”hive相关问题“ 的搜索结果
2. Hive 的版本选择问题 3. sort/distribute/cluster by order by 全局排序,大规模数据集效率低 Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序 distribute by 在...
hive相关jar包,连接大数据hive所用jar包,最新3.1.1版本
1)Hive数据倾斜问题: 倾斜原因: map输出数据按Key Hash分配到reduce中,由于key分布不均匀、或者业务数据本身的特点。】【等原因造成的reduce上的数据量差异过大。 1.1)key分布不均匀 1.2)业务数据本身的特性 1.3)...

4 Hive 表相关语句 3 4.1 Hive 建表: 3 4.1.1使用LIKE关键字创建一个与已有表模式相同的新表: 4 4.2 Hive 修改表 4 4.2.1 Hive 新增一个字段: 4 4.2.2 Hive 修改字段名/字段类型/字段位置/字段注释: 4 4.2.3 ...
HIVE相关的jar包
标签: hive jar
HIVE相关jar包,各个版本,抵制那些动不动就大几十积分的资源 .
kettle 连接hive导数: 先将hive/lib里面的关于hive的jar包全部导入到kettle/中hdp25目录中的Lib库里 配置修改: plugin.properties属性值修改: # here see the config.properties file in that configuration's ...
1.1 问题描述 Caused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPAT....
Windows环境下启动hive,执行.\bin\hive,报错 'hive' 不是内部或外部命令,也...Apache Hive后续较新版本bin目录下缺少Windows环境下所需要的cmd相关命令。 Apache-Hive-2.1.1老版本bin目录包含所需文件,提供下载。
02、hive-exec-2.1.1-cdh6.3.1.jar 03、hive-jdbc-2.1.1-cdh6.3.1.jar 04、hive-jdbc-2.1.1-cdh6.3.1-standalone.jar 05、hive-metastore-2.1.1-cdh6.3.1.jar 06、hive-service-2.1.1-cdh6.3.1.jar 07、libfb303-...
Hive JDBC连接示例该项目展示了如何使用各种不同的方法连接到Hiveserver2。 所有类仅适用于Hiveserver2。 正在使用Cloudera JDBC驱动程序,可以从下载。 在撰写本文时,最新版本为v2.5.... 有关更多信息,请参阅下载的z
CDH6针对hive on spark的调优文档,这个是生产的实战经验
Flink写入hive
hive旅游-hive旅游系统-hive旅游系统源码-hive旅游管理系统-hive旅游管理系统java代码-hive旅游系统设计与实现-基于springboot的hive旅游系统-基于Web的hive旅游系统设计与实现-hive旅游网站-hive旅游网站代码-hive...
Hive新增字段相关问题
标签: hive
Hive新增字段导致旧分区新增数据新增字段展示异常。
hive中文编码问题
hadoop、hbase、hive等相关面试题目。
DBeaver连接Hive的Jar包,通过Java JDBC连接Hive同样可以使用。 DBeaver连接Hive的Jar包,通过Java JDBC连接Hive同样可以使用。
hive旅游-hive旅游系统-hive旅游系统源码-hive旅游管理系统-hive旅游管理系统java代码-hive旅游系统设计与实现-基于springboot的hive旅游系统-基于Web的hive旅游系统设计与实现-hive旅游网站-hive旅游网站代码-hive...
只需要一个jar包,不需要大量的hadoop相关jar包
hive-exec-2.1.1 是 Apache Hive 的一部分,特别是与 Hive 的执行引擎相关的组件。Apache Hive 是一个构建在 Hadoop 之上的数据仓库基础设施,它允许用户以 SQL(结构化查询语言)的形式查询和管理大型数据集。Hive ...
hive小文件过多问题解决方法
hive权限问题,1.给某个用户授权grantselectondatabaseffcs_chenytouserffcs_cheny;2.ddlStatement:(createDatabaseStatement|switchDatabaseStatement|dropDatabaseStatement|createTableStatement|dropTable...
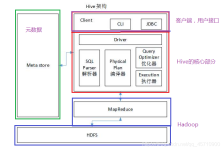
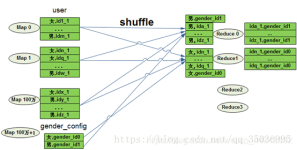
数据倾斜是进行大数据计算时常见的问题。主要分为map端倾斜和reduce端倾斜,map端倾斜主要是因为输入文件大小不均匀导致,reduce端主要是partition不均匀导致。
1.Hive failed; error='Cannot allocate memory' (errno=12) 2.hive-ls: 无法访问/opt/apps/spark-2.2.0/lib/spark-assembly-*.jar: 没有那个文件或目录 3.hive和presto的求数组长度函数区别(hive&cardinality)
hive分区表生成组件主要是通过获取数据集及数据集item的code,数据集code作为hive表名,数据集item code作为hive分区表字段,同时加入相关字段,形成hive表的基本结构。项目结构─src ├─main │ ├─java │ │ └...
文章目录Hive安装配置一、Hive安装地址二、Hive安装部署1. 把 `apache-hive-3.1.2-bin.tar.gz`上传到Linux的/export/software目录下2. 解压`apache-hive-3.1.2-bin.tar.gz`到/export/servers/目录下面3. 修改`apache...
推荐文章
- 记录CentOS7 Linux下安装MySQL8_适合正式环境_干货满满(超详细,默认开启了开机自启动,设置表名忽略大小写,提供详细配置,创建非root专属远程连接用户)_centos7安装mysql8-程序员宅基地
- python 读取grib \grib2-程序员宅基地
- Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!-程序员宅基地
- Datawhale-集成学习-学习笔记Day4-Adaboost-程序员宅基地
- TexStudio配置以及解决无法Build&View_texstudio 无法启动 build & view:pdflatex:"d:/data/texl-程序员宅基地
- 用户空间访问I2C设备驱动-程序员宅基地
- 人脸识别算法初次了解-程序员宅基地
- maven的pom文件学习-程序员宅基地
- wamp mysql 没有启动,WAMP中mysql服务突然无法启动 解决方法-程序员宅基地
- 《树莓派Python编程入门与实战(第2版)》——3.7 创建Python脚本-程序员宅基地