Hive相关jar-附件资源
”hive相关问题“ 的搜索结果

windows下安装hive2.3.x 需要cmd文件,解压覆盖bin目录即可。原本想免积分的,没有这个选项,愿资源槛低一点,学习更容易一点。
一、小文件产生原因 ...hive 中的小文件肯定是向 hive 表中导入数据时产生,所以先看下向 hive 中导入数据的几种方式 1.直接向表中插入数据 insert into table A values (1,'zhangsan',88),(2,'lisi',61);
对应sasl.whl 包 : sasl‑0.3.1‑cp39‑cp39‑win_amd64...-- 存储元数据mysql相关配置 -->访问地址:http://ip:10002/-- H2S运行绑定host -->-- 关闭元数据存储授权 -->Thrift最小工作线程数。Thrift最大工作线程数。
调研 [2]中只是解决了显示问题 [3]中解决了无法触发水印计算的问题. ###############################################... 引入相关的pom 构造hive catalog 创建hive表 将流数据插入hive,
Hive 配置动态分区 insert into table xxx partition(xxxx) select ... 使用动态分区时首先需要的一些配置: 是否开启动态分区 hive.exec.dynamic.partition 动态分区是否使用严格模式 hive.exec.dynamic....
jdbc2hive特征支持将hive查询中的DB相关条件推送到MySQL 支持仅获取 MySQL 中的必填字段以优化性能支持分场运行多图使用 MySQL 解释估计获取的行现在只支持 MySQL用法建造 $ git clone $ mvn clean -Dmaven.test....
java代码执行hive相关ktr时报错: database type with plugin id [HIVE2] couldn't be found! 解决:kettle-core-7.1.0.0-12.jar适配hive后的包。具体步骤请查看...
job.splitmetainfo该文件记录split的元数据信息,如input文件过多,记录的文件结构信息超出默认设置就会报错;或者将此值设置的更大:set mapreduce.job.split.metainfo.maxsize=20000000。分析:hadoop参数重...
hive 操作相关的测试数据集hive

本文关键字:Hive、远程连接、MetaStore、JDBC、SparkSQL。在进行开发时,我们通常需要能够在代码中访问Hive进行查询,此时我们要做一些配置和修改。第一种方式是直接开启一个hiveserver2的Hive服务端,用来提供执行...
数据倾斜是进行大数据计算时常见的问题。主要分为map端倾斜和reduce端倾斜,map端倾斜主要是因为输入文件大小不均匀导致,reduce端主要是partition不均匀导致。在hive中遇到数据倾斜的解决办法:一、倾斜原因:map端...
处理压缩文件
Hive Metastore、Hive server和Hive thrift服务介绍

hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为...
kettle执行hive相关ktr时报错
有关可与camus2hive一起使用的Hive表定义的示例,请参见create_table文件。 另外,您也可以让脚本自动创建和更新Hive表,但这需要您具有可用的架构存储库。 请参阅和,以获取有关如何获取适当的架构存储库的更多...
2、使用spark/flink实时写hive时,根据业务的时间窗口(10s,20s)落地hive表,产生很多小文件。 3、采用动态分区也会产生很多小文件。 4、reduce的个数输出。默认reduce个数和落地hive文件个数一样。 小文件带来...
主要介绍了详解hbase与hive数据同步的相关资料,需要的朋友可以参考下
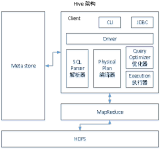
我们将传统数据库的应用迁移到Hive如果有事务相关的场景我们该如何去转换并要注意什么问题呢?本文会通过很多真实测试案例来比较Hive与传统数据库事务的区别,并在文末给出一些在Hive平台上使用事务相关的功能时的...

Hive查询问题(卡住)
标签: hive
一、现象 几乎全部SQL语句都不能查,卡死在那里,过很久之后可能会报 FAILED: Error in acquiring locks: Error communicating with the ...2、考虑是hive元数据的问题 查看hive元数据表的使用情况 show OPEN
问题语句 select app_name,count(1) as cnt from ( select name,seq_id from tmp.data_20220418 group by name ,seq_id ) a group by app_name limit 10; 当我在spark去运行这个语句时加不加limit 结果是...
利用 jdbc 连接hive需要的相关jar包 一共17个

推荐文章
- Ubuntu/linux下下载工具_ubuntu下载软件助手 linux版本-程序员宅基地
- HTML、JSP前端页面国际化(i18n)_html全局国际化-程序员宅基地
- Python高级-08-正则表达式_写出能够匹配只有下划线和数字还有字母组成(且第一个字符必须为字母)的163邮箱(@1-程序员宅基地
- 寻仙手游维护公告服务器停服更新,寻仙手游2月1日停服更新公告 2月1日更新了什么...-程序员宅基地
- 用python自动预约图书馆座位_微信图书馆座位秒抢脚本-程序员宅基地
- Android真机或模拟器激活Xposed框架的方法_de.robv.android.xposed.installer-程序员宅基地
- 操作系统为什么要分用户态和内核态_用户态和内核态都需要cpu参与,为什么要区分-程序员宅基地
- 01—JVM与Java体系结构(简单介绍)_01_jvm与java体系结构.pptx-程序员宅基地
- 国有建筑企业数字化转型整体解决方案_建筑企业数字化转型行动方案-程序员宅基地
- 性能测试的软件------loadrunner_loadrunner有有三个图标,-程序员宅基地