Spark1.x编译与安装
标签: spark
1. Spark1.x编译与安装 1.1. 基础准备 见《1、基础准备(JDK、Maven、服务器配置)》。 1.2. Hadoop集群准备 见《2、Hadoop2.2.0 编译与安装》 1.3. Scala安装 1) 下载 集群中每台机器安装Scala;Scala官方下载...
标签: spark
1. Spark1.x编译与安装 1.1. 基础准备 见《1、基础准备(JDK、Maven、服务器配置)》。 1.2. Hadoop集群准备 见《2、Hadoop2.2.0 编译与安装》 1.3. Scala安装 1) 下载 集群中每台机器安装Scala;Scala官方下载...
标签: spark-sql
sparksql性能调优 性能优化参数 代码实例 import java.util.List; ...import org.apache.spark.SparkConf;...import org.apache.spark.api.java....import org.apache.spark.sql.api.java.JavaSQLContext
2)Spark Master内部通信服务端口号:7077 (类比于Hadoop的8020(9000)端口) 3)Spark Standalone模式Master Web端口号:8080(类比于Hadoop YARN任务运行情况查看端口号:8088) 4)Spark历史服务器端口号:...
Chapter 2: Developing Applications with Spark Chapter 3: External Data Sources Chapter 4: Spark SQL Chapter 5: Spark Streaming Chapter 6: Getting Started with Machine Learning using MLlib Chapter 7: ...
Total size of serialized results of 12189 tasks is bigger than spark.driver.maxResultSize 1024M. Total size of serialized results of 12082 tasks is bigger than spark.driver.maxResultSize 1024M. Total ...
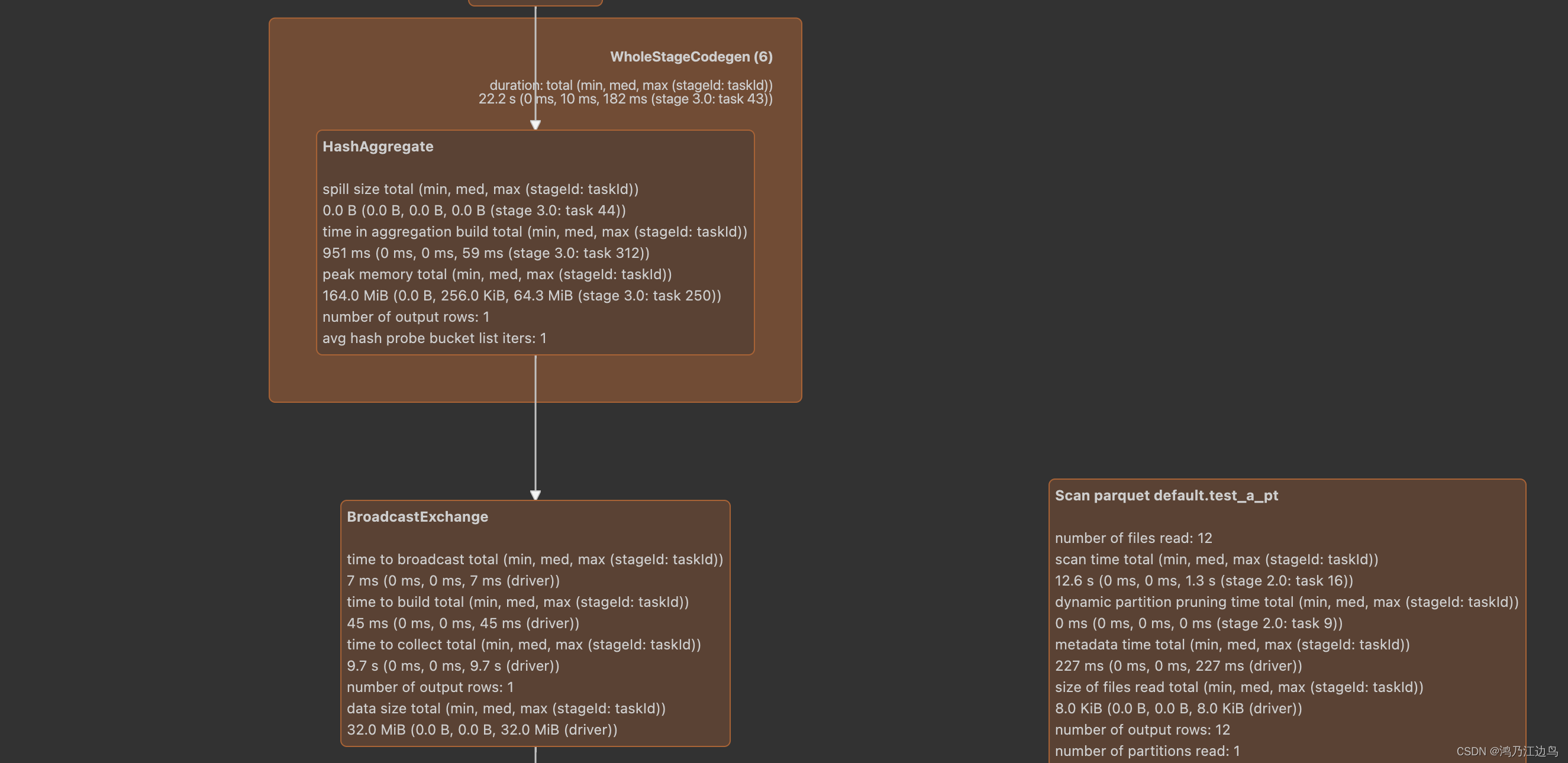
标签: spark

碰到这个问题也是一脸懵逼,刚开始以为是自己的环境问题,但是pyspark就没什么问题,后来在StackOverFlow中找到了解决方案 ...启动两个spark, 一个master,然后用spark-shell连接masterspark-class org.apache.spa
在Hudi与Spark整合的过程中,会有不少坑。本文记录Hudi与Spark整合过程中发现的坑点及其解决方案。
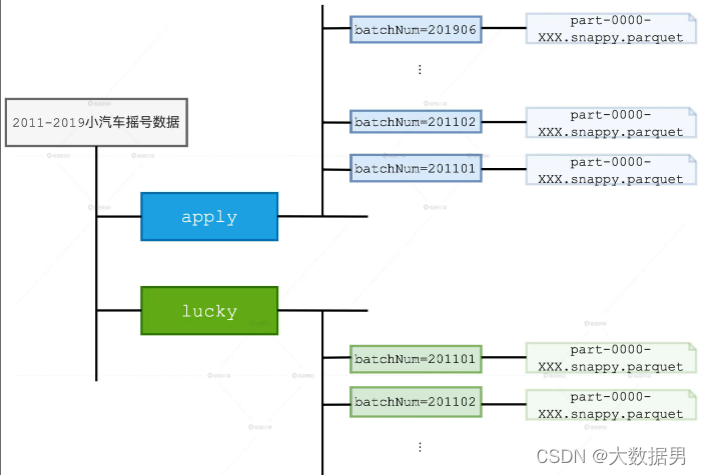

在完成集群配置之后,我写了下面的demo进行测试 如果把“spark://master:7077”变为local[2]就能正常运行,但是修改为spark集群就报错demo案例如下:package com.keduox import org.apache.spark.{SparkConf, ...
spark1.6.3 elasticsearch 5.4 bulk api ``` (Netty4Utils:117)-NoSuchMethodError io.netty.buffer.CompositeByteBuf.addComponents(ZLjava/lang/Iterable;)Lio/netty/buffer/CompositeByteBuf; at ...
一、pom.xml中配置 <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>11.2.0.3</version>...二、show the code...
0.3 Save Operations You can now save distributed datasets to the Hadoop filesystem (HDFS), Amazon S3, Hypertable, and any other storage system supported by Hadoop. There are convenience methods for se...

java.io.IOException: Unable to acquire 33554432 bytes of memory修改spark.sql.tungsten.enabled false 在1.6进行修复https://issues.apache.org/jira/browse/SPARK-10309#userconsent#

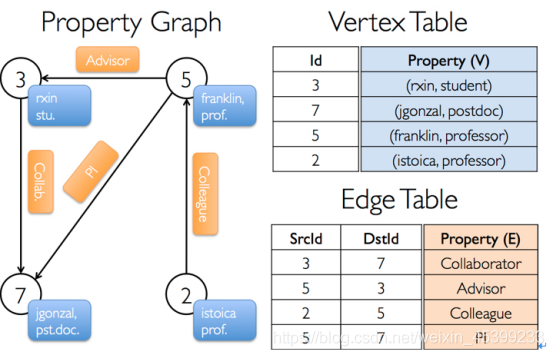

在 Spark 解析文件的时候,忽然报错 java.lang.ArrayIndexOutOfBoundsException。排查问题,也没发现有任何的异常。最后发现文件中,有一行数据的最后一个字段是空的,没有数据的,如下所示: 95009,梦圆圆,女,18,MA...
今天写了一行代码,感觉很简单啊,怎么报错呢,后来一看是一个超级低级错误, 大小写搞错了,countByKey写成了countBykey,所以Spark的算子大小写一定不要搞错,有可能会报上面的错误。scala> sc.textFile("E:\\...
遇到如下错误,但是在hive中单独运行,或者是在spark-shell中单独运行的也是毫无问题的,为何偏偏在sparksql中出问题,而且不存在所说的那个 character ’ ’ 。 还有就是我这个临时表本来是采用insert overwrite...
Spark Sql 相关设置及调优...-- Spark 2.x 版本中默认不支持笛卡尔积操作,需要手动开启 set spark.sql.crossJoin.enabled=true; 设置 shuffle 的并行度 因为笛卡尔积会产生 shuffle,默认的 shuffle 结果分区是 200
Spark 推测执行是一种优化技术。 在Spark中,可以通过推测执行,即Speculative Execution,来识别并在其他节点的Executor上重启某些运行缓慢的Task,并行处理同样的数据,谁先完成就用谁的... 2. 使用推测执行时应谨...

新手入门文章

Table or view not found: aaa.bbb The column number of the existing table dmall_search.query_embedding_data_1(struct<>) doesn’t match the data schema(struct<user_id:string,dt:string,sku_list:...
Spark 运行程序异常信息: org.apache.spark.SparkException: Task not serializable 解决办法