二分 k-means 算法,此算法不需要标签变量,在 k-means 算法的基础上需要通过四个特征变量将 Iris 进行聚类。目标:通过 Iris 的四个特征值进行聚类,得到每个聚类中的质心,并把聚类结果写入文件中。 (2) 算法原理...
”二分K-means“ 的搜索结果
基于二分K-means的无线传感器网络分簇方法.pdf
聚类 聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。...
第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心。 第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组,跟定了那个质心。 第四步,当每个质心都聚集了一些点后,...
K-Means 系列:K-Means,二分K-Means,K-Means++,K-Meansll,canopy算法,MiniBatchK-Means算法。 K-Means系列聚类算法原理:https://www.cnblogs.com/pinard/p/6164214.html 用scikit-learn学习K-Means聚类:...
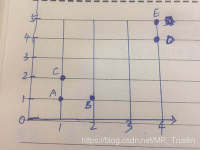
随机设置K个特征空间内的点作为初始的聚类中心。对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别。...如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
K-means算法的简介与Python3实现
Bisecting K-Means什么是二分K-Means二分K-Means原理算法优缺点代码实现 K-means博文点击此处 什么是二分K-Means 二分K-Means其实就是基于K-Means改进的算法,他的主要核心还是在于K-Means算法中,只不过它的算法...
关注微信公众号【Microstrong】,我写过四年Android代码,了解前端、熟悉后台,现在研究方向是机器学习、深度学习!一起来学习,一起来进步,一起来交流吧!...amp;mid=2247484014&idx=1&...
此处的K表示划分成K个聚类。利用各个点到质心之间的距离的平方和作为将节点划分到不同类的标准。当然也可以采用其他的距离计算方法,不一定是欧式距离方法。 一、KMeans 此方法一般是在数据分析前期使用,选取适当...
基于 K-means 算法的校园微博热点话题发现系统提示:适合用于课程设计或毕业设计,工作量达标,源码开放。
K-means算法是一种广泛应用的无监督机器学习聚类方法,旨在将数据集中的观测值分配到k个预定义的聚类中,使得每个聚类内的观测值彼此相似度尽可能大,而不同聚类间的相似度尽可能小。算法主要包括初始化、迭代聚类和...
二分k-means算法 二分k-means算法是分层聚类(Hierarchical clustering)的一种,分层聚类是聚类分析中常用的方法。 分层聚类的策略一般有两种: 聚合。这是一种自底向上的方法,每一个观察者初始化本身为一类,...
由于K-Means对于初始簇心比较敏感,解决K-Means算法对初始簇心比较敏感的问题,二分K-Means算法是一种弱化初始质心 的一种算法,具体思路步骤如下: 1、将所有样本数据作为一个簇放到一个队列中从队列中选择一个簇...

基于 K-means 算法的校园微博热点话题发现系统提示:适合用于课程设计或毕业设计,工作量达标,源码开放。
在单链接聚类中,两个聚类之间的链接距离是两个聚类中最接近的两个点的距离。...K均值聚类是一种常见的无监督学习算法,用于将一组数据点分组,使得每个组内的数据点尽可能相似,而组间的数据点尽可能不同。
二分K-Means算法是对K-Means算法的优化,主要优化的地方是在选取质心的时候,二分K-Means算法有效地避免了在初始选取质心时的误差,可以有效地提高算法效率。 测试数据:testSet2.txt 中间用tab分隔 3....

L.A.Zadeh在1965年最早提出模糊集理论,在该理论中,针对传统的硬聚类算法其隶属度值非0即1的严格隶属关系,使用模糊集合理论,将原隶属度扩展为 0 到 1 之间的任意值,一个样本可以以不同的隶属度属于不同的簇集,...
基于 K-means 算法的校园微博热点话题发现系统提示:适合用于课程设计或毕业设计,工作量达标,源码开放。
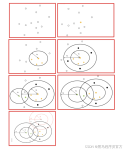
K-means算法: K-means算法是一个被广泛使用且简单的无监督算法。 K-means算法将数据分为k个簇类,使得每个簇类内部数据尽可能的相似,而簇之间的数据尽可能的不同。 K-means算法中的簇类数目为k,是用户认为给定的。...
K-Means是非常基础也是非常有效的一种聚类机器学习算法,即便过去数十年,它也有非常广泛的应用场景。从K-Means开始机器学习之路也是由于这算是我接触的第一个机器学习算法(自认为),由于我是自动化/控制专业的,...
基于 K-means 算法的校园微博热点话题发现系统提示:适合用于课程设计或毕业设计,工作量达标,源码开放。
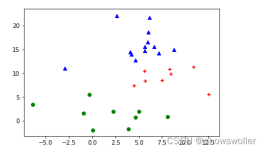
1. 二分K-means算法 算法描述 该算法首先将所有点作为一个簇,然后把这个簇一分为二。再选择其中一个簇继续进行划分,选择哪一个簇继续进行划分取决于对其...
聚类算法之——二分K-Means算法 为克服K-Means算法收敛于局部最小值问题,提出了二分K-Means算法 二分K-Means算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行...
推荐文章
- Adaboost模型公式的参数推导_adaboost加权公式-程序员宅基地
- 削峰填谷与应用间解耦:分布式消息中间件在分布式环境下并发流量控制的应用_消息中间件削峰填谷-程序员宅基地
- C 语言实现智能指针___attribute__((cleanup(free_stack)))-程序员宅基地
- 刮刮卡兑换-程序员宅基地
- H5横屏,移动端缓存_h5 横向-程序员宅基地
- python wx包_今天玩点啥:python真香系列之利用wxpy包写一个微信消息自动回复插件...-程序员宅基地
- 【PCL】使用自定义点类型时LNK2001、LNK2019链接错误解决_使用pcl出现link2019-程序员宅基地
- 获取数组中元素个数的方法_qt获取数组的元素个数-程序员宅基地
- Centos7 安装 docker及docker-compose_yum install -y yum-utils device-mapper-persistent--程序员宅基地
- c 与易语言程序间通信,易语言与三菱PLC通信-FX系列-程序员宅基地