Hadoop系列文章 Hadoop架构、原理、特性简述Hadoop HDFSHDFS介绍HDFS架构图HDFS写入数据流程图HDFS读取数据流程图数据块的副本集Hadoop YARNYARN工作流程图YARN的原理及目标Hadoop MapReduceMapReduce工作流程...
”hadoop分区数据排序“ 的搜索结果

Hadoop大数据技术原理与应用
描述MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的。在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求。输入数据1 -12 2 -20 3 ...
一.MapReduce数据清洗 1.数据清洗要求 (1)解决乱码问题 (2)过滤少于6个字段的行 (3)统一字段之间的分隔符(统一用逗号) (3)在每行前添加年,月,日字段。 清洗前的数据 清洗后的数据 2.准备原始数据 说明...
哎,学习hadoop不容易啊,各种bug,摸不着头脑,时而管用,时而不知道namenode怎么停止了,确实郁闷!还好,坚持下去了!好了,不说了,开始简单示例 : 1.1 数据格式 : 日期 -空格 - 时间- tab键-温度 ...
对于MapTask,它会将处理的结果暂时放到环形缓冲区,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次**快速排序**,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行 **...
package sort;import java.io....import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;...
hadoop全流程图解



排序是Hadoop的默认行为,不管你是否需要,MapReduce的MapTask和Task都会对输出的结果的Key进行排序,默认的排序顺序是按照字典顺序排列,实现的方法是快速排序。自定义排序需要继承compareTo方法就完成了自定义排序...

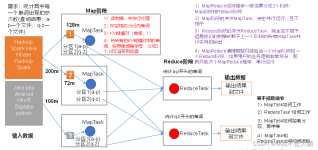
需求背景 MapReduce框架对处理...对于二次排序的实现,本文将通过两个个实际的MapReduce二次排序例子,讲述二次排序的实现和其MapReduce的整个处理流程,并且通过结果和map、reduce端的日志来验证所描述的处理流程的

map阶段的排序时对key进行排序,最简单的方式就是将要排序的字段封装成对象,然后这个对象实现WritableComparator接口重写compare这个比较方法,在shuffle阶段就会按照这个定义排序; 2,reduce阶段排序 其实在redu
在hive中有时会删除表(外部表)然后创建表,此时表元数据并不能和表信息映射,需要我们使用修复语句msck repair table 库名.表名;有些时候会报错,追踪了下原因,是hdfs上文件分区与hive分区不一致,我们强制忽略就...

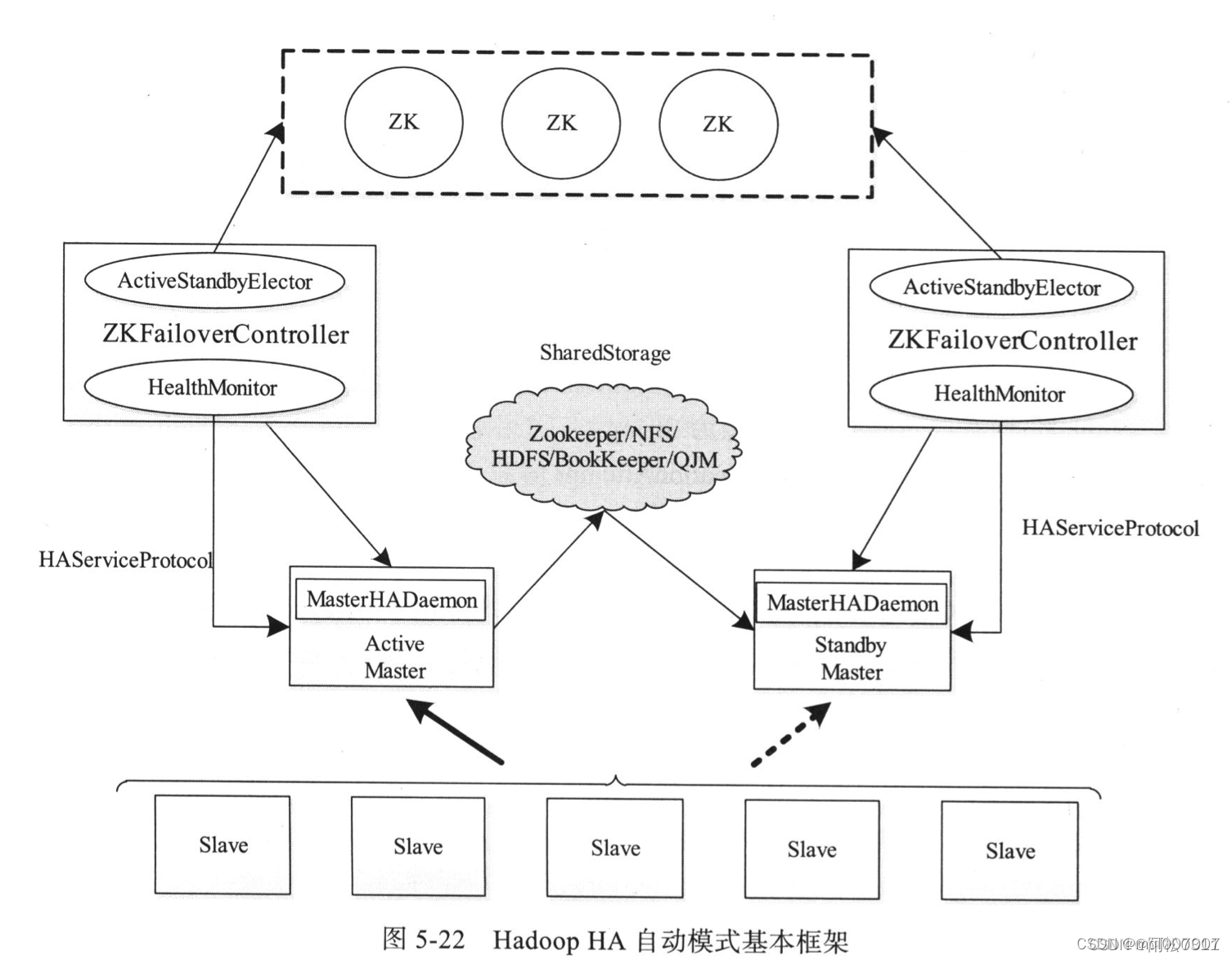
来这里找志同道合的小伙伴!...一、背景提到大数据不得不提Hadoop,当下的Hadoop已不仅仅是当初的HDFS + MR(MapReduce)这么简单。基于Hadoop而衍生的Hive、Pig、Spark、Presto、Impala等一系列组件...
备份节点只通过复制功能写入数据,不接受客 户端的写入请求;MongoDB各个节点常见搭配方式为:一主一从、一主多从;所有写入操作都在主节 点上 191. MongoDB 数据库关于集合的命名规则,下列选项描述正确的是不能是...

wordcount



可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。本文介绍如何通过ES-Hadoop实现Hadoop的Hive服务...
推荐文章
- 反编译delphi_反编译Delphi(1/3)-程序员宅基地
- node_acl用法示例_node acl-程序员宅基地
- 使用STM32提供的DSP库进行FFT_stm32的dsp库 直流分量-程序员宅基地
- VScode 报错 :crbug/1173575, non-JS module files deprecated._crbug/1173575是什么原因-程序员宅基地
- C++学习_3-程序员宅基地
- eigen 构造变换矩阵(Eigen::Isometry3d或者Eigen::Matrix4d)的几种方式-程序员宅基地
- C++ 如何初始化静态类成员(静态成员必须在.cpp文件中初始化)_c++ 静态成员变量初始化-程序员宅基地
- 48,原子核物理实验方法篇_短时间的高剂量照射后果-程序员宅基地
- el-dialog修改默认内边距_el-dialog__body修改padding-程序员宅基地
- 公网下远程树莓派Raspberry Pi的SSH/WOL/监控/桌面的实现_ssh wol-程序员宅基地