本文基于vgg-16、inception_v3、resnet_v1_50模型进行fine-tune,完成一个二分类模型的训练。 目录 一、环境准备 二、准备数据 三、数据解析及图片预处理 四、模型定义 五、模型训练 六、模型预测 最后:...
”inception_v3图片预处理“ 的搜索结果
keras的inception_v3是个图片进行分类模型,使用keras简单调用内置的inception_v3模型非常简单,只需要一行代码: #导入所需要的库 import tensorflow as tf from tensorflow.keras.preprocessing import image from...
使用keras框架,对Inception-v3模型进行迁移学习,处理caltech256数据集的图像分类问题,现附上可执行代码,与大家分享。数据需要自己进行预处理,分为训练集和验证集。迭代次数都需要自行设定。提供train learning ...

在这个模型中,主要用到两个模块:ImageDataGenerator和inception_v3,前者是用于对图片数据做预处理,后者是inception网络的api。不得不说,keras提供的接口真心强大。 1.ImageDataGenerator的功能和参数 这个...
还对Xception模型和Inception模型进行了比较。 这是使用卷积神经网络和一种递归神经网络(LSTM)为所有类型的图像生成标题和替代文本的最简单方法。关于图像特征将从在imagenet数据集上训练的CNN模型中提取(请参见...
在训练神经网络模型时,往往需要很多的标注数据以支持模型的准确性。但是,在真实的应用中,很难收集到如此多的标注数据,即使可以收集到,也需要花费大量的人力物力。而且即使有海量的数据用于训练,也需要很多...
Inception_v3输入图像大小为299x299,而不是特征向量大小。特征向量的大小取决于预处理过程和网络的结构。通常,Inception_v3的最后一个池化层会生成一个8x8x2048大小的特征向量。

1. flower数据集 ... 共五种花的图片 2. 图片处理 ...将图片划分为train、val、test三个子集并提取图片特征。这个过程有点儿漫长请耐心等待。。。。。。 import glob import os.path import numpy a...
总结来说,Inception v3是一种深度卷积神经网络,其主要特点包括更深的网络结构、使用Factorized Convolutions、添加Batch Normalization、引入辅助分类器以及使用基于RMSProp的优化器进行训练。相对于Inception v1...
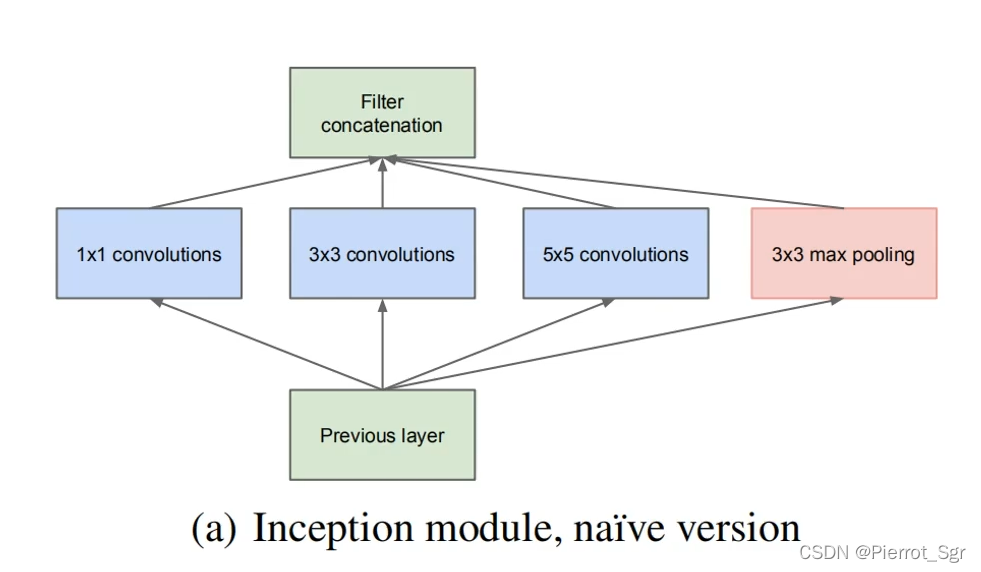
一、Inception V1 二、Inception V2 提升网络性能最直接的办法就是增加网络深度和宽度,深度指网络层次数量、宽度指神经元数量。但这种方式存在以下问题: (1)参数太多,如果训练数据集有限,很容易产生过拟合;...
导入函数库 import tensorflow as tf import numpy as np import tensorflow_datasets as tfds # 这个是指Tensorflow Datasets import matplotlib.pyplot as plt 定义网络结构 一些参数设置 layers = tf.keras....
文章目录CNN神经网络的演化过程GoogLeNet原始版本GoogLeNet Inception V1GoogLeNet Inception V2GoogLeNet Inception V3GoogLeNet Inception V4 CNN神经网络的演化过程 Hubel&Wiesel | Neocognitron | LeCun...
【翻译自 : create-your-own-image-caption-generator-using-keras】 【说明:analyticsvidhya这里的文章个人很喜欢,所以闲暇时间里会做一点翻译和学习实践的工作,这里是相应工作的实践记录,希望能帮到有需要...
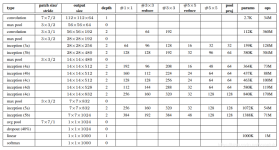
1.背景 自1998年LeNet-5模型的提出一直到现在,卷积神经网络模型的层数和复杂度都发生了巨大的变化,下表中罗列了ILSVRC(Lareg Scale Visual Recognition Challenge)第一名模型的表现: 年份 ...
# -*- coding:utf-8 -*- import glob # 文件名匹配包 import os.path # 获取文件属性包 import numpy as np import tensorflow as tf from tensorflow.python.platform import gfile # 提供一个操作文件的API ...

论文:《Rethinking the Inception Architecture for Computer Vision》 论文链接:https://arxiv.org/abs/1512.00567 tensorflow.keras.applications模块内置了许多模型,包括Xception、MobileNet、VGG等,我们可以...
我们需要在预训练的InceptionV3模型之上构建一个自定义的分类模型。# 将预训练模型的所有层设为不可训练# 获取预训练模型的 'mixed7' 层(InceptionV3中的一层)# 添加一个平铺层,将特征图展平为一维向量# 添加一个...
导入必要模块 import os import numpy as np import torch.nn as nn import torch from torch.utils.data import DataLoader import torchvision.transforms as transforms import torch.optim as optim ...


model = inception_v3.InceptionV3(weights='imagenet',include_top=False) ``` 使用 Keras 库中的 InceptionV3 模型对图像进行处理。`weights='imagenet'` 表示使用预训练的权重,`include_top=False` 表示去掉...

inception-v3模型:google图像识别的网络模型 1. 在线下载模型代码: import tensorflow as tf import os import tarfile import requests # inception-v3 是googlenet的第三个版本 #inception模型下载地址 ...
Inception_v3对输入的图像进行预处理 输入: x float32 的 numpy.array 或者 tf.Tensor data_format default 或者 none 输出: float32 的 array 或者 tensor,值域在 -1 ~ 1 间 ...
推荐文章
- 【解决报错】java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)-程序员宅基地
- echart y轴显示小数或整数_echarts y轴显示16位小数-程序员宅基地
- Android客户端和Internet的交互_android与internet-程序员宅基地
- linux新建分区步骤_linux创建基本分区的步骤-程序员宅基地
- 信号处理-小波变换4-DWT离散小波变换概念及离散小波变换实现滤波_dwt离散小波变换进行滤波-程序员宅基地
- Ubuntu 10.10中成功安装ns-allinone-2.34_进入/home/ubuntu1/ns-allinone-2.34目录cd /home/ubuntu1-程序员宅基地
- 使用AES算法对字符串进行加解密_java 判断aes加密 与否-程序员宅基地
- DFS深度优先搜索(前序、中序、后序遍历)非递归标准模板_深度优先搜索 无递归-程序员宅基地
- 程序员面试字节跳动,被怼了~_字节跳动java什么技术站-程序员宅基地
- 嵌入式软考备考(五)安全性基础知识-程序员宅基地