翻了很久GitHub 最推荐RapidOCRPDF 可识别纯图PDF 加密签名的PDF 重点是开源免费,准确程度比百度OCR高,缺点是不支持还原版面格式
”python读取扫描形成的pdf“ 的搜索结果
文字型pdf提取,python的库一大堆,但是图片型pdf和pdf扫描件提取,还是有些难度的,我们需要用到OCR(光学字符识别)功能。需要注意的是,Tesseract OCR对于一些复杂或低质量的图像可能识别效果不佳。
python烟花代码、Python实现烟花效果完整代码、Python实现烟花效果完整代码
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于...
本篇使用Python 实现读取pdf文件简单示例
这个问题在以前的堆栈溢出帖子中已经讨论过...程序适用于Windows上的Python3.6:# coding=utf-8# Extract jpg's from pdf's. Quick and dirty.import syswith open("Link/To/PDF/File.pdf", "rb") as file:pdf = fi...
使用python调用Nmap并处理返回结果.pdf
使用wand的时候有些pdf处理不了,会报图像出错的bug,那些wand处理的不了pdf几乎都是扫描的pdf。判断扫描的pdf可能是文字不清晰,也可能是格式问题。不容易处理。所以,想要把pdf转化为图片,然后再用ocr识别图片中...
Python中可以利用PyPDF2库来获取该pdf文件的总页码,可以根据下面的方法一步步进行下去:1、首先,要安装PyPDF2库,利用以下命令即可:pip install PyPDF22、接着,就是直接编写代码了,其中我新建了一个py文件,名...
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于...
python读取pdf文件


库进行学习,可以提前安装该库,不过有一点需要注意,该库主要用于读取 PDF 进行操作,写入和编辑无法实现,即本文学习一款专注于 PDF 内容提取的库。除了最后一项需要前端配合以外,其余内容都可以直接在 python 端...
文章目录概述扫描版PDF文字识别Tesseract OCR实现pdf文本识别tesseract-ocr安装与测试python实现基于tesseract的pdf文本识别百度 OCR实现pdf文本识别准备python实现基于百度OCR的pdf文本识别参考 概述 本文识别扫描...
以下是使用 PyPDF2 和 pytesseract 读取扫描件 PDF 文档的示例代码: ``` import PyPDF2 import pytesseract from PIL import Image pdf_file = open('scan.pdf', 'rb') pdf_reader = PyPDF2.PdfFileReader(pdf_...
以下是使用 PyPDF2 和 pytesseract 读取扫描件 PDF 文档的示例代码: ``` import PyPDF2 import pytesseract from PIL import Image pdf_file = open('scan.pdf', 'rb') pdf_reader = PyPDF2.PdfFileReader(pdf_...
需提前安装好pyzbar和opencv-python库(博主的电脑安装opencv-python库比较麻烦,但大部分都...#然后我们设置一个变量,来存放我们扫到的码的信息,我们每次扫描一遍都会要检测扫描到的码是不是之前扫描到的, # 如果没
前言 扫描件一直受大众青睐,任何纸质资料在扫描之后...别担心,Python帮你解决问题。 目录 前言 需求描述 分析 代码 tess_ocr(pdf_path, lang,first_page,last_page) writercsv(intxt,outcsv) compare_file
python读写Excel有xlwt和xlrd库,但是:xlwt只能写新的单元格,不能更新已写过的单元格;xlrd只能读已有内容的单元格,未写内容的单元格读不了。方案:用xlutils.copy库,可以实现写新的单元格,和更新新入已有内容...
目录虽然PDF文件对文本布局非常好,容易打印并阅读,但软件要将它们解析为纯文本并不容易,Python目前解析PDF的扩展包有很多,本文将分别介绍PyPDF2、pdfplumber、pdfminer3k以及Camelot(若发现还有其他函数,继续...
pdfplumber还可以获得页面上的所有单词、直线、方格、乃至曲线的位置信息,具体可以看看官网的说明:https://github.com/jsvine/pdfplumber。
快速高效地从PDF文档中提取信息对于专业人士来说非常重要。处理大量PDF文件时,将PDF转换为可编辑的文本格式可以节省时间和精力。...本文将展示如何使用Python进行PDF到文本的转换,发挥Python在PDF文件处理中的作用。
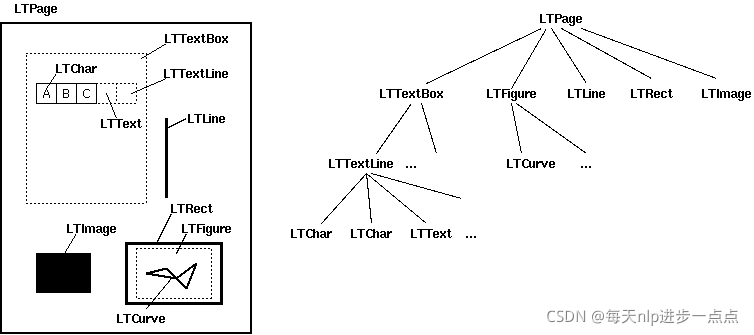
用python提取PDF中各类文本内容的方法
对于经常看扫描PDF资料的人来说,经常会碰到如下问题:PDF缩略图因为一些格式转换的原因,一些空白页时不时的出现,而且规律不定,一会是偶数页码一会是奇数页码,逐个选中删除的话,对于几百页的文档,非常费时。...
可用看到表格内容位置一致,转换完成。【转换后Excel】
http://www.jb51.net/article/89955.htmhttps://pythontips.com/2016/02/25/ocr-on-pdf-files-using-python/大家可能听说过使用Python进行OCR识别操作。在Python中,最出名的库便是Google所资助的tesseract。利用...
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地