”sparkSQL“ 的搜索结果

一:为什么sparkSQL? 3 1.1:sparkSQL的发展历程 3 1.1.1:hive and shark 3 1.1.2:Shark和sparkSQL 4 1.2:sparkSQL的性能 5 1.2.1:内存列存储(In-Memory Columnar Storage) 6 1.2.2:字节码生成技术...
(4)java程序实现SparkSQL 二、实验环境 Windows 10 VMware Workstation Pro虚拟机 Hadoop环境 Jdk1.8 三、实验内容 (一)SparkSQL的基本知识 (1)输入start-all.sh启动hadoop相应进程和相关的端口号 (2)启动...
SparkSQL的前身不叫SparkSQL,而叫Shark,最开始的时候底层代码优化,sql的解析、执行引擎等等完全基于Hive,总之Shark的执行速度要比hive高出一个数量级,但是hive的发展制约了Shark,所以在15年中旬的时候,shark...
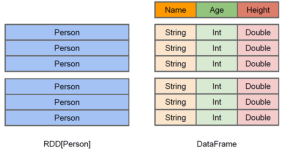
表头,表名,字段,字段类型。理解了RDD,DataFrame就容易理解些,DataFrame的思想来源于Python的pandas库,RDD是一个数据集,DataFrame在RDD的基础上加了Schema(描述数据的信息,可以认为是元数据,DataFrame曾经...
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用。它是将HiveSQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduc的程序的...
sparksql基础知识
标签: sparksql
sparksql简介 df的介绍 rdd转df df的一些基础操作
本文介绍的是SparkSQL组件各个物理执行计划的操作实现。把优化后的逻辑执行计划映射到物理执行操作类这部分由SparkStrategies类实现,内部基于Catalyst提供的Strategy接口,实现了一些策略,用于分辨logicalPlan子类...
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。...
Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。8.使用Impala,您可以访问存储在...
sparksql: Spark SQL是Spark处理数据的一个模块 专门用来处理结构化数据的模块,像json,parquet,avro,csv。 DataFrames API: 与RDD相似,增加了数据结构scheme描述信息部分。 比RDD更丰富的算子,更有利于...
sparksql: Spark SQL是Spark处理数据的一个模块 专门用来处理结构化数据的模块,像json,parquet,avro,csv,普通表格数据等均可。 与基础RDD的API不同,Spark SQL中提供的接口将提供给更多关于结构化数据和计算...

习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新*** 2. 判断Spark Application运行模式进行设置。* 7. 消费CRM Topic数据,打印控制台。* 3. 构建SparkSession实例对象。* 6....* 5....* 4....* 8....
目录SparkSQL1. 基础概念2.DataFrame3.SparkSql程序开发(1.x,2.x)(1)SparkSQL1.x(2)SparkSQL2.x SparkSQL 1. 基础概念 Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且...
元数据库SparkSQL驱动程序依赖项构建JAR lein uberjar # builds target/metabase-sparksql-deps-1.2.1.spark2-standalone.jar签署JAR(可选) # (Replace keystore, TSA and profile below with your own)jarsigner ...
第1关 SparkSQL加载和保存 package com.educoder.bigData.sparksql2; import org.apache.spark.sql.AnalysisException; import org.apache.spark.sql.SaveMode; import org.apache.spark.sql.SparkSession; public ...
【代码】2024年最全物流项目中SparkSQL的相关调优_spark 物流(2),2024年最新阿里大数据开发开发面试解答。
外部数据源API体现出的则是兼容并蓄,SparkSQL多元一体的结构化数据处理能力正在逐渐释放。关于作者:连城,Databricks工程师,Sparkcommitter,SparkSQL主要开发者之一。在4月18日召开的2015Spark技术峰会上,连城...
【代码】2024年大数据最全物流项目中SparkSQL的相关调优_spark 物流(3),2024吊打面试官系列。
有赞数据平台从2017年上半年开始,逐步使用SparkSQL替代Hive执行离线任务,目前SparkSQL每天的运行作业数量5000个,占离线作业数目的55%,消耗的cpu资源占集群总资源的50%左右。本文介绍由SparkSQL替换Hive过程中...
一、案例介绍 案例包含三个表:tbDate、tbStock、tbStockDetail。字段信息如下表: 二、要求 1、计算所有订单中每年的销售单数、销售总额 2、计算所有订单每年最大金额订单的销售额 3、计算所有订单中每年最畅销...
Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。 Spark SQL的特点: 1、和Spark Core的无缝集成,可以在写整个...
1.SparkSQL概述 1.1.SparkSQL的前世今生 Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速...
1.从HDFS中加载数据到DataFrame中 2.注册UDF函数,函数名为toUpper就是将所有名字变成大写 3.创建临时视图,然后执行注册的函数
本文讲述了Array、List、Map、本地磁盘文件、HDFS文件转化为DataFrame对象的方法;通过实际操作演示了dataFrame实例方法操作DataFrame对象、SQL语言操作DataFrame对象和ScalaAPI操作DataFrame对象
SparkSQL内置函数
SparkSQL通过Hive创建DataFrame问题分析 问题一 Caused by: org.apache.spark.sql.catalyst.analysis.NoSuchTableException: Table or view 'stu' not found in database 'default'; 分析:确实没有临时表View,...
ETL_with_Pyspark _-_ SparkSQL 一个示例项目,旨在使用Apache Spark中的Pyspark和Spark SQL API演示ETL过程。 在这个项目中,我使用了Apache Sparks的Pyspark和Spark SQL API来对数据实施ETL过程,最后将转换后的...
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地