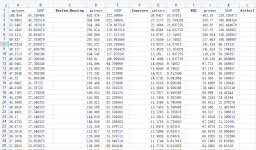
”pd.read_excel“ 的搜索结果
是 Pandas 库中用于读取 Excel 文件的函数,它可以读取 Excel 文件中的数据并将其转换为 Pandas 中的 DataFrame 格式,以方便进行数据处理和分析。
首先是pd.read_excel的参数:函数为: pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None, arse_cols=None,date_parser=None,na_values=None,thousands=None, convert_float=True...
在 Pandas 中,可以使用 read_excel() 函数读取 Excel 文件,使用 to_excel() 函数写入 Excel 文件,文章是它们的用法和常用参数的说明。
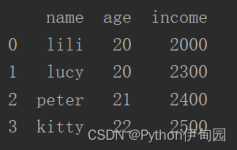
本文主要讲解Pandas中的read_excel()函数的相关知识点
除了使用xlrd库或者xlwt库进行对excel表格的操作读与写,而且pandas库同样支持...首先是pd.read_excel的参数:函数为: pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None, arse_
pd.read_excel出现XLRDError错误
除了使用xlrd库或者xlwt库进行对excel表格的操作读与写,而且...首先是pd.read_excel的参数:函数为:pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,arse_cols=None,date_parser...

人们经常用pandas处理表格型数据,时常需要读入excel表格数据,很多人一般都是直接这么用:pd.read_excel(“文件路径文件名”),再多一点的设置可能是转义一下路径中的斜杠,一旦原始的excel表不是很规整,这样简单...
详解pandas库pd.read_excel操作读取excel文件参数整理与实例来源:中文源码网浏览: 次日期:2019年11月5日详解pandas库pd.read_excel操作读取excel文件参数整理与实例除了使用xlrd库或者xlwt库进行对excel表格的...
pd.read_excel () 人们经常用pandas处理表格型数据,时常需要读入excel表格数据,很多人一般都是直接这么用: pd.read_excel (“文件路径文件名”), 再多一点的设置可能是转义一下路径中的斜杠,一旦原始的excel表...
第一次运行必须带上定义:import pandas...pd.read_excel(1) read_excel(io, sheet_name, header, names, index_col, parse_cols, usecols, squeeze, dtype, engine, converters, true_values, false_values, ski...


除了使用xlrd库或者xlwt库进行对excel表格的操作读与写,而且pandas库...首先是pd.read_excel的参数:函数为:pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,arse_cols=None,d...
写脚本,报错很正常,但总报些无厘头的错就让人很郁闷。上午大概花了三小时的时间做了个分类问题,但居然一半以上的时间都花在读取excel文件这一步了!...data= pd.ExcelFile(path1) df = data.parse(sh
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None, arse_cols=None,date_parser=None,na_values=None,thousands=None, convert_float=True,has_...
哈喽,大家好,我是木头左!今天,我要分享的是一个非常实用的Python技能,那就是如何在Python的pandas库中使用pd.read_excel函数来读取Excel文件的多个sheet页数据。

pd.read_excel(io, # 文件路径 sheetname=0, # 用于选取sheet表,默认是选取第一个sheet,即参数为0 header=0, # 表头,指定某一行作为列标签,默认是第一行,即参数为0 skiprows=None, # 跳过行,默认是无 index...
pandas.read_excel(io,sheet_name = 0,header = 0,names = None,index_col = None,usecols = None,squeeze = False,dtype = None, ...) io:字符串,文件的路径对象。 sheet_name:None、string、int、...
我目前正在使用read_excel访问我的excel文件,并通过引用列的第一个单元格对象(excel工作表中的列标题)为工作表中的每一列分配了变量。现在这一切都很好,我已经能够通过引用我分配的变量来对每列中的数据进行排序。...
可以用来修改某一列读取的参数类型,一般在数据读取的时候,读到某一列全部是数据,会默认把该列的数据类型定义为int类型,但是,如果遇到数据是0开头的,就会出现问题,因此,可以使用dtype来定义某一列的数据类型...
pd.read_excel(path, skiprows, nrows, header) 参数解析: path:表示路径 header:指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header=None; skiprows:省略指定行数...
最近在学《Python数据分析与挖掘实战》,按照书上例子实践,发现有问题,记录如下import pandas as pdcatering_sale = 'C:\Python\learning\3\catering_sale.xls' #餐饮数据data = pd.read_excel(catering_sale, ...
pd.read_excel
标签: python
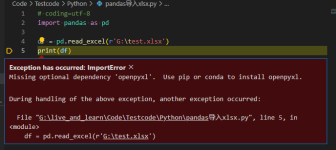
df1 = pd.read_excel(path_in1, engine='openpyxl', usecols=['标注', '标题', '摘要'], na_values=' ', keep_default_na=False) 或者读取之后再处理 df2 = pd.read_excel(path_in2, engine='openpyxl', usecols=['...
pd.read_excel()
推荐文章
- 手写一个SpringMVC框架(有助于理解springMVC) 侵立删_springmvc可以用来写安卓后端吗-程序员宅基地
- 线性判别分析LDA((公式推导+举例应用))_lda推导-程序员宅基地
- C# 结构体(Struct)精讲_c# struct-程序员宅基地
- 支付宝Wap支付你了解多少?_阿里wap支付-程序员宅基地
- Java计算器编写,实现循环输入_java简易计算器可使用户多次输入-程序员宅基地
- 【多维Dij+DP】牛客小白月赛75 D-程序员宅基地
- Android之内存优化与OOM-程序员宅基地
- Azure Machine Learning - 视频AI技术_azure ai 視頻索引器-程序员宅基地
- 个人知识管理软件使用感受-程序员宅基地
- WWDC2019 ------深入理解App启动_wwdc app启动-程序员宅基地