kafka不重复消费
标签: kafka
Kafka作为当下流行的高并发消息中间件,大量用于数据采集,实时处理等场景,我们在享受他的高并发,高可靠时,还是不得不面对可能存在的问题,最常见的就是丢包,重发问题。 丢包问题:消息推送服务,每天早上,...
标签: kafka
Kafka作为当下流行的高并发消息中间件,大量用于数据采集,实时处理等场景,我们在享受他的高并发,高可靠时,还是不得不面对可能存在的问题,最常见的就是丢包,重发问题。 丢包问题:消息推送服务,每天早上,...
默认情况下,消费者一次会poll条消息 props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500); 代码中设置了长轮询的时间是1000毫秒 while (true){ /** * poll是拉取消息的长轮询 */ ConsumerRecords...
消费方式 ...同一个组里的,当动态扩展分区分配时新进入的消息接着消费分区消息而不是重新消费 offset是按照:goup+topic+partion来划分的,这样保证组内机器有问题时能接着消费 消费者组案例 ...
Kafka数据消费重复怎么处理
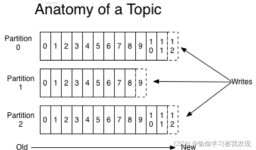
消费者在消费完消息之后会向 这个主题中进行 消费位移的提交。消费者在重新启动的时候就会从新的消费位移处开始消费消息。因为,位移提交是在消费完所有拉取到的消息之后才执行的,如果不能正确提交偏移量,就可能...

produce发送的消息分发到不同的partition中,consumer接受数据的时候是按照group来接受,kafka确保每个partition只能同一个group中的同一个consumer消费,如果想要重复消费,那么需要其他的组来消费。Zookeerper中...

kafka常用命令

本文作为深入分析kafka架构系列的终章,分析了kafka消费者的消费方式,分区分配策略,offset维护,其中重点详细的分析了三种分区分配策略,并举例对比,使对kafka感兴趣的读者能有所收获。

学会使用kafka
首先准备两个配置文件到resources producer.properties # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with ...
kafka命令大全
这些参数是Kafka管理工具的一部分,用于在Kafka集群上执行各种管理任务,例如创建、删除、配置和查看主题。根据具体的任务,您可以使用这些参数中的一个或多个来执行相应的操作。:指定要连接的Kafka Broker的主机名...
Flink消费kafka数据 import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api....
【记录】kafka从指定offset开始消费,参考链接http://www.pianshen.com/article/2025378464/ public class KafkaUtil { public static void main(String[] args) { Properties p = new Properties(); p.put(.....
作者:禅与计算机程序设计艺术 1.简介 Apache Kafka 是LinkedIn于2011年开源的一款分布式流处理平台,由Scala和Java编写而成。Kafka可以用于实时数据传输、日志聚合、应用指标监控等场景。本文主要介绍Kafka的使用...
但是kafka的消息消费没有确认机制,可能因为consumer崩溃导致消息没有完成处理。因此不建议将kafka用于一致性较高的业务场景,kafka经常被用做日志收集和数据仓库之间的缓存。比如将网站的浏览日志缓存到kafka,然后...

Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 Kafka 有如下特性: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的...
标签: kafka

Redis队列与Stream


消费者在消费完消息之后会向 这个主题中进行 消费位移的提交。消费者在重新启动的时候就会从新的消费位移处开始消费消息。因为,位移提交是在消费完所有拉取到的消息之后才执行的,如果不能正确提交偏移量,就可能...
public String title; public ConsumerRecords<byte[], byte[]> records; public KafkaConsumerSimple(String title, ConsumerRecords<byte[], byte[]&... this....
[root@1 kafka]# bin/kafka-consumer-groups.sh --list --zookeeper 1.zookeeper1:2181 console-consumer-15370 [root@1 kafka]# bin/kafka-consumer-groups.sh --zookeeper 1.zookeeper1:2181 --group console-...