
”java读parquet文件乱码“ 的搜索结果
场景描述:公司埋点项目,数据从接口服务写入kafka集群,再从kafka集群消费写入HDFS文件系统,最后通过Hive进行查询输出。这其中存在一个问题就是:埋点接口中的数据字段是变化,后续会有少量字段添加进来。这导致...
放到mysql中存储,mysql中默认表被创建的时候用的是默认的字符集(latin1),所以会出现中文乱码。(2)修改hive-site.xml中Hive读取元数据的编码(注意原先是否配置过)注意的是,之前创建的表的元数据已经损坏了,...
hive学习的记录


大数据知识详解

CDH6.3.2集群部署
标签: cdh
CDH 6.3.2 组件版本 Component Component Version Apache Avro 1.8.2 Apache Flume 1.9.0 Apache Hadoop 3.0.0 Apache HBase 2.1.4 HBase Indexer 1.5 Apache Hive ... K
Nebula Graph图数据库的介绍、部署、数据导入、Supervisor进程守护Nebula Graph、部署Nebula Graph遇到的问题等




下面是上周你的 CSDN 社交圈的总结: 我关注的人中, 在过去一周点赞最多的博客是: 排名标题点赞数1 从idea中复制配置文件到外部或提交到svn中文乱码解决 1 2 ubuntu22.04安装deepin-wine报错:The following ...


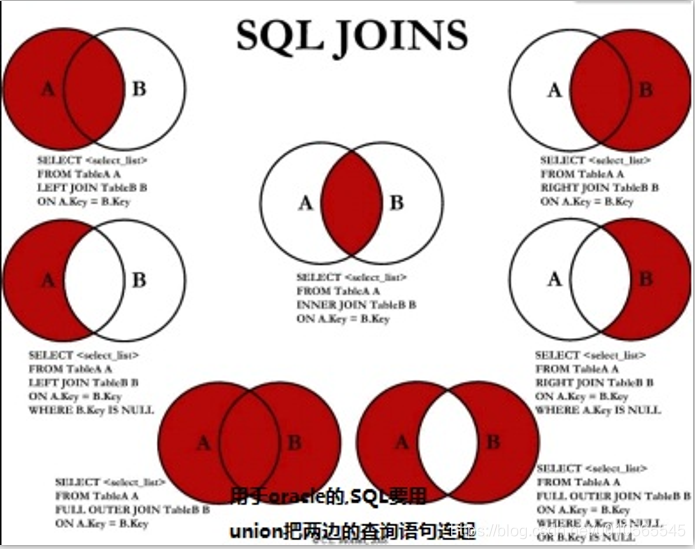


Flink学习-HDFSConnector(StreamingFileSink) Flink系列文章 ... ... ...本文主要介绍Flink中的DataStream之HDFSConnector(StreamingFileSink),包含概念介绍、源码解读、实际Demo,已经更新到最新的Flink 1.10。...
Hive教程-详细全部
标签: hive



Flink学习-DataStream-HDFSConnector(StreamingFileSink) 摘要 本文主要介绍Flink1.9中的DataStream之HDFSConnector(StreamingFileSink),大部分内容翻译、整理自官网。以后有实际demo会更新。...



方法一,Spark中使用toDF函数创建DataFrame 通过导入(importing)Spark sql implicits, 就可以将本地序列(seq), 数组或者RDD转为DataFrame。只要这些数据的内容能指定数据类型即可。需要注意spark和scala的版本,否则...
文章目录1 前言2 硬件检测与配置优化2.1 磁盘挂载2.1.1 磁盘大小低于2T2.1.2 磁盘大小大于2T2.2 内存查看2.3 cpu检查2.4 网卡检查2.5 ntp同步3 os参数优化4 CDH参数优化4.1 hdfs4.2 yarn5 平台迁移模拟5.1 停止5.2 ...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地