。

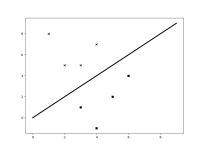
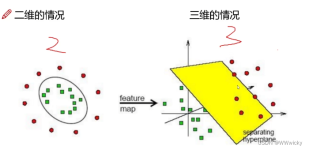
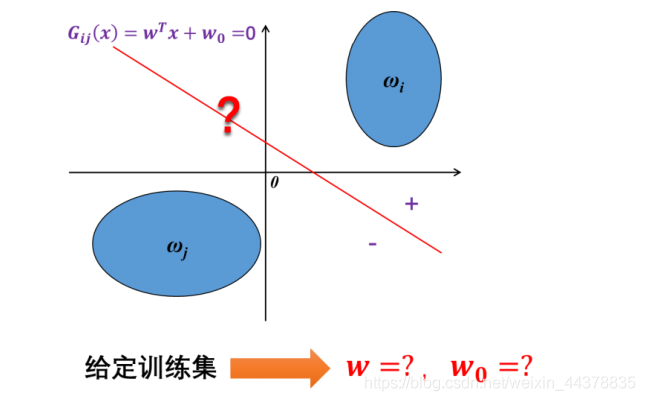
解决分类问题基本的方法有:线性分类器、决策树、朴素贝叶斯、人工神经网络、K近邻(KNN)、支持向量机(SVM); 组合基本分类器的集成学习算法:随机森林、Adaboost、Xgboost等。 一、线性分类器 线性分类器=...
博文:http://blog.csdn.net/zhuangxiaobin/article/details/25476833 这篇文章里所提供的工具和样本训练出来的分类器xml文件,可以使用文中的代码实践一下





# 多类分类器 from sklearn.datasets import fetch_openml minst = fetch_openml('mnist_784',version=1) X,y = minst["data"],minst["target"] X_train,X_test,y_train,y_test = X[:60000],X[60000:],y[:60000],y...


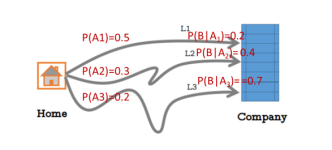
频率学派和贝叶斯学派 说起概率统计,不得不提到频率学派和贝叶斯学派,通过对概率的不同理解而演变的两个不同的概率学派。 频率学派 核心思想:需要得到的参数是一个确定的值,虽然未知,但是不会因为样本的...

推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地