
”scrapy“ 的搜索结果
外链图片转存中…(img-tswjh568-1713697833093)]
本项目用于下载图片,因此可以仅构建图片名和图片地址字段。
Python,使用Scrapy爬取Boss直聘数据。 资源讲解地址:https://www.cnblogs.com/swarmbees/p/10011898.html
本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式爬虫的设计源码,包含61个文件,其中包括51个Python源代码文件,7个配置文件,以及1个Git忽略文件。此外,还包括1个文本文件和1个Markdown文档。...
链图片转存中…(img-LxFV0rxB-1713697797559)]
png)
Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架。这篇文章主要介绍了Python安装scrapy的正确姿势,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下
scrapy startproject Stocks创建工程 cd Stocks/ scrapy genspider stocks qq.com创建爬虫 东方财富网 + 腾讯证券 stocks.py # -*- coding: utf-8 -*- import scrapy import re class StocksSpider(scrapy.Spider): ...
一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**[外链图片转存中…(img-h6xkY441-1713681021860)][外链图片转存中…(img-D1...
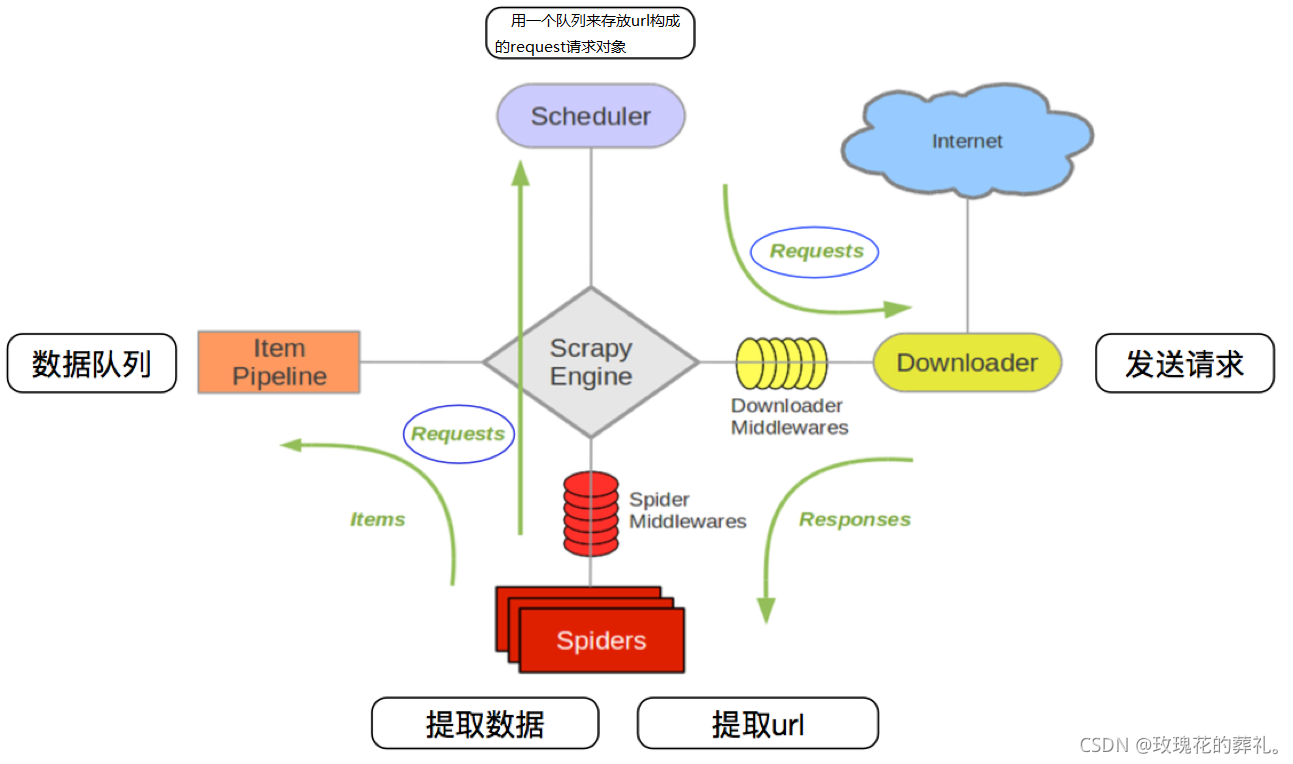
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给ScrapyEngine(引擎),由引擎交给Spider来处理。Spider(爬虫):它负责处理所有Responses,从中分析提取...
今天小编就为大家分享一篇利用Anaconda简单安装scrapy框架的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
scrapy startproject dongguang 设置items.py文件 # -*- coding: utf-8 -*- import scrapy class NewdongguanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # pass...
探索Scrapy Spider:高效Web数据抓取框架 项目地址:https://gitcode.com/huangtao1208/scrapy_spider 如果你在寻找一个强大的Python库来构建网络爬虫,那么Huangtao1208的Scrapy Spider项目值得一看。这是一个基于...
链图片转存中…(img-HxszfThc-1713697762629)]
Scrapy 爬虫框架 1. 概述 Scrapy是一个可以爬取网站数据,为了提取结构性数据而编写的开源框架。Scrapy的用途非常广泛,不仅可以应用到网络爬虫中,还可以用于数据挖掘、数据监测以及自动化测试等。Scrapy是基于...
今天小编就为大家分享一篇解决Mac安装scrapy失败的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
引擎(Scrapy):核心组件,处理系统的数据流处理,触发事务。调度器(Scheduler):用来接受引擎发出的请求, 压入队列中, 并在引擎再次请求的时候返回。由URL组成的优先队列, 由它来决定下一个要抓取的网址是什么,同时...
标记1:scrapy 使用的是 ,该 默认使用的就是 分析 会在 中调用: 其中: 默认值为 True而 只有在 中被调用: 那么 必定会被添加到 中,所有日志都会经过该 handler 进行输出既然已经知道 scrapy 的日志输出是...
基于Python的scrapy爬虫框架实现爬取招聘网站的信息到数据库
主要介绍了Python爬虫框架scrapy实现的文件下载功能,结合实例形式分析了scrapy框架进行文件下载的具体操作步骤与相关实现技巧,需要的朋友可以参考下
我是在win1064位系统,python2和python3共存的情况下安装的Scrapy,内附安装文本说明
主要介绍了pycharm创建scrapy项目教程及遇到的坑解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
主要介绍了python爬虫框架scrapy实现模拟登录操作,结合实例形式分析了scrapy框架实现模拟登陆操作的步骤、相关实现技巧与注意事项,需要的朋友可以参考下
我们通过以上学习,仅编写了2行代码,就完成了爬取数据的工作。
主要介绍了Python爬虫框架Scrapy实例代码,需要的朋友可以参考下
基于Scrapy的爬虫解决方案.docx
scrapy_project.zip
Scrapy的依赖包
推荐文章
- centos7初始化mysql 5.7.9(源码安装)-程序员宅基地
- undefined reference to `cvHaarDetectObjects'()(人脸检测)_cvhaardetectobjects未定义-程序员宅基地
- 如何将参数传递给批处理文件?_批处理 传递参数-程序员宅基地
- C++的一些小总结 类 静态成员变量/函数 this指针_c++ class 静态指针函数-程序员宅基地
- springboot小区物业管理系统7ffeo[独有源码]如何选择高质量的计算机毕业设计_小区物业管理系统er图-程序员宅基地
- mac-gradle的安装和配置,掌握这些知识点再也不怕面试通不过_mac gradle配置-程序员宅基地
- 2032:【例4.18】分解质因数(信奥一本通)-程序员宅基地
- html怎么设置默认状态,网页中如何设置默认图片?方式介绍-程序员宅基地
- milp的matlab的案例代码_matlab30个案例分析案例5代码-程序员宅基地
- html实现/ 简约好看、美观大方的个人导航页源码/开源个人主页html源码_个人导航html-程序员宅基地