该文件为百度网盘地址
”hadoop������������������“ 的搜索结果

环境:CentOS5、Hadoop0.20.203、jdk1.6.0_29 namenode:centos1(ip:192.168.1.101) datanode:centos2(ip:192.168.1.103)、centos3(ip:192.168.1.104) 配置步骤: (1)配置NameNode和DataNode 修改每台机器的/...
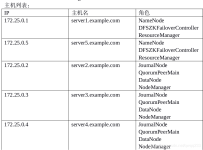
软件环境:Java 1.7.0_45、hadoop-1.2.1 1、 集群拓扑图 我们使用4台机器来搭建Hadoop完全分布式环境,4台机器的拓扑图如下图所示: Hadoop集群中每个节点的角色如下表所示: 2、 配置SSH 环境准备 ...
安装前准备jdk安装java -versionjava version "1.8.0_181"Java(TM) SE Runtime Environment (build 1.8.0_181-b13)Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)如果没有安装, 建议安装Java8...
为了完成Hadoop中没有的数据类型,需要自己创建一个。类似与C语言中的“自定义结构体”。 设置需要建立的成员变量,设定相应的变量类型。 需要编写一个空的构造函数。一个带参数的构造函数,使用this给变量进行赋值...
原文请见

© 2014作者。由爱思唯尔公司出版信息工程研究院负责评选和同行评议可在...Hadoop是一个开源的MapReduce实现,被大量用户广泛使用。它提供了一个抽象的环境,运行大规模的数据密集型应用程序在一个可扩展的和容错的方式
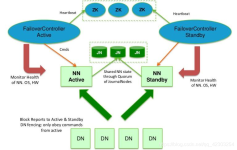
Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 &ZooKeeper 集群的安装部署的基础之上进行Hadoop 高可用(HA)的自动容灾配置 Hadoop 高可用 High ...
写在前面的话 Hdfs采用分布式架构,为...从2008年hadoop-0.10.1版本开始到现在的hadoop-3.0.0-beta1,hdfs已经走过了近10个年头,其架构和功能特性也发生了巨大的变化。特别是hdfs3.0.0系列,和hdfs2.x相比,增加了基
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,支持密集型分布式应用并以Apache2.0许可协议发布。 Hadoop:以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesystem)和MapReduce...
1在安装hadoop集群是对hadoop进行初始化设置(hadoop namenode-format),会自动生成Fsimage; 2操作服务器时产生的日志会保存到日志管理系统中 3在操作是一边往fsimage写数据,一边记录日志 4定期将fsimage序列化到本地...
声明:以下内容是复制前辈的文章,查看原文这里 有耐心的往下看。。。 ...1、Hadoop生态系统概况(看这个图,就大概知道各个模块是做什么的) ...Hadoop是一个能够对大量数据进行分布式处理的软件框架...下图为hadoop的
Hadoop分为两大块:HDFS和MapReduce HDFS是一个分布式存储文件系统,Mapreduce是一个分布式计算的框架,两者结合起来,就可以很容易做一些分布式处理任务了。 一 安装JDK1.7 Linux会自带JDK,如果不使用自带...
1、 所需安装包 CentOS-7-x86_64-DVD-1908.iso VMware-workstation-full-15.1.0-13591040.exe FileZilla_3.43.0_win64_sponsored-setup.exe...hadoop-2.7.3 scala-2.12.1 spark-2.3.0-bin-hadoop2.7 2、修改主机名 ...
版权所有© 2014作者.出版社:Elsevier B.V.信息工程研究院负责评选和同行评议可在...Hadoop是一个开源的MapReduce实现,被大量用户广泛使用。它提供了一个抽象的环境,运行大规模的数据密集型应用程序在一
MapReduce计算模型改进,刘长征,李威兵,文主要针对社交网站中海量图 片管理的特点,通过采用Hadoop技术来实现海量图片信息的分布式存储,并且根据社交网站中图片信息数据��
1. 创建hadoop用户组和用户 a. 创建hadoop用户组 sudo addgroup hadoop b. 创建hadoop用户 sudo adduser –ingroup hadoop hadoop c. 编辑/etc/sudoers文件,为hadoop用户添加权限 ...
随着科技的发展,各个领域对图像处理要求越来越高,算法也越来越复杂,处理时间也会延长。...本文则利用Hadoop与OpenCV搭建集群化的图像处理平台,使图像的处理速度得到大幅度的提升。 1 相关技术
一、环境准备 1.服务器选择 本地虚拟机 操作系统:linux CentOS 7 Cpu:2核 内存:2G 硬盘:40G 具体教程和使用可参考一下博文。 地址: http://blog.csdn.net/qazwsxpcm/article/details/78816230...Hadoop:2.6.0 ...
HDFS的namenode的HA搭建,准备好机器hadoop01 IP:192.168.216.203 GATEWAY:192.168.216.2 hadoop02 IP:192.168.216.204 GATEWAY:192.168.216.2 hadoop03 IP:192.168.216.205 GATEWAY:192.168...
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它...
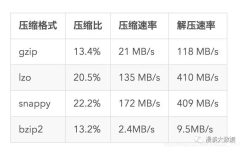
Hadoop总结 谁说大象不能跳舞,大象能跳舞啊!!!!不过跳起来是笨重的、、、、、、 概述 Hadoop 是一个性能、可靠性、可扩展性、可管理性的软件,为以后的分布式打下了基础,接下来咱们好好的深刨一下...
推荐文章
- 记录CentOS7 Linux下安装MySQL8_适合正式环境_干货满满(超详细,默认开启了开机自启动,设置表名忽略大小写,提供详细配置,创建非root专属远程连接用户)_centos7安装mysql8-程序员宅基地
- python 读取grib \grib2-程序员宅基地
- Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!-程序员宅基地
- Datawhale-集成学习-学习笔记Day4-Adaboost-程序员宅基地
- TexStudio配置以及解决无法Build&View_texstudio 无法启动 build & view:pdflatex:"d:/data/texl-程序员宅基地
- 用户空间访问I2C设备驱动-程序员宅基地
- 人脸识别算法初次了解-程序员宅基地
- maven的pom文件学习-程序员宅基地
- wamp mysql 没有启动,WAMP中mysql服务突然无法启动 解决方法-程序员宅基地
- 《树莓派Python编程入门与实战(第2版)》——3.7 创建Python脚本-程序员宅基地