云计算中数据存储的研究,郭耀华,杨俊,本文对Hadoop平台中的HDFS(Hadoop Distributed File System)件系统进行了分析和总结,并指出了HDFS文件系统可能存在的一些不足,比如单一名字�
”hadoop������������“ 的搜索结果
Caused by: com.mysql.cj.exceptions.InvalidConnectionAttributeException: The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone. You must configure either...
一见2010.1.6www.hadoopor.com/[email protected]. 安装JDK不...MapReduce程序的编写和Hadoop的编译都依赖于JDK,光JRE是不够的。JRE下载地址:http://www.java.com/zh_CN/download/manual.jspJDK下载地址:ht...
基于HDFS的大规模监控视频的细粒度检索,方瑞,李文生,Hadoop分布式文件系统(HDFS)被广泛用于存储大规模监控视频,然而目前并没有基于HDFS的监控视频细粒度检索方法。在本文中,我们借鉴�
手机阅读平台仓库管理模块的设计与实现,周鹤,朱晓民,针对手机阅读数据仓库计算和存储的特点,设计并实现了符合手机阅读基地Hadoop Hive数据仓库自身特点的数据仓库管理系统,保证数据信�
本文在《Hadoop2.0的安装和基本配置》(见http://www.linuxidc.com/Linux/2014-05/101173.htm)一文的基础上继续介绍hadoop2.0 QJM(Quorum Journal Manager)方式的HA的配置(hadoop2.0架构,具体版本是hadoop2.2.0...
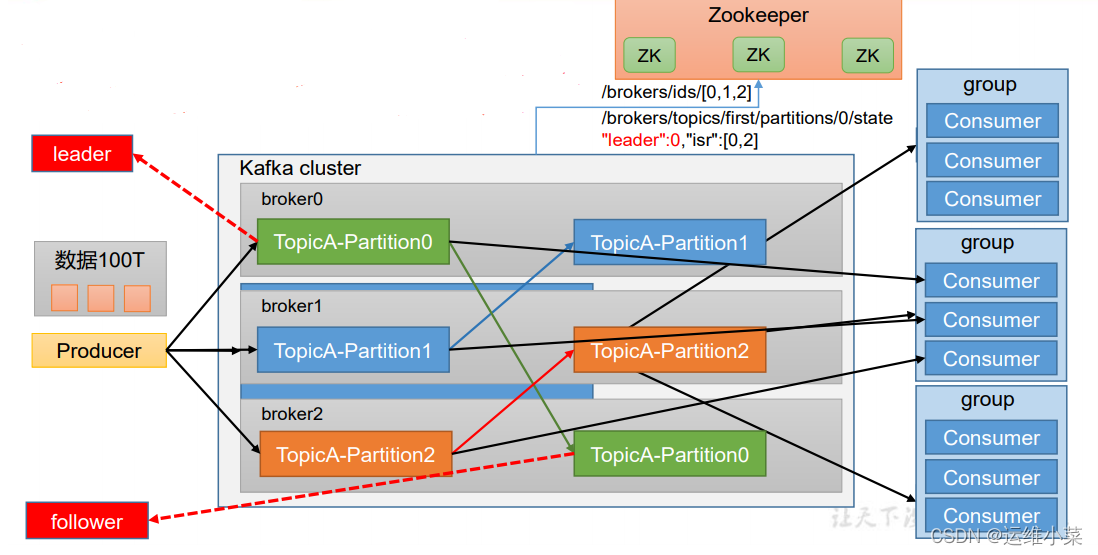
系列几篇文章中介绍了分布式存储和计算系统Hadoop以及Hadoop集群的搭建、Zookeeper集群搭建、HBase分布式部署等。当Hadoop集群的数量达到1000+时,集群自身的信息将会大量增加。Apache开发出一个开源的数据收集和...
01 定制虚拟机 1.1 什么是虚拟机 虚拟机是一个软件,运行在我们的计算机上,通过它可以模拟一台计算机。 虚拟机和真实的物理机器一样,也有CPU、硬盘、网卡、内存这些硬件,在虚拟机上同样可以安装操作系统,操作...

1.原理 在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer。每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序。可以看到,这本身就是一个二...
搜索离线dump集群(hadoop&hbase)2013进行了几次重大升级: 2013-04 第一阶段,主要是升级hdfs为2.0版本,mapreduce仍旧是1.0;同时hbase也进行了一次重大升级(0.94.5版本),hive升级到...
一 在HIVE中创建ETL数据库->create database etl;二 在工程目录下新建MysqlToHive.py 和conf文件夹在conf文件夹下新建如下文件,最后的工程目录如下图三 源码Import.xmladd user_all oder_all user_add oder_add ...
以下轮到FSNamesystem 出场了。 FSNamesystem.java 一共同拥有4573 行。而整个namenode 文件夹下全部的Java 程序总共也仅仅有16876行,把FSNamesystem 搞定了,NameNode 也就基本搞定。FSNamesystem 是NameNode ...
一、combiner --------------------------------- ...二、Ubuntu Hadoop 运行分布式作业 ----------------------------------- 1.启动hadoop集群 start-dfs.sh start-yarn.sh 注意:注...

MapReduce Tutorial(个人指导)Purpose(目的)Prerequisites(必备条件)Overview(综述)Inputs and Outputs(输入输出)MapReduce - User Interfaces(用户接口) Payload(有效负载) ...
例子1:package example; import java.io.IOException;...import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.HTable; impo
一 在HIVE中创建ETL数据库 ->create database etl; 二 在工程目录下新建MysqlToHive.py 和conf文件夹 在conf文件夹下新建如下文件,最后的工程目录如下图 三 源码 ...root&g...
HDFS Architecture(HDFS 架构) Introduction(简介)Assumptions and Goals(假设和目标) ...Hardware Failure(硬件失效是常态)Streaming Data Access(支持流式访问)Large Data Sets(大数据集)Simple...
在Ubuntu 12.04安装Hadoop过程详解。 相关阅读: 在Ubuntu 12.10 上安装部署Openstack http://www.linuxidc.com/Linux/2013-08/88184.htm Ubuntu 12.04 OpenStack Swift单节点部署手册 ...
随着互联网、移动互联网...目前对大数据的分析工具,首选的是Hadoop平台。Hadoop在可伸缩性、健壮性、计算性能和成本上具有无可替代的优势,事实上已成为当前互联网企业主流的大数据分析平台。 一、培训对象 1,
1.需要安装: jdk1.7 scala2.10.4 maven 3.3..9 idea 15.042.下载spark1.5.2源码 https://github.com/apache/spark 进release3.编译安装:mvn clean package -DskipTests查看详细错误:mvn...遇到的问题 (1)ma
如果一个类实现了的Hadoop的序列化机制(接口:Writable),这个类的对象就可以作为输入和输出的值 public class Employee implements Writable 举例1:使用Employee类来封装员工信息,并且作为Map和Reduce的输入和...
J2SE中提供了一个简单的命令行工具来对java程序的cpu和heap进行 profiling,叫做HPROF。HPROF实际上是JVM中的一个native的库,它会在JVM启动的时候通过命令行参数来动态加载,并成为 JVM进程的一部分。...
搭建Hadoop环境,将文件从本地上传到HDFS中出现以下异常 bin/hadoop dfs -copyFromLocal /home/ha/tmp/test.txt firstTest 12/08/23 16:34:36 WARN hdfs.DFSClient: DataStreamer Exception: org.apache.hadoop...
原文链接:http://dongxicheng.org/mapreduce/writing-hadoop-programes/ 1. 概述 1970年,IBM的研究员E.F.Codd博士在刊物《Communication of the ACM》上发表了一篇名为“A Relational Model of Data for Large...
项目部署Linux的那些步骤
推荐文章
- 深入理解代理模式:静态代理与JDK动态代理_jdk 代理是静态代理-程序员宅基地
- jquery checkbox全选,全不选,反选方法,jquery checkbox全选只能操作一次_js只能全选一次-程序员宅基地
- JAVA微信小程序论坛系统毕业设计 开题报告_论坛微信小程序设计报告-程序员宅基地
- command C:\Windows\system32\cmd.exe /d /s /c node ./build.js的解决方法_npm err! command c:\windows\system32\cmd.exe /d /s-程序员宅基地
- c32循迹小车c语言程序,stm32篇--小车循迹-程序员宅基地
- c语言单词错误答案正确,电大计算机科学与技术c语言各章练习题答案-程序员宅基地
- listview图片的异步加载-程序员宅基地
- Python_列表元素去重_target_list[i][3]-程序员宅基地
- STM32_DMA_多通道采集ADC出现错位现象_adcdma多通道数据错位-程序员宅基地
- 模型驱动开发的幻象与现实_软件模型与现实世界相悖-程序员宅基地