Being a newbie in R, I'm not very sure how to choose the best number of clusters to do a k-means an
”r语言聚类“ 的搜索结果

自然语言处理(Natural Language Processing,NLP)是人工智能(AI)的一个重要领域,旨在使计算机能够理解、解释、操作人类语言。在当今信息爆炸的时代,NLP技术的应用越来越广泛,涵盖了文本分析、机器翻译、情感...
K均值聚类在智慧城市建设中的应用实践 作者:禅与计算机程序设计艺术 1. 背景介绍 随着城市化进程的不断加快,如何利用现有的城市资源,为城市居民提供更加优质的公共服务和生活环境,成为了当前城市管理者面临的重要...
作者简介Introductiontaoyan:伪码农,R语言爱好者,爱开源。个人博客: https://ytlogos.github.io/使用k-means聚类所需的包:factoextracluster #加载包library(factoextra)library(cluster)l #数据准备使用内置...
聚类的基础就是算出所有元素两两间的距离,我们首先做一些示例数据,如下:x=runif(10)y=runif(10)S=cbind(x,y) #得到2维的数组rownames(S)=paste(“Name”,1:10,””) #赋予名称,便于识别分类out.dist=dist(S,...
R语言在聚类分析与聚类模型中的应用
标签: 大数据
# 章节一:引言 聚类分析是一种常用的数据分析方法,它可以帮助我们发现数据中潜在的内在结构和模式,对数据进行分类和分组。...- 开源免费:R语言是开源免费的,用户可以在不花费额外成本的情况下使用和分享R语言。 -
聚类算法在图像处理中具有广泛的应用,主要用于图像的分割、分类和特征提取等方面。本文将从以下几个方面进行阐述: 背景介绍 核心概念与联系 核心算法原理和具体操作步骤以及数学模型公式详细讲解 具体代码实例和...

cereal<-read("cereal.DAT") cereal1<-cereal[,c(3,4,5,6,7,8,9,10)] cereal2=scale(cereal1[,-6]) x<-dist(cereal2,method="euclidean") plot(cs<-hclust(x,method="single"),hang=-1,main="Single"....
在本章中,我们将介绍聚类分析的基本概念和在教育与研究领域的应用意义,以及聚类散点图在评估聚类效果中的作用和重要性。让我们一起深入了解聚类分析的核心内容。 # 2. 数据准备与处理 在进行聚类分析之前,数据...

基于R语言构建K均值聚类模型K均值聚类是一种常用的无监督学习算法,用于将数据集划分为K个不同的类别。在本文中,我们将使用R语言构建一个K均值聚类模型,并演示如何应用该模型对数据进行聚类分析。
动态时间规整(DTW)是要找出两个时间序列之间的最优配置,R语言中的dtw包提供了动态时间规整的实现,在dtw包中,函数dtw(x,y,...)计算动态时间规整并找出时间序列x和y之间的最优配置,函数dtwDist(mx,my=mx,...)...
层次聚类在群体分析中的应用
标签: 大数据
层次聚类作为一种常用的无监督学习方法,被广泛应用于群体分析领域。 ## 研究意义 层次聚类可以将数据对象组织成树状结构,从而更好地理解数据间的关系和分布规律。在群体分析中,利用层次聚类能够帮助我们发现群体...
聚类分析是一种常用的数据挖掘技术,它通过对数据中的对象(如样本、数据点等)进行分组,将相似的对象归类到同一组,从而揭示数据中的隐含结构和模式。随着大数据时代的到来,聚类分析的应用范围不断扩大,其在各个...
全文链接:http://tecdat.cn/?p=32007本文以iris数据和模拟数据为例,帮助客户了比较R语言Kmeans聚类算法、PAM聚类算法、 DBSCAN聚类算法、 AGNES聚类算法、 FDP聚类算法、 PSO粒子群聚类算法在 iris数据结果可视化...
R语言中的聚类分析与案例实践
标签: 大数据
R语言中的聚类分析简介 ## 1.1 什么是聚类分析 聚类分析是一种基于数据相似性进行分组的方法,主要用于发现数据中的内在模式和结构。它通过将数据对象划分为若干个互相独立的类别或群组,使得同一类别内的对象...
聚类算法是一种常用的无监督学习方法,它可以根据数据点之间的相似性自动将它们分为不同的类别。向量内积是聚类算法中的一个基本操作,它可以用来计算两个向量之间的相似度。在本文中,我们将详细介绍向量内积和聚类...


R语言实现聚类算法和降维方法:深入探索数据结构聚类算法和降维方法是数据科学中常用的技术,可以帮助我们理解和分析复杂的数据结构。在本文中,我们将使用R语言来实现聚类算法和降维方法,并深入探索它们在数据分析...
前段时间做了一个有关聚类分析的项目,在进行结果验证时需要用到一些评价聚类方法性能的标准。其中无监督的验证方法包括轮廓系数(SC),戴维森堡丁指数(DBI)和Calinski-Harabaz(CH)。作者项目的代码是用R跑的,...
确定数据集中最佳的簇数是分区聚类(例如k均值聚类)中的一个基本问题,它要求用户指定要生成的簇数k。 一个简单且流行的解决方案包括检查使用分层聚类生成的树状图,以查看其是否暗示特定数量的聚类。不幸的是,...
R语言实现K-mean聚类并画出聚类图(非调用package)

R语言_判别分析_聚类分析_R语言实例分析_内附R代码_分析数据见资其它资源
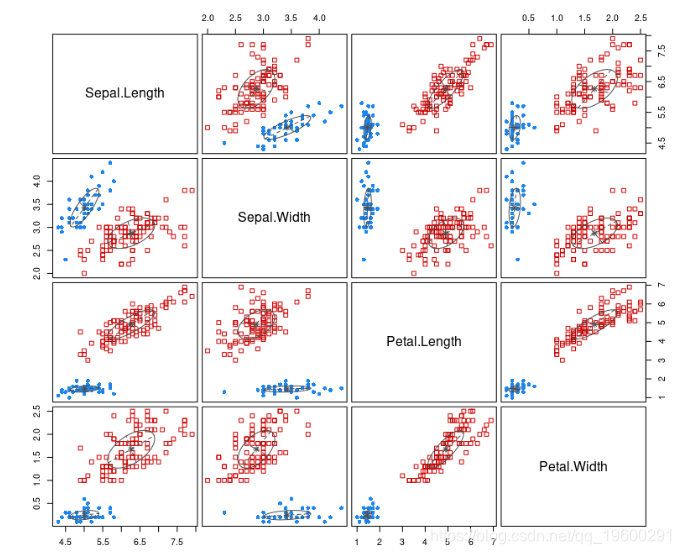
划分聚类是用于基于数据集的相似性将数据集分类为多个组的聚类方法。分区聚类,包括:K均值聚类(MacQueen 1967),其中每个聚类由属于聚类的数据点的中心或平均值表示。K-means方法对异常数据点和异常值敏感。K-...
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地