
”hadoop集群“ 的搜索结果
集群部署规划 hadoop102 hadoop103 hadoop104 HDFS NameNode DataNode SecondaryNameNode NataNode YARN NodeManager ...



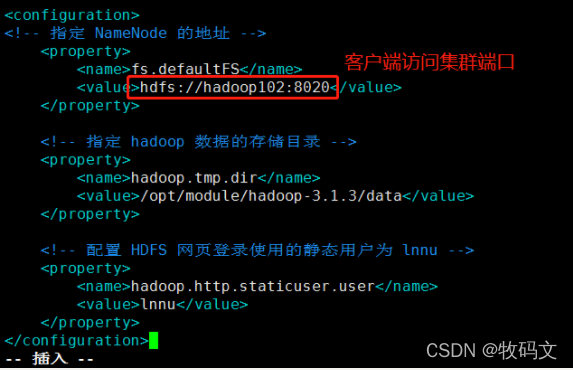


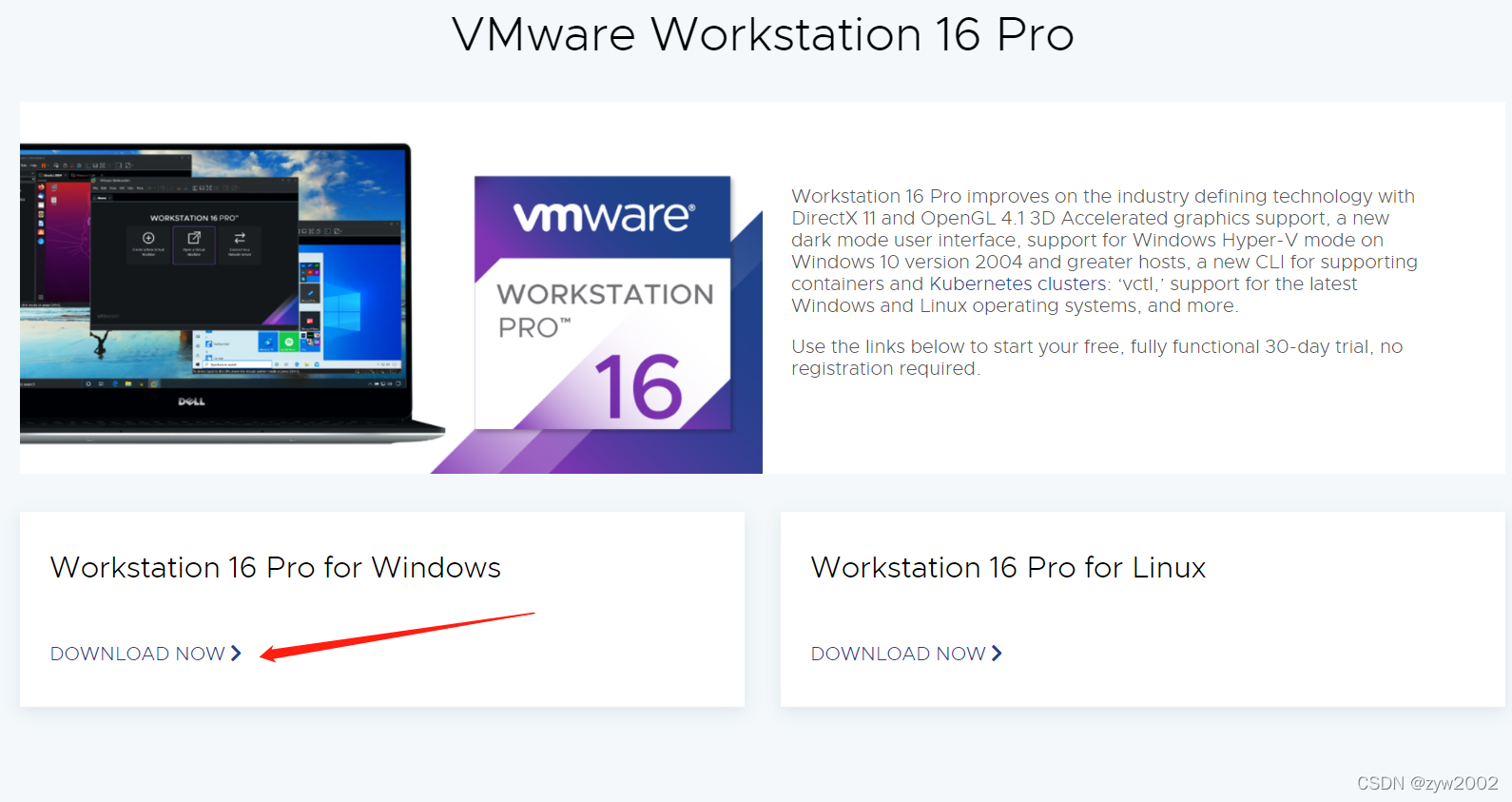

Hadoop 安装 1、 目录 Hadoop 安装 1、Hadoop 安装包下载 2、Hadoop安装配置(3个技术组件) 3、HDFS配置 Hadoop 安装包下载 安装前 分别在 hadoop01、hadoop02、hadoop03 三台机器的根目录下创建三个两...
设置服务器集群的时间同步,一台机器同时间服务器对时,其他机器与这台服务器对时,就是发生断网等情况,也可以保证内部所有服务器都时间统一;时间同步方式:找一个机器,作为时间服务器,所有的机器与这台集群时间...
二、集群数据均衡 2.1 节点间数据均衡 1)开启数据均衡命令 2)停止数据均衡命令 2.2 磁盘间数据均衡 1)生成均衡计划 2)执行均衡计划 3)查看当前均衡任务的执行情况 4)取消均衡任务 三、配置LZO压缩 1)下载...
在3台机器上执行产生自己的公钥: ssh-keygen -t rsa 按照默认值回车确定(如果询问是否overwirte,输入y覆盖掉原来的公钥即可) 将每台机器的公钥拷贝给每台机器,注意下面的指令要求3台机器都要执行: ...

然后hadoop是一个生态,就是说在其上还运行着hbase数据库,sqoop,shark等等工具,这样才能将hadoop存储的数据加以利用。Hbase是一种时序数据库,可用来往hadoop写数据,并通过hadoop读取数据,搭建这些的时候还要...
将idea项目打包在集群运行
在hadoop的使用过程中,由于操作不善,导致集群数据丢失、宕机无法重启等等,这个时候我们如何将我们的hadoop集群恢复到初始化状态呢,本节内容就是针对hadoop集群由于误操作,或者数据丢失等等,我们想将错误数据...

EasyHadoop集群部署文档\Hadoop常用命令\hadoop大数据架构生态技术简介\Hadoop权威指南\Hadoop实战
1.NameNode它时Hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存由metadata. 2.SecondaryNameNode它不是NameNode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并EditsLog,减少...
Hadoop集群搭建的详细步骤,涉及Linux:Centos6.5基础环境配置,Hadoop集群离线部署方式。

1.下载hive包,这里使用的是hive 2.3.0,hadoop 2.7.1 Index of /dist/hive 2.解压压缩包 tar zxvf apache-hive-2.3.0-bin.tar.gz -------------------------- 只是为了做实验使用,因此未创建工作组及hive...

Ubuntu搭建Hadoop集群的详细操作流程 一、准备工作 若还没安装虚拟机可参考:VMVMware14虚拟机安装程 没安装Ubuntu的可参考:Ubuntu的安装教程 Haddop的下载可以到https://mirrors.cnnic.cn/apache/hadoop/common/ ...

k8s搭建hadoop集群
K8S部署Hadoop集群 1、拉取镜像 到docker hub上拉取Hadoop镜像 [root@k8s-master hadoop]# docker pull kubeguide/hadoop:latest #### 2、复制镜像到其他节点 ```sh # 打包镜像到本地 [root@k8s-master hadoop]# ...
推荐文章
- Python菜鸟晋级04----raw_input() 与 input()的区别_pycharm没有raw input-程序员宅基地
- 高通AR增强现实多卡识别和扩展跟踪Unity_imagetarget扩展追踪-程序员宅基地
- 对于三星手机的手工root方法-程序员宅基地
- 2021年佛山高考成绩查询,2021年高三佛山一模,看佛山高中排名-程序员宅基地
- 删除并清空应收应付模块 期初数据_应付管理系统怎么清除数据-程序员宅基地
- 嵌入式固件加密的几种方式-程序员宅基地
- 非root情况下访问手机存储位置权限的方法_不root 通讯录 存放目录-程序员宅基地
- Mybatis项目开发流程_使用mybatis的开发步骤-程序员宅基地
- 三方协议,档案,工龄,保险,户口,-程序员宅基地
- 华为交换机命令 端口速率_华为S5700交换机的端口QOS限速问题-程序员宅基地