
”hive相关问题“ 的搜索结果
hive常见的优化方案ppt
标签: hive
涉及到Hive优化相关的一些常用技巧,当Hive出现数据倾斜时或者负载不均衡等情况,往往会出现耗久,甚至跑不出结果的尴尬场面,这个时候如果计算资源监控显示有没有完全饱和利用,就需要涉及到优化了;



基于SpringBoot+hive...主要针对计算机相关专业的正在做毕设的学生和需要项目实战的大数据可视化、Java学习者。 也可作为课程设计、期末大作业。包含:项目源码、项目说明等,该项目可以直接作为毕设、课程设计使用。

Hive是什么? Hive是构建在hadoop之上的数据仓库 Hive是一个基于hadoop的数据仓库,可以通过类似于SQL语句来进行对数据的读写管理(元数据)等操作 Hive定义了一种类似于SQL的查询语言,叫做HQL类似于SQL,但是不完全...
一般 Hive 的元数据信息都存储在 MySQL 中,但 MySQL 数据库中的。进入 MySQL 中调整下列参数,切换到存储 Hive 元数据信息的库,然后执行。在 Hive 中创建一个新表,并添加注释信息。,所以会造成 Hive 中注释出现...
问题遇到的现象和发生背景 在window启动hive 问题相关代码,请勿粘贴截图 启动hive 运行结果及报错内容 D:\ideaworks\apache-hive-2.3.0-bin\bin>hive SLF4J: Class path contains multiple SLF4J bindings....
Hive相关jar-附件资源
Hive和Spark
标签: hive
1. Hive简介 hive的定位是数据仓库,其提供了通过 sql 读写和管理分布式存储中的大规模的数据,即 hive即负责数据的存储和管理(其实依赖的是底层的hdfs文件系统或s3等对象存储系统),也负责通过 sql来处理和分析...
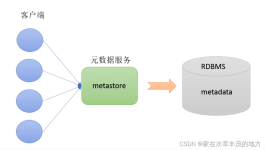
Hive架构 客户端提交SQL作业到HiveServer2,HiveServer2会根据用户提交的SQL作业及数据库中现有的元数据信息生成一份可供计算引擎执行的计划。每个执行计划对应若干MapReduce作业,Hive会将所有的MapReduce作业都...

Hive概述
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。Hive是基于Hadoop的一个数据仓库工具,将结构化的数据文件映射为一张表,并提供类SQL(HQL)查询功能。1)用户接口:ClientJDBC/ODBC(jdbc访问hive)、2)...
Linux虚拟机Hive基本安装详细步骤。虚拟机中为什么要安装hive。hive是什么?
Hive的小文件问题
一、SQL本身的优化 1、只select需要的列,避免select * 2、where条件写在子查询中,先过滤...Hive.mapred.mode,分 nonstrict,strict,默认是nonstrict, 如果设置为strict,对三种情况限制: (1)分区表必须加分区。
hive1.2.2版本和hbase1.0.2的通信包,重新封装的,也进行了相关代码的删除和部分修改
hive优化


1、下载pyhive、thrift和sasl三个包(pip install就好)2、目前遇到的问题: sasl安装问题:(1)sasl安装需要到相关网站下载whl之后找到和python适配的版本进行安装,安装网址:https://www.lfd.uci.edu/~gohlke/...
Hive表操作

例如:业务库的手机号、身份证等敏感信息在落入数仓表前都需要进行加密后再进行存储;特定场景下业务人员会再将加密后的敏感信息进行解密后进行分析。会存在加密后数据变为空值,或者解密后数据变为空值的情况。...
推荐文章
- Ubuntu/linux下下载工具_ubuntu下载软件助手 linux版本-程序员宅基地
- HTML、JSP前端页面国际化(i18n)_html全局国际化-程序员宅基地
- Python高级-08-正则表达式_写出能够匹配只有下划线和数字还有字母组成(且第一个字符必须为字母)的163邮箱(@1-程序员宅基地
- 寻仙手游维护公告服务器停服更新,寻仙手游2月1日停服更新公告 2月1日更新了什么...-程序员宅基地
- 用python自动预约图书馆座位_微信图书馆座位秒抢脚本-程序员宅基地
- Android真机或模拟器激活Xposed框架的方法_de.robv.android.xposed.installer-程序员宅基地
- 操作系统为什么要分用户态和内核态_用户态和内核态都需要cpu参与,为什么要区分-程序员宅基地
- 01—JVM与Java体系结构(简单介绍)_01_jvm与java体系结构.pptx-程序员宅基地
- 国有建筑企业数字化转型整体解决方案_建筑企业数字化转型行动方案-程序员宅基地
- 性能测试的软件------loadrunner_loadrunner有有三个图标,-程序员宅基地