”hive“ 的搜索结果
文章目录Hive安装配置一、Hive安装地址二、Hive安装部署1. 把 `apache-hive-3.1.2-bin.tar.gz`上传到Linux的/export/software目录下2. 解压`apache-hive-3.1.2-bin.tar.gz`到/export/servers/目录下面3. 修改`apache...
driver = "org.apache.hive.jdbc.HiveDriver" user = "hive" password = "hive" table = ods_wjw_jb_gxy_hz_glk query = "select a,b,c from ods_wjw_jb_gxy_hz_glk" fetch_size = 300 } }

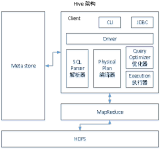
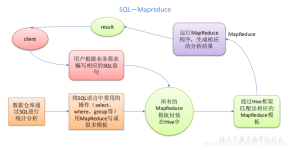
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的...
Hive DML
标签: hdfs hive iv
Hive不支持update的操作。数据一旦导入,则不可修改。要么drop掉整个表,要么建立新的表,导入新的数据。 load:加载数据到表 load data [local] inpath ‘filepath’ overwrite | into table 表名 [partition ...
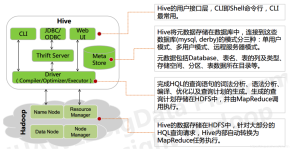
Hive是一个基于Apache Hadoop的数据仓库。对于数据存储与处理,Hadoop提供了主要的扩展和容错能力。 Hive设计的初衷是:对于大量的数据,使得数据汇总,查询和分析更加简单。它提供了SQL,允许用户更加简单地进行...
Hive 提供了一个让大家可以使用sql去查询数据的途径。让大家可以在hadoop上写sql语句。但是最好不要拿Hive进行实时的查询。因为Hive的实现原理是把sql语句转化为多个Map Reduce任务所以Hive非常慢,官方文档说Hive ...
Hive基本概念 是一个基于hadoop的数据仓库工具,可以将结构化数据映射成一张数据表,并提供类SQL的查询功能。 Hive的意义是什么 背景:hadoop是个好东西,但是学习难度大,成本高,坡度陡。 意义(目的)...

hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为...
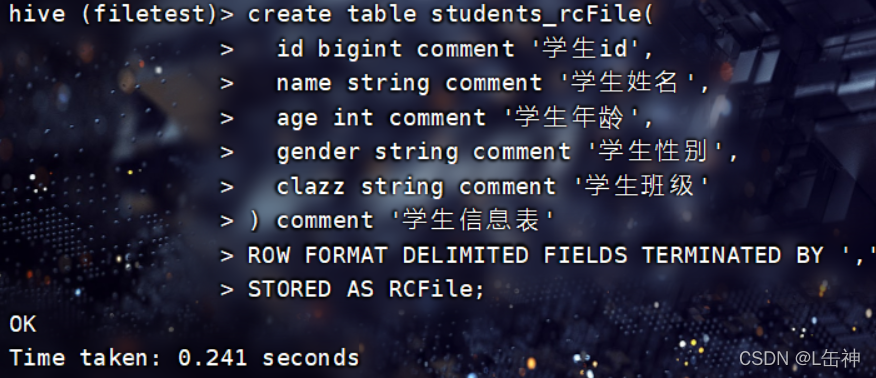
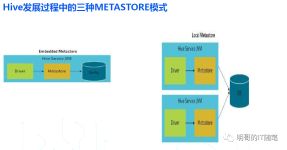
Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名。可以发现,自动连接MySQL去创建schema hive,并...
Hive:启动Hive
问题遇到的现象和发生背景 在window启动hive 问题相关代码,请勿粘贴截图 启动hive 运行结果及报错内容 D:\ideaworks\apache-hive-2.3.0-bin\bin>hive SLF4J: Class path contains multiple SLF4J bindings....
jdbc连接hive数据库的jar包.整理可用合集.
技术连载系列,前面内容请参考前面连载9内容:Hive底层数据存储在HDFS中,HQL执行默认会转换成MR执行在Yarn中,当HDFS配置了Kerberos安全认证时,只对HDFS进行认证是不够的,因为Hive作为数据仓库基础...
hive入门以及dbeaver连接hive
大数据分析利器之hive 一、环境准备 安装好对应版本的hadoop集群 安装mysql服务 二、知识要点 1. Hive是什么(40分钟) 1.1 hive的概念 Hive:由Facebook开源,用于解决海量结构化日志的数据统计。 Hive是基于...
由于Hive是一个基于Hadoop分布式文件系统的数据仓库架构,主要运行在 Hadoop分布式环境下,因此,需要在文件hive-env.sh中指定Hadoop相关配置文件的路径,用于Hive访问HDFS(读取fs.defaultFS属性值)和 MapReduce...
首先,将 xlsx 文件中的数据导出为 CSV 格式,这样更方便后续处理。...执行上述命令后,Hive 将会将 CSV 文件中的数据加载到指定的表中。在 Hive 中创建一个新表,用于存储导入的数据。表来验证数据是否成功导入。





推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地