用MapReduce实现KMeans算法,数据的读写都是在HDFS上进行的,在伪分布下运行没有问题。文档中有具体说明。
”kmeans“ 的搜索结果
文章目录1.实验目的2.导入必要模块3.用pandas处理数据4.拟合+预测5.把预测结果合并到DF6.可视化聚类效果7....from sklearn.cluster import KMeans #从sklearn导入KMeans算法 import pandas as pd from sklearn.pr
此函数将 n×p 数据矩阵“X”中的点划分为 k 个簇。
SparkKmeans 毕业设计源码-基于Spark的Kmeans聚类算法优化时间:2016-07-18内容: 发布内容到Github。 (2)ML聚类程序:利用Spark的机器学习库的聚类函数进行聚类测试。(3)MD聚类程序: (4)数据库操作程序:
基于Python3.7实现KMeans++算法,并用于实现图像分割功能。包括源程序、测试图片、结果图片和运行步骤。
智能算法对传统聚类算法的优化,亲测可用
Kmeans.zip
标签: c#
人工智能 Kmeans算法实现的源代码
kmeans_waveform_Kmeans_python_Waveform_kmeansuci_waveform数据集_源码.zip
针对图像数据噪声大和高维稀疏的特点,提出了一种基于噪声过滤和 Info-Kmeans 聚类的图像索引构建方 法。首先,利用余弦兴趣模式过滤噪声。其次,提出了一种新的Info-Kmeans聚类算法,该算法不仅避免KL-...
主要介绍了python Kmeans算法深入解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
KMeans.rar
标签: 配送中心选址
对Kmeans算法进行了改进,使改进后配送中心的选址更加的优化。主函数中调用的数据需要自己根据实际情况添加,数据添加成功后可以直接运行。
该程序可以实现利用粒子群算法对K-MEANS算法进行优化
程序为m脚本文件,里面使用了4维数据进行了聚类,并进行数据展示,质心展示。
mapreduce-kmeans 代码。 请注意,这只是一个示例,而不是可用于生产的代码。 如果您要进行正式生产和正常工作的群集,请使用Mahout,Hama或Spark。 建造 您将需要Java 8来构建该库。 您可以简单地使用以下命令...

【代码】【基于Kmeans、Kmeans++和二分K均值算法的图像分割】数据挖掘实验三。
主要介绍了Python实现的KMeans聚类算法,结合实例形式较为详细的分析了KMeans聚类算法概念、原理、定义及使用相关操作技巧,需要的朋友可以参考下
基于Kmeans聚类算法对银行客户进行分类数据集是一个在金融行业广泛应用的数据挖掘技术。Kmeans算法是一种无监督学习方法,能够自动地将数据集中的对象划分为K个不同的聚类,每个聚类内的对象具有相似的特性。在银行...
python实现kmeans聚类算法的源码(下载即用).zippython实现kmeans聚类算法的源码(下载即用).zippython实现kmeans聚类算法的源码(下载即用).zippython实现kmeans聚类算法的源码(下载即用).zippython实现kmeans...
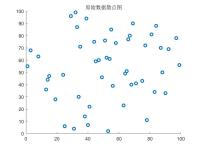
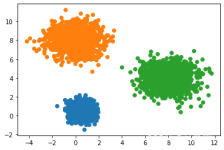
kmeans聚类算法 算法原理 kmeans的算法原理其实很简单 我用一个最简单的二维散点图来做解释 如上图,我们直观的看到该图可聚成两个分类,我们分别用红点和蓝点表示 下面我们模拟一下Kmeans是怎么对原始的二维散点...
K均值 KMeans 算法的 Map Reduce 实现。 该程序在单/多节点 Hadoop 集群上运行,并在 AMazon Elastic Map Reduce 多节点集群上进行了测试。

在线KMeans 在我在帕特雷大学计算机工程和信息学系学习的最后一年中,完成了我的硕士论文项目的实施部分,该项目的标题为“ Apache Flink上的分布式流处理系统的回顾和Streaming K-Means的实现”,希腊。 执行要求 ...
YOLOv3聚类分析之kmeans,yolov3多目标检测,生成自己的锚框,并显示准确性分布图,亲测有效
Kmeans聚类问题实例
标签: 机器学习
kmeans 聚类问题实例,用kmeans聚类算法将数据分成三类,实现三分类问题,并将分类结果进行储存
KMeans算法是一种常用的无监督学习算法,用于将数据集分成K个簇或类别。并行和分布式的KMeans算法针对大规模数据集提供了高效的实现方式。并行化可以加速算法的计算过程,而分布式实现则可以处理更大规模的数据集。 ...

推荐文章
- Codeforces-学校排队-程序员宅基地
- 计算机毕业设计ssm基于JAVA的图书馆自习室座位预约系统194fd9 (附源码)轻松不求人_基于ssm的图书馆预约座位-程序员宅基地
- 实值复变函数求导 ——(Wirtinger derivatives)_wirtinger导数-程序员宅基地
- VMWare虚拟机设置固定IP上网方法_vm虚拟机只允许指定ip访问-程序员宅基地
- 深度学习修炼(一)线性分类器 | 权值理解、支撑向量机损失、梯度下降算法通俗理解-程序员宅基地
- 基于SpringBoot的社区团购APP+02043(免费领源码)可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案-程序员宅基地
- 如何在无公网IP环境下远程访问Serv-U FTP服务器共享文件-程序员宅基地
- uniapp的navigateTo页面跳转参数传递问题_uni.navigateto刷新携带参数丢失-程序员宅基地
- C++中std::getline()函数的用法-程序员宅基地
- vue 工作中的一些小总结(基础知识供刚入门的小伙伴看 vue+elementUi+vsCode+vue-router+iconfont )_mac+elementui+vscode-程序员宅基地