”spark2.x“ 的搜索结果
GraphX是Spark中用于图和图计算的组件,GraphX通过扩展Spark RDD引入了一个新的图抽象数据结构,一个将有效信息放入顶点和边的有向多重图。如同Spark的每一个模块一样,它们都有一个基于RDD的便于自己计算的抽象数据...
一个 spark 应用的产生过程: 获取需求 -> 编写spark代码 -> 测试通过 -> 扔上平台调度。 往往应用会正常运行一段时间,突然有一天运行失败,或是失败了一次才...
文章目录前言详述对Hive的基本调研对Hive In Spark的兼容性探究的起因升级以后的Spark能否正常工作?通过Shims来增量支持高版本的Hive 的接口变化Spark对Hive版本支持的灵活配置以loadDynamicPartitioins方法来了解...
refer: ... ...今天在测试spark-sql运行在yarn上的过程中,无意间从日志中发现了一个问题: spark-sql --master yarn 14/12/29 15:23:17 INFO Client: Requesting a new applicatio

如何处理Spark数据倾斜
标签: 数据倾斜
一、什么是数据倾斜 在分布式集群计算中,数据计算时候数据在各个节点分布不均衡,某一个或几个节点集中80%数据,而其它节点集中20%甚至更少数据,出现了数据计算负载不均衡的现象。 数据倾斜在MR编程模型中是十分...
执行spark任务遇到数据量巨大的表时,任务经常出现心跳超时报错 org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout at ...
目录图(Graph)的基本概念图的术语图的经典表示方法Spark GraphX创建Graph通过文件加载属性图应用图的算子 图(Graph)的基本概念 图是由定点集合(vertex)及顶点间的关系集合(边edge)组成的一种网状数据结构。通常表示...
0.下载spark代码 git clone https://github.com/apache/spark.git cdspark git checkout -b v3.0.1_cdh6.1.0 v3.0.1# 新开一个分支 1.添加Cloudera maven镜像 及 Hadoop3.0 profile 在spark的...
一. MaxCompute Spark 介绍 MaxCompute Spark是MaxCompute提供的兼容开源的Spark计算... 社区原生Spark运行在MaxCompute里,完全兼容Spark的API,支持多个Spark版本同时运行 统一的计算资源 像MaxCompute SQL/MR等
概述 Apache Spark是一种快速和通用的集群计算系统。它提供Java,Scala,Python和...Zeppelin支持Apache Spark,Spark解释器组由5个解释器组成。 名称 类 描述 %spark SparkInterpreter 创建一个Spa

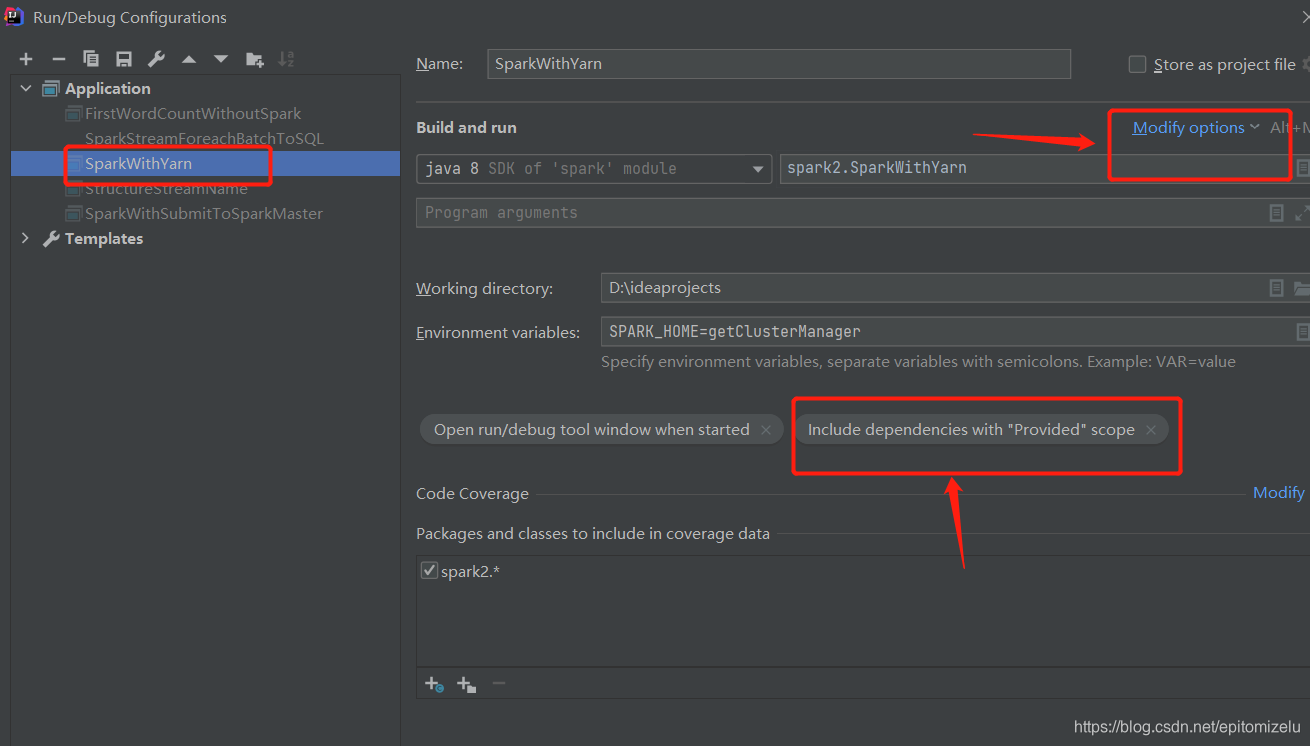
提交Spark任务到Yarn上运行,得到如下报错信息???? 研究了一会儿发现是自己粗心大意导致的,自己在本地IDEA跑多了,打包的时候忘记删除setMaster了,如下???? 虽然我们在提交任务到Yarn的时候,指定了Master,奈何...
Spark3.1.2 on k8s配置日志存储路径:spark-defaults.conf 使用的Hadoop版本是2.7.3 ...spark.yarn.historyServer.address=192.168.x.x:18080 spark.history.ui.port=18080 spark.eventLog.enabled true spark.eventLo
Spark2.X中Spark SQL的入口点:SparkSession。 项目目录 pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" ...
读入的text文档,x.split("\\|").toDF。如果最后一列(或最后几列)有空数据,map(x => x(lastone)),就会报数组越界的错,java.lang.IndexOutOfBoundsException。 所以只要用x.split("\\|&...
标签:spark,大数据,电商,用户行为 项目介绍: 本项目主要用于互联网电商企业中,使用spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为,购物行为,广告点击行为等)进行复杂的分析。用...
Spark 读写Hbase
标签: spark

建议大家用JDK8 + hadoop2.7+ spark3.X,各个版本互相有依赖 安装Java 到官网下载JDK 有一个问题:spark不支持最新的JDK,所以建议直接JDK8(似乎有说法高版本JDK带旧版本JDK?反正不支持就是了) 安装在没有...
Spark报错处理 1、问题:org.apache.spark.SparkException: Exception thrown in awaitResult 分析:出现这个情况的原因是spark启动的时候设置的是hostname启动的,导致访问的时候DNS不能解析主机名导致。 问题...
package ... import org.apache.spark.{SparkConf, SparkContext} class T1 { def f1(sc:SparkContext): Unit ={ val rdd = sc.parallelize(1 to 100,10) println("[原始RDD] rdd.partitions...
Spark Sql 分布式SQL引擎 Spark SQL可以使用其JDBC / ODBC或命令行界面充当分布式查询引擎。在这个模式下,用户或...对应HiveServer2 于Hive 1.2.1中的。可以使用Spark或Hive附带的beeline脚本测试JDBC服务器 启动...
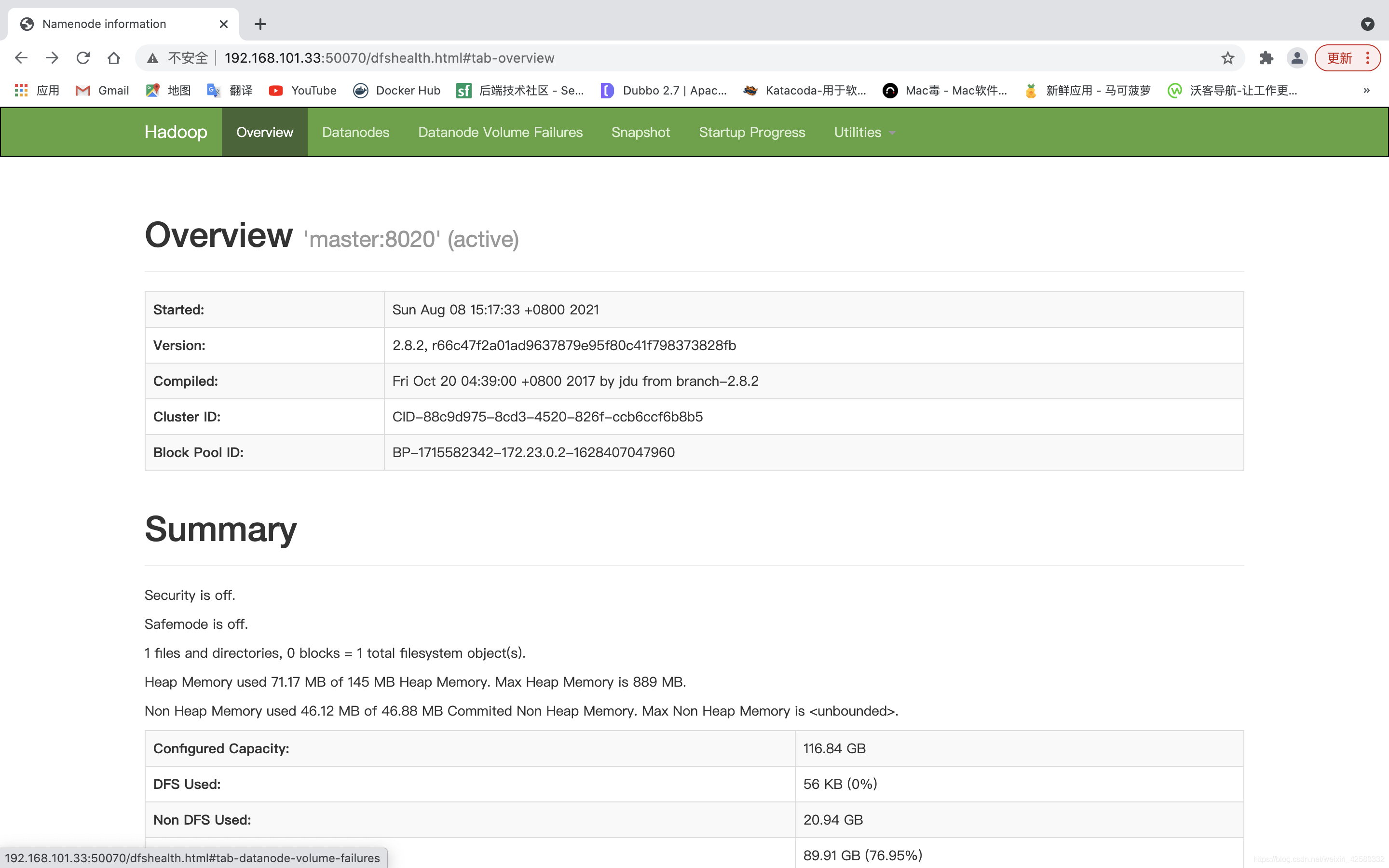

1、用./bin/spark-shell启动spark时遇到异常:java.net.BindException: Can't assign requested address: Service 'sparkDriver' failed after 16 retries!解决方法:add export SPARK_LOCAL_IP="127.0.0.1" to ...
@Author : Spinach | GHB ... 文章目录前言 前言 awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则...
【hive/beeline/spark】建表多分隔符,报:org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe前言HIVE SHELL调整报错解决方案BEELINE调整报错解决方案SPARK调整解决方案后记 前言 大数据平台数据入湖逻辑...

推荐文章
- Ubuntu/linux下下载工具_ubuntu下载软件助手 linux版本-程序员宅基地
- HTML、JSP前端页面国际化(i18n)_html全局国际化-程序员宅基地
- Python高级-08-正则表达式_写出能够匹配只有下划线和数字还有字母组成(且第一个字符必须为字母)的163邮箱(@1-程序员宅基地
- 寻仙手游维护公告服务器停服更新,寻仙手游2月1日停服更新公告 2月1日更新了什么...-程序员宅基地
- 用python自动预约图书馆座位_微信图书馆座位秒抢脚本-程序员宅基地
- Android真机或模拟器激活Xposed框架的方法_de.robv.android.xposed.installer-程序员宅基地
- 操作系统为什么要分用户态和内核态_用户态和内核态都需要cpu参与,为什么要区分-程序员宅基地
- 01—JVM与Java体系结构(简单介绍)_01_jvm与java体系结构.pptx-程序员宅基地
- 国有建筑企业数字化转型整体解决方案_建筑企业数字化转型行动方案-程序员宅基地
- 性能测试的软件------loadrunner_loadrunner有有三个图标,-程序员宅基地