无
”python爬虫多个url“ 的搜索结果
如果有多个URL等待我们爬取,我们通常是一次只能爬取一个,爬取效率低,异步爬虫可以提高爬取效率,可以一次多多个URL同时同时发起请求异步爬虫方式:一、多线程、多进程(不建议):可以为爬取阻塞(多个URL等待...
用 python编写的爬虫项目集合
1、为什么要使用多任务爬虫? 在大量的url需要请求时,单线程/单进程去爬取,速度太慢,此时cpu不工作,浪费cpu资源。 爬取与写入文件分离,可以规避io操作,增加爬取速度,充分利用cpu。 2、多任务分类 进程:...

在使用python爬虫进行网络页面爬取的过程中,第一步肯定是要爬取url,若是面对网页中很多url,,又该如何爬取所以url呢?本文介绍Python爬虫爬取网页中所有的url的三种实现方法:1、使用BeautifulSoup快速提取所有...
如何获取一个页面内所有URL链接?在Python中可以使用urllib对网页进行爬取,然后利用Beautiful Soup对爬取的页面进行解析,提取出所有的URL。 什么是Beautiful Soup? Beautiful Soup提供一些简单的、python式的函数...

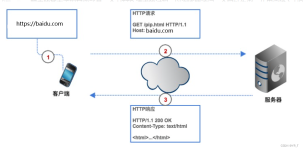
但是,按照常规的爬取方法是不可行的,因为数据是分页的:最关键的是,不管是第几页,浏览器地址栏都是不变的,所以每次爬虫只能爬取第一页数据。为了获取新数据的信息,点击F12,查看页面源代码,可以发现数据是...
小编把网页的第一篇内容抓取好了,但是用python怎么抓取后面的 又如何停止那天小编做了一个梦,在梦里他哭着抱着小编,对小编说,很抱歉没能好好爱小编。用爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发出...
python爬虫-翻页url不变网页的爬虫探究 url随着翻页改变的爬虫已经有非常多教程啦,这里主要记录一下我对翻页url不变网页的探究过程。 学术菜鸡第一次写CSDN,请大家多多包容~ 如果对你有一点点帮助,请帮我点个赞...
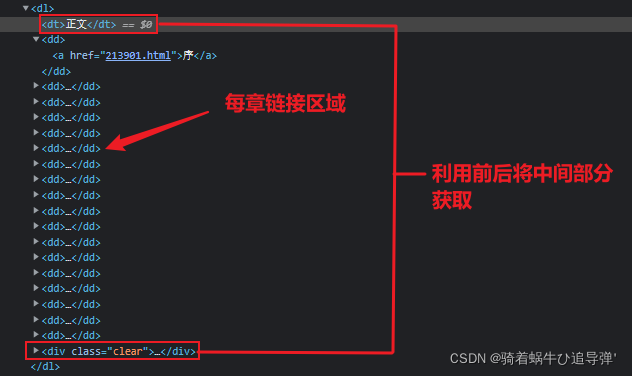


小编把网页的第一篇内容抓取好了,但是用python怎么抓取后面的 又如何停止那天小编做了一个梦,在梦里他哭着抱着小编,对小编说,很抱歉没能好好爱小编。用爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发出...
我相信很多人跟我都有相同的经历:想在网上找点资源,却因为种种原因而...有了 Python 爬虫技巧,相信很多平时你想要的资源,它都可以帮你实现。本文我将给大家分享目前做爬虫所涉及的 Python 库,总会一款是你的最爱。

通过这些案例的学习,读者可以更深入地理解Python爬虫的应用和技巧,为自己的爬虫项目提供更多思路和灵感。对于每个图片链接,我们发送GET请求获取图片的响应,并使用with open语句打开一个文件,将图片的内容写入...
相信各大高校应该都有本校APP或超级课程表之类的软件,在信息化的时代能快速收集/查询自己想要的咨询也是种很重要的能力,所以记下了这篇博客,用于总结我所学到的东西,以及用于记录我的第一个爬虫的初生。...
python爬虫100例教程 python爬虫实例100例子 涉及主要知识点: web是如何交互的 requests库的get、post函数的应用 response对象的相关函数,属性 python文件的打开,保存 代码中给出了注释,并且可以直接运行哦...
大家在日常生活中经常需要查找不同的事物的相关信息,今天我们利用python来实现这一个小功能,同时呢,也是大家对基础知识的一个综合实践,相信有不少小伙伴已经准备跃跃欲试了,话不多说,开干!urllib库是Python的...
这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载。 二、代码 __author__ = JentZhang import urllib.request ...
Python爬虫:通过url获得图片
标签: 爬虫
(一)爬虫使用场景主要分以下几类。


推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地