本文简单介绍一下read_csv()和 to_...一.pd.read_csv() 作用:将csv文件读入并转化为数据框形式。 pd.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecol...
”pd.read_csv“ 的搜索结果
在读取.csv时发现会产生第一行默认为标签的问题,导致出现下图情况 这是因为pd.read_csv,读取数据时...df1 = pd.read_csv(r'/home/LX/DNN_XGB/Dataset/csv/AAC_N1.csv', header=None)#读取第一个文件 ...
pandas.read_csv 详细介绍 《Pandas 教程》 修订中,可作为 Pandas 入门进阶课程、Pandas 中文手册、用法大全,配有案例讲解和速查手册。提供建议、纠错、催更等加作者微信: sinbam 和关注公众号「盖若」ID: gairuo...
这里将更新最新的最全面的read_csv()函数功能以及参数介绍,参考资料来源于官网。 目录pandas库简介csv文件格式简介函数介绍函数原型函数参数以及含义输入返回函数使用实例 pandas库简介 官方网站里详细说明了pandas...

在学习pandas对文件导入导出时出现错误 拷贝过来的路径是用 " \ " 此时只需将其搞成 " / " 错误就消失了
pd.read_csv用法、及重要参数
当header列数小于数据实际列数时,pd.read_csv()读取后从右向左依次对应数据和header,数据左侧出现了以‘/’为分隔的堆积(xx、11111、114、49应分别是站名、站号、经度和纬度)。 情况2: 当header列数大于数据...
在pandas模块中,读取CSV文件主要使用pd.read_csv()函数。 必选参数:要读取的CSV文件的文件路径 常用的可选参数: 1.指定行索引:index_col 2.获取指定列:usecols 3.添加columns:header=None和names
关于pd.read_csv() 读数据的注意事项 实验数据:adult.data 编译环境:pycharm 代码编写:Sublime Text3 ① import pandas as pd #加载数据 df = pd.read_csv( '.\\adult.data' )#请将adult.data和当前.py...
pd.read_csv时出现unnamed列 出现unnamed列的原因 之所以会出现unnamed列,是因为我们把DataFrame写入到excel或者csv文件时,把索引也作为一列写入。 解决办法 在写入数据时参数index设置为False,即index=False ...
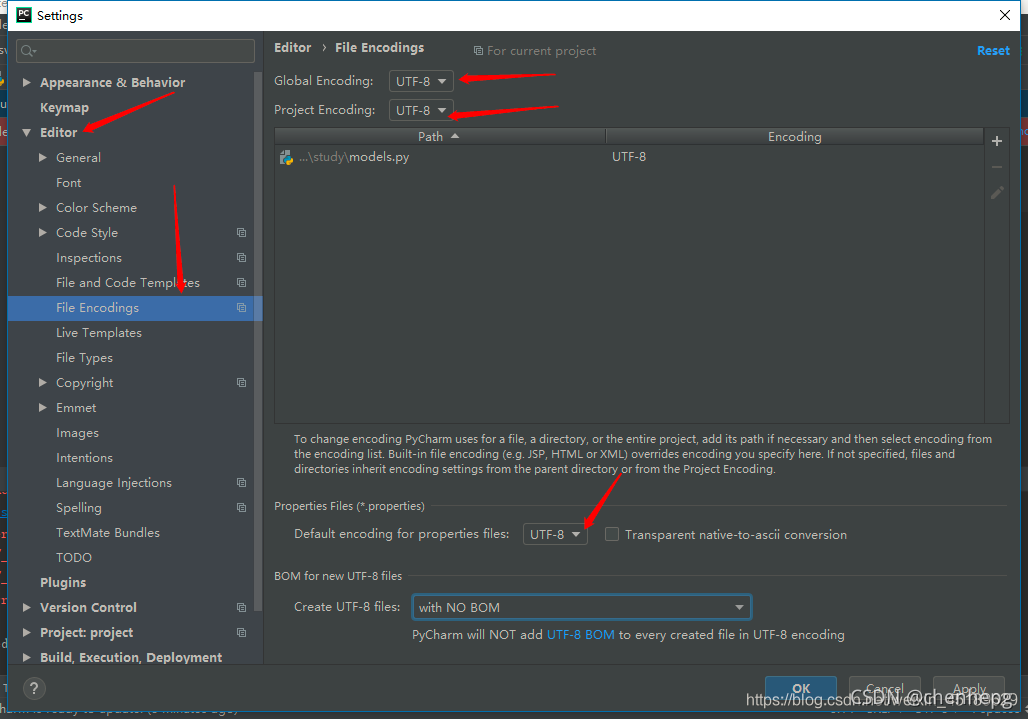
在使用pd.read_csv()读取表格数据时,有"encoding="参数用来描述表格数据采用的编码方式,比较常用的有utf-8,但有时候还是会报错。示例如下: import pandas as pd file_path = "oracle_log.csv" data = pd.read_...
利用pd.read_csv读取文件加载时,默认会将文件中缺失的数据自动填充为NaN,如果想指定缺失数据的填充值,则可以利用里面的na_values参数。 import pandas as pd data=pd.read_csv("./selectRefer10PerClass0317.txt...
pd.read_csv()读取文件失败,路径错误 原因 在windows系统当中读取文件路径可以使用\ ,但是在python字符串中\有转义的含义,如\t可代表TAB,\n代表换行,所以我们需要采取一些方式使得\不被解读为转义字符。 解决...
利用pandas的read_csv常规读入CSV数据。...df=pd.read_csv(path,encoding='utf8',low_memory=False) 报错: 卸载pandas,重装pandas。 再次读取数据,仍报错: 网上查找资料有几个解决方法: 1.把当前路...
import pandas as pd ''' with open("numbers.txt","w") as file_object: a = 1 b = 11 for i in range(10): for j in range(a,b): file_object.write(str(j) + " ") a += 10 b += 10 file_o
将csv中的时间字符串转换成日期格式 1、准备数据 TestTime.csv文件: "name","time","date" 'Bob',21:33:30,2019-10-10 'Jerry',21:30:15,2019-10-10 'Tom',21:25:30,2019-10-10 'Vince',21:20:10,2019-10-10 'Hank'...

pd.read_csv参数详解 转自:pandas.read_csv参数详解 - 李旭sam - 博客园 参数:filepath_or_buffer :str,pathlib。str, pathlib.Path, py._path.local.LocalPath or any object with a read() method (such as a ...
data = pd.read_csv(path) Traceback (most recent call last): File "C:/Users/arron/PycharmProjects/ML/ML/test.py", line 45, in data = pd.read_csv(path) File "C:\Users\arron\AppData\Local\Continuum\...

方法一: df = pd.read_csv('1.csv', engine='')
csv格式说明: CSV文件是一个纯文本文件,最早用在简单的数据库里,其格式简单,具备很强的开放性,非常容易被导入各种PC表格及数据库,比如Excel表格等。 CSV文件中每行相当于一条记录(相当于数据表中的一行),用...
我有一个.csv文件,它有数百行/列,看起来像这样(小例子,请参阅图片,我无法复制/粘贴空字节必须手动键入它们):9142,16.04000000,14.65000000<0x00><0x00><0x00>9143,16.19000000,14.65000000在...
我们在读取csv文件的时候,有的时候可能没有表头,或者想换一个表头,该怎么操作? df = pd.read_csv('data.csv', sep='\t',header=None, names=['var_code','var_name','var_desc'])```
pd.read_csv()用于读取csv文件。CSV (Comma Separated Vaules) 格式是电子表格和数据库中最常见的输入、输出文件格式。
df = pd.read_csv('0728.csv',sep=',') df 如上图所示,有时候直接读取文件,会多出一些空白列。为了去掉这些空白列,我们可以用usecols参,确定好要读取的列数,直接加参即可。 list_a = np.arange(12) df = pd....
解决方法: data=pd.read_csv(‘dermatology.data’,header=None) 即将header这一项设置为’None’. 之后在excel打开时,显示表头是顺序数字
推荐文章
- 用好ASP.NET 2.0的URL映射-程序员宅基地
- C语言等级考试是把题目删了,历年全国计算机的等级考试二级C语言上机考试地训练题目库及答案详解(72页)-原创力文档...-程序员宅基地
- Microsoft Office显示正在更新无法打开的问题_正在更新microsoft 365和office-程序员宅基地
- 非常好的Ansible入门教程(超简单)-程序员宅基地
- 【Gradle-8】Gradle插件开发指南-程序员宅基地
- 使用PL/SQL Developer软件解锁_plsqldev表格锁怎么打开-程序员宅基地
- 【Windows Server 2019】Web服务 IIS 配置与管理——配置 IIS 进阶版 Ⅳ_iis默认路径-程序员宅基地
- 网络中的各层协议_发送消息时各层协议-程序员宅基地
- UCRT: VC 2015 Universal CRT, by Microsoft_vc15rt-程序员宅基地
- 关于EntityFramework 7 开发学习_entiry framework 7 书籍-程序员宅基地