hive版本为2.1.1-cdh6.2.0,下载地址hive-2.1.1-cdh6.2.0问题在orc格式的表中,一些列中存储的是中文,进行select查询时,偶尔会乱码如下所示:MapReduce Jobs Launched:Stage-Stage-1: Map: 1 Cumulative CPU: 3.45...
”java读parquet文件乱码“ 的搜索结果
注:图来自info官网[slave01:... create table ml_123 (a int,b varchar(10)) STORED AS PARQUET ;Query: create table ml_123 (a int,b varchar(10)) STORED AS PARQUETFetched 0 row(s) in 0.07s[slave01:21000]...
java使用Parquet
标签: parquet
java使用Parquet
Hive在储存时间戳的时候会先把时间转成UTC的时间,然后再把转换后的时间存储到Parquet文件中。在读取Parquet文件的时候Hive会把时间从UTC时间再转化回成本地的时间。这样的话,如果存和读取都是用Hive的话,时间不会...

parquet文件本质是json文件的压缩版,这样不仅大幅度减少了其大小,而且是压缩过的,比较安全一点,spark的安装包里面提供了一个例子,在这个路径下有一个parquet文件: spark-2.0.1-bin-hadoop2.7/examples/src/...
本篇文章主要介绍了java 读写Parquet格式的数据的示例代码,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
import org.apache.spark.SparkConfimport org.apache.spark.SparkContextimport org.apache.spark.sql.SQLContextobject startScala {def main(args: Array[String]): Unit ={val conf = new SparkConf().setAppNam...
就发现了Hudi有一个Bootstrap功能,但是一直没用过,通过官网文档可知,它可以将现有的表件转化为Hudi表,而且有两种类型和,但是文档并不详细,比如这两种类型的区别具体是啥,支持哪些文件类型的源表。于是带着这些...
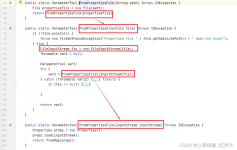

Python的json文件读取及解决中文乱码显示问题本文实例讲述了Python实现的json文件读取及中文乱码显示问题解决方法。分享给大家供大家参考,具体如下:city.json文件的内容如下:{"cities": [{"city&...
一直是大数据集群老生常谈的问题,今天就一起聊聊最基本的大数据文件存储格式的区别对比,尤其是Hive建表的时候需要选择文件存储格式最为常用,而为什么单独拎出来说RC, ORC,Parquet文件呢?是因为这三者是当今Hive...
SparkSQL的数据源可以是JSON类型的字符串,JDBC,Parquent,Hive,HDFS等。 SparkSQL底层架构 ...1、读取json格式的文件创建DataFrame //json文件中的json数据不能嵌套json格式数据。 //DataFrame是一个一个Ro
Flink-StreaimingFileSink-自定义序列化-Parquet批量压缩 1 Maven依赖 Flink有内置方法可用于为Avro数据创建Parquet writer factory。 要使用ParquetBulkEncoder,需要添加以下Maven依赖: <dependency> <...
最近在做sqoop导入oracle数据到hive字符集乱码问题,虽然没有解决,但是现在将一些尝试的过程发布,供大家参考,以后有遇到这种问题的供大家参考少走弯路。oracle里面的字符集是us7ascii,导入到hive里面后中文乱码...
1、pom依赖 <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.1.1.3.1.4.0-315</version>...
本文讲如何用spark读取gz类型的压缩文件,以及如何解决我遇到的各种问题。 1、文件压缩 下面这一部分摘自Spark快速大数据分析: 在大数据工作中,我们经常需要对数据进行压缩以节省存储空间和网络传输开销...
dataframe转成spark dataframe存储到hive表,发生中文乱码
1. 学会使用默认数据源; 2. 学会手动指定数据源; 3. 理解数据写入模式; 4. 掌握分区自动推断
一、数据类型 1、基本数据类型 Hive 支持关系型数据中大多数基本数据类型 类型 描述 示例 boolean true/false TRUE tinyint 1字节的有符号整数 -128~127 1Y smallint ... dou
原文地址:...----------------------------------------------------------------------------- 最近在使用hive时,需要将hive查询的数据导出到本地文件系统,HQL语法如下: INSERT OVE
Paimon目前支持Flink 1.17, 1.16, 1.15 和 1.14。本课程使用Flink 1.17.0。环境准备1)上传并解压Flink安装包tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/2)配置环境变量sudo vim /etc/profile.d/my...
1. 数据源1:JDBC 1.1 使用load方法连接JDBC读取数据 ...import java.util.Properties import org.apache.log4j.{Level, Logger} import org.apache.spark.sql._ /** * JDBC 数据源 */ object JDB...
Spark使用Java读取mysql数据和保存数据到mysql一、pom.xml二、spark代码2.1 Java方式2.2 Scala方式三、写入数据到mysql中部分博文原文信息 一、pom.xml <?xml version="1.0" encoding="UTF-8"?> <project ...
最近在做sqoop导入oracle数据到hive字符集乱码问题,虽然没有解决,但是现在将一些尝试的过程发布,供大家参考,以后有遇到这种问题的供大家参考少走弯路。oracle里面的字符集是us7ascii,导入到hive里面后中文乱码...
文章目录一、java模块面试问题1.动态代理2.浏览器禁用Cookie后的Session处理3.主从复制的流程[重要]5.redis的数据类型[重要]6.Junit测试的注解7、缓存问题二、项目中java模块的难点异常[重要]1.MultipartiFile图片从...
一、数据类型1、基本数据类型Hive 支持关系型数据中大多数基本数据类型类型描述示例booleantrue/falseTRUEtinyint1字节的有符号整数-128~127 1Ysmallint2个字节的有符号整数,-32768~327671Sint4个字节的带符号整数1...
本文主要以Kettle概述、Kettle开发环境部署、mac m1 kettle安装、linux kettle安装、kettle集群安装部署、kettle输入、kettle输出、kettle转换、kettle批量加载、kettle流程、kettle脚本、kettle的Java代码案例、...
字符集中文乱码转换为UTF8,如:å\u0085¬è¯\u0081ä¸\u009Aå\u008A¡ç±»å\u0088«æ\u009C\u0089误ï¼\u0081。
推荐文章
- 回调函数使用详解_回调函数的用法-程序员宅基地
- [STM32F0xx]的AD转换驱动程序_stm32f0xx adc_in-程序员宅基地
- 优秀的程序员都热爱写作_程序员写作-程序员宅基地
- 为什么加深神经网络如此有效?从卷积滤波器解释_卷积深度变深什么作用-程序员宅基地
- Android Studio 混淆_android studio 开启混淆-程序员宅基地
- 专业学位计算机技术排名,山东师范大学计算机技术(专业学位)专业考研难度分析-专业排名-难度大小...-程序员宅基地
- idea配置tomcat环境_idea的tomcat,连接不显示explore-程序员宅基地
- 说说内核与计算机硬件结构-程序员宅基地
- 数据结构应用案例——栈结构用于8皇后问题的回溯求解-程序员宅基地
- c语言scanf中的分隔符的作用,C语言中scanf与分隔符(空格回车Tab)-程序员宅基地