调用R语言自带kmeans()对给定数据集表示的文档进行聚类。 给定数据集: a) 数据代表的是文本信息。 b) 第一行代表词语,由于保密原因,词语已经被转意。第一列代表了文本的编号。 c) 红框中的数字...
”r语言聚类“ 的搜索结果
文本聚类是机器学习和自然语言处理领域中的一个重要研究方向。它通过将相似的文本文档划分到同一个聚类中,从而实现对大规模文本数据的有效组织和分析。其广泛应用于新闻推荐、客户细分、主题发现等场景。 作为经典的...
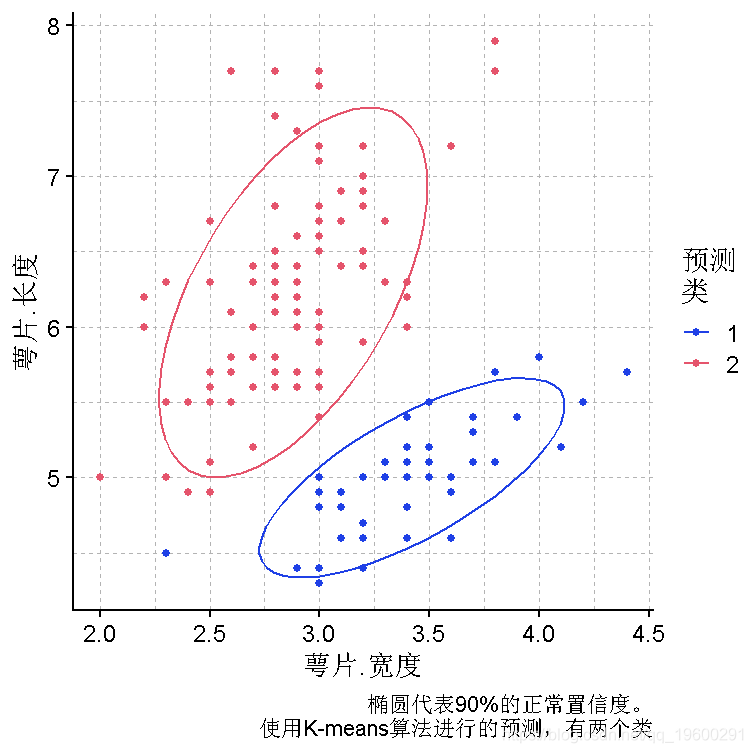
本文以iris数据和模拟数据为例,帮助客户比较R语言Kmeans聚类算法、PAM聚类算法、 DBSCAN聚类算法、 AGNES聚类算法、 FDP聚类算法、 PSO粒子群聚类算法在 iris数据结果可视化分析中的优缺点(点击文末“阅读原文”...
聚类分析(cluster analysis)是把研究对象(样本或变量)分组成为由类似的对象组成多个类的一种统计方法。聚类结果一般在4-6类,不易太多,或太少。聚类分析目的在于将相似的事物归类,同一类中的个体有较大的相似性,...
在网上(http://www.rdatamining.com/ )找到了一个用R语言进行聚类分析的例子, 在整个例子中做了一些中文解释说明. 数据集用的是iris第一步:对数据集进行初步统计分析检查数据的维度> dim(iris)[1] 150 5显示数据...
自然语言处理(NLP)是计算机科学和人工智能领域的一个重要分支,旨在让计算机理解、处理和生成人类语言。在现实生活中,NLP技术广泛应用于文本抽取、文本分类、情感分析、语义搜索等领域。本文将从实战案例的角度,...
1.背景介绍 ...在本文中,我们将探讨无监督学习中的模式识别技巧,从聚类分析到自然语言处理。 2.核心概念与联系 无监督学习中的模式识别技巧主要包括以下几个方面: 聚类分析:聚类分析是一种无...
数据中心化与标准化变换:scale函数 scale(x, center = TRUE, scale = TRUE) 其中x是样本构成的数据矩阵,center为逻辑变量,表示对数据进行中心化变换,scale也为逻辑变量,表示对数据进行中心化变换 ...
R语言画聚类分析树形图
标签: r语言
library(colorspace) require(amap, quietly=TRUE)
1.背景介绍 自然语言处理(NLP)是计算机科学与人工智能领域的一个分支,研究如何让计算机理解、...本文将介绍自然语言处理中的文本聚类与主题模型,以及如何实现高效的文本聚类与主题模型。 2.核心概念与联系 2.1...
聚类分析概述 聚类分析是一种无监督学习的方法,其目标是将数据集中的样本分成若干个互不相交的子集,使得同一子集中的样本尽可能相似,不同子集中的样本尽可能不同。聚类分析通常用于发现数据中的隐藏模式、群组...
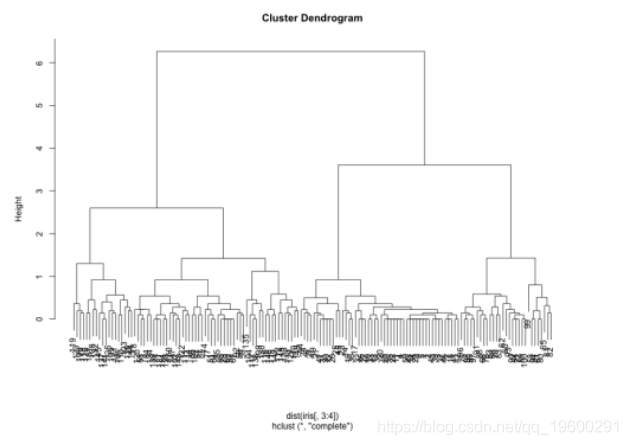
本文将介绍如何使用R语言中的hclust包进行层次聚类,并提供相应的源代码示例。层次聚类是一种强大的聚类方法,可以帮助我们发现数据集中样本之间的内在结构。通过使用R语言中的hclust包,我们可以轻松地实现层次聚类...
层次聚类算法的数学模型与应用 作者:禅与计算机程序设计艺术 1. 背景介绍 聚类是一种重要的无监督学习算法,在数据分析、图像处理、生物信息学等领域有广泛应用。其中,层次聚类(Hierarchical Clustering)是最常用的...
K-Means聚类算法原理与实践 作者:禅与计算机程序设计艺术 1. 背景介绍 在当今大数据时代,数据分析和挖掘已经成为各行各业不可或缺的重要手段。作为无监督学习算法中最为经典和广泛应用的聚类算法之一,K-Means算法因...
R语言Affinity Propagation+AP聚类实战 目录 R语言Affinity Propagation+AP聚类实战 #仿真数据 #AP(Affinity Propagation)AP聚类 #仿真数据 n = 100 g = 6 set.seed(g) d <- data.frame(x = unlist...
全文链接:http://tecdat.cn/?p=31948本文利用R语言的独立成分分析(ICA)、谱聚类(CS)和支持向量回归 SVR 模型帮助客户对商店销量进行预测(点击文末“阅读原文”获取完整代码数据)。首先,分别对商店销量的历史...
随着数据科学的发展,R语言因其强大的数据处理能力、丰富的数据分析库以及灵活的数据可视化工具而成为数据分析师的首选工具之一。理解和掌握如何在R语言中与数据库进行交互,对于进行高效的数据分析工作至关重要。...
聚类分析是一种无监督学习方法,用于识别数据中的模式和结构。在大规模数据集中,传统的聚类算法可能无法有效地处理数据,因此需要使用高性能的分布式计算框架,如Apache Spark。Spark MLlib库提供了一组用于聚类...
16.聚类分析 1.前言 聚类分析是一种数据规约技术,在与揭露一个数据集中观测值的子集,可以把大量的观测值规约为若干个类,而类即是被定义为若干个观测值组成的群组,组内相似度高于组间相似度,即是聚类.最常用...

至此,我们已经完成了R语言中层次聚类分析的基本步骤。通过使用不同的距离度量和聚类算法,我们可以探索数据集中的不同聚类结构,并从中获得有关数据的洞察。层次聚类是一种常用的聚类分析方法,用于将数据集中的...
R语言混合型数据聚类分析案例
标签: r语言
R语言数据分析案例,R语言混合型数据聚类分析案例,利⽤聚类分析,我们可以很容易地看清数据集中样本的分布情况。以往介绍聚类分析的⽂章中通常只介绍如何处理连续型变量,这些⽂字并没有过多地介绍如何处理混合型数据...
为了更好地理解这种差异,并为政策制定提供科学依据,本研究帮助客户采用了聚类分析和因子分析、主成分分析3种无监督学习方法,对多个省份的农业、林业、牧业、渔业以及农村居民家庭的相关经济指标进行了深入研究...
R语言做聚类分析Kmeans时确定类的个数

R语言中可以使用`hclust()`函数进行聚类分析,并使用`plot()`函数将聚类结果绘制成树状图。具体步骤如下: 1. 进行聚类分析,例如: ``` # 生成数据 set.seed(123) x (rnorm(20), nrow=5) # 计算距离矩阵 d (x) ...
在R中,我们可以将数据存储在一个数据框中,每一列代表一个特征参数,每一行代表一个样本(即菌株)。在上述代码中,我们首先从CSV文件中读取菌株数据,并提取我们感兴趣的特征参数列。完成聚类分析后,我们可以对...
在上述代码中,我们使用循环计算了2到10个聚类数下的轮廓系数,并将结果存储在silhouette_vec向量中。在图中,我们可以观察到轮廓宽度最大的位置,该位置对应于最佳的聚类数。上述代码中,我们使用循环计算了1到10个...
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地