”scrapy“ 的搜索结果

scrapy附带安装指导
Python实现爬虫是很容易的,一般来说就是获取目标网站的页面,对目标页面的分析、解析、识别,提取有用的信息,然后该入库的入库,该下载的下载。...这次介绍通过Scrapy爬虫框架来实现同样的功能。
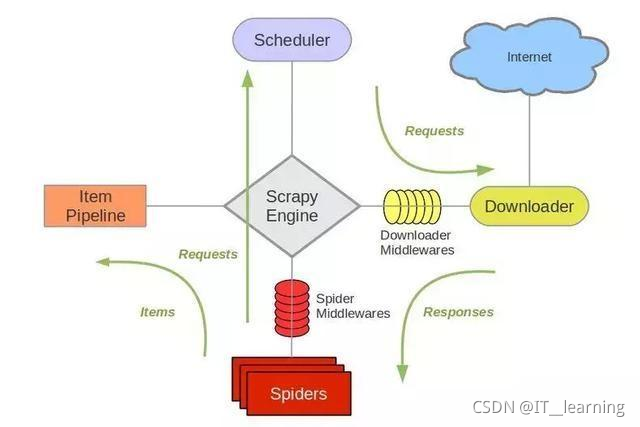
scrapy爬虫框架
标签: python

将Django和scrapy结合,实现通过Django的网页控制scrapy的运行,并将爬取的数据存入数据库。


本文我们通过抓取Quotes网站完成了整个Scrapy的简单入门,到此为止我们应该能对Scrapy的基本用法有一个初步的概念了。不过本文内容仅仅是Scrapy所有功能的冰山一角,还有很多内容等待我们去探索,我们后续文章继续...

杂乱的集群 该Scrapy项目使用Redis和Kafka创建按需分布式抓取集群。 目标是在许多等待的蜘蛛实例之间分发种子URL,这些蜘蛛实例的请求通过Redis进行协调。 由于边界扩展或深度遍历而导致的任何其他爬网也会在群集中...
我们简单介绍一下各个主要文件的作用: scrapy.cfg --配置文件,用于存储项目的配置信息。 mySpider/ --项目的Python模块,将会从这里引用代码。 mySpider/items.py --实体文件,用于定义项目的目标实体。 mySpider/...
Scrapy的Playwright集成 该项目提供了一个Scrapy下载处理程序,该程序使用执行请求。 它可用于处理需要JavaScript的页面。 该软件包不会干扰常规的Scrapy工作流程,例如请求计划或项目处理。动机在发布后,其中包括...
Scrapy中间件可使用Selenium处理javascript页面。 安装 $ pip install scrapy-selenium 您应该使用python> = 3.6 。 您还将需要一种与Selenium。 配置 添加要使用的浏览器,驱动程序可执行文件的路径,以及将要传递...
Scrapy S3管道 Scrapy管道将项目存储到或存储桶中。 与内置不同,管道具有以下功能: 在搜寻器运行时,管道按块将项目上载到S3 / GCS。 从Scrapy 2.3开始,内置的几乎可以完成相同的操作。 支持GZip压缩。 该...
安装scrapy:执行 pip install scrapy 【注】安装完成后,执行 pip list 检查以下上述两个模块是否安装成功。 三、在pycharm创建一个Scrapy项目 1.在pycharm中创建一个普通项目(Pure Project 即可),如下图。 2...
scrapy crawl spider_name 这时,爬虫就能启动,并在控制台(cmd)中打印一些信息,如下图所示: 但是,cmd中默认只能显示几屏的信息,其他的信息就无法看到。 如果我们想查看爬虫在运行过程中的调试信息或错误...
使用scrapy进行大型爬取任务的时候(爬取耗时以天为单位),无论主机网速多好,爬完之后总会发现scrapy日志中“item_scraped_count”不等于预先的种子数量,总有一部分种子爬取失败,失败的类型可能有如下图两种...
终端中执行scrapy startproject 项目名称 如scrapy startproject lagouspider 执行命令后生成的项目目录结构如下: 在项目目录中执行生成爬虫模板文件的命令 执行scrapy genspider 爬虫文件名 域名 如scrapy ...
被Scrapy自动添加的头部 在没有任何配置的情况下,scrapy会对请求默认加上一些头部信息 Scrapy会通过配置文件中的USER_AGENT配置,自动为头部添加User-Agent,这条配置会被任何包含User-Agent的配置覆盖 当请求经过...
主要介绍了scrapy爬虫:scrapy.FormRequest中formdata参数详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
将基于扭曲的scrapy / scrapy-redis改成基于asyncio,保留了几乎所有的scrapy / scrapy-reids功能 安装 # python版本>=3.7 (此项目是在3.8版本开发的) # 下载 git clone ...
知乎爬虫,通过手机扫码模拟登入,并且爬取回答评论等,并存入excel或写入sql
基于基于Python基于Scrapy+Gerapy+NLP+Django搭建的新闻整套系统框架结构,都是使用现成的框架及算法等内容进行组合构建的整套系统。 项目展示网址 二、 其中主要流程包括 Scrapy爬虫框架、整体框架设置 Gerapy...
本文实例讲述了Python实现从脚本里运行scrapy的方法。分享给大家供大家参考。具体如下: 复制代码 代码如下:#!/usr/bin/python import os os.environ.setdefault(‘SCRAPY_SETTINGS_MODULE’, ‘project.settings’)...
其实关于scrapy的很多用法都没有使用过,需要多多巩固和学习 1.首先新建scrapy项目 scrapy startproject 项目名称 然后进入创建好的项目文件夹中创建爬虫 (这里我用的是CrawlSpider) scrapy genspider -t crawl 爬虫...
使用python的scrapy爬取文本保存为txt文件 编码工具 Visual Studio Code 实现步骤 1.创建scrapyTest项目 在vscode中新建终端并依次输入下列代码: scrapy startproject scrapyTest cd scrapyTest code 打开项目...
通过Scrapy,我们可以轻松地完成一个站点爬虫的编写。但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码。如果我们将各个站点的Spider的公共部分保留下来,不同的部分提取...
推荐文章
- 【vue-treeselect+vxe-table】数据量大的时候懒加载,数据回显,输入框绑值,末级节点不要前面的箭头等问题详解_treeselect显示加载中-程序员宅基地
- 【从0入门JVM】-01Java代码怎么运行的_代码如何在jvm中运行-程序员宅基地
- TreeViewer应用实例(ITreeContentProvider与LabelProvider的使用)-程序员宅基地
- 如何将别人Google云端硬盘中的数据进行保存_谷歌网盘怎么保存别人的资源-程序员宅基地
- java中查看数据类型_java查看数据类型-程序员宅基地
- Scrapy-redis分布式+Scrapy-redis实战-程序员宅基地
- web播放H.264/H.265,海康,大华监控摄像头RTSP流方案_海康api hls怎么取265的流-程序员宅基地
- HTML详解连载(7)-程序员宅基地
- PHP使用多线程-程序员宅基地
- 由excel一键生成json的小工具(基于python,仅支持单层嵌套)_excel转json github-程序员宅基地