
”hadoop分区数据排序“ 的搜索结果
(1)//多个Reducer处理同一个分区 (2)自定义分区 (3)增加或者减少reducer的数量(hash分区有效) (4)硬件上:增加机器的jvm内存 (5)去除噪音数据 (6)重新定义key:比如改变key中数据的顺序 比如先在传输的时候给key加...
♦数据分析平台框架设计与环境配置 Hadoop MapReduce与Hive技术研究 一、Hadoop框架工作机制 Hadoop框架定义:Hadoop分布式文件系统(HDFS)和Mapreduce实现。并行程序设计方法中最重要的一种结构就是主从结构...
《Hadoop MapReduce实战手册》学习笔记
Hadoop对输出的数据进行排序另外分组 数据 如果没有数据的话可以点开 https://blog.csdn.net/qq_17623363/article/details/104146939 对我这个案例进行做出来 然后 这是上一个案例另外加的一个分组 代码 ...
1.基础数据主表2亿以上... 基础数据导入hadoop, ETL处理过程由hadoop处理,处理结果再导回数据库 6.问题hadoop中如何进行多表关联查询或者类似存储过程那样的处理? hadoop我没接触过,请专家帮忙详细解答一下,谢谢!
Hadoop生态中的Mapreduce在map阶段可以将大数据或大文件进行分区,然后到Reduce阶段可并行处理,分区数量一般与reduce任务数量一致;自定义实现Hadoop的WritableComparable接口(序列化并排列接口)的Bean在...
MapReduce分区和排序综合案例。 在进行MapReduce计算时,有时会需要我们把最终的输出数据按照某种规则放到不同的不同的文件中,比如手机号的前三位划分省份,要把同一个省份的数据放到同一个文件中。对于MapReduce...
Hadoop:HDFS MapReduce(清洗) YARN、需要部署Hadoop集群 Hive:外部表、SQL 、解决数据倾斜 、sql优化、基于元数据管理、SQL 到MR过程 Flume:将数据抽取到hdfs 调度:crontab、shell、Azkaban HUE:可视化的...
在昨天的基础上,做的Hive的应用方法接着已经搭建配置好后,直接在根目录下进行hive(按课件说明,也要先进行启动HDFS和YARN)创建create//删除drop//查看show//使用use——数据库、表导入文件/数据:①把本地的.txt...
虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了大规模扩展。本文将介绍大数据系统一个最基本的组件:处理框架。处理框架负责对系统中.....

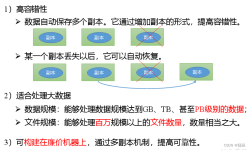
导读相信很多接触MapReduce的朋友对'数据倾斜'这四个字并不陌生,那么究竟什么是数据倾斜?又该怎样解决这种该死的情况呢?何为数据倾斜?在弄清什么是数据倾斜之前,我想让大家看看数据分布的概念: 正常的数据分布...
Hadoop 图处理 1.1 实验内容 本课程将基于hadoop平台实现Giraph 分布式系统中的图处理。 1.2 课程来源 本课程基于 图灵教育 的 《Hadoop应用架构》 第5章制作,真诚感谢 图灵教育 对实验楼的授权...
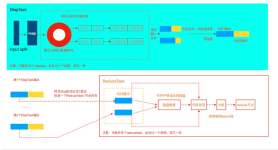
MapReduce解决了海量数据的分布式处理 YARN 做资源调度管理 HDFS:NN Federation 、HA(NN-name node Federation 做数据目录服务,可设置多个name node 进行分区管理;HA:高可容性,热备份) pig:轻量级脚本语言,...
283. 在 Linux 系统中创建一个目录 work,切换到该目录,并在该目录下创建文件 file.txt, 写入内容“I have a dream!”,最后查看文件是否创建。 mkdir work ...插入下列数据: 学号,姓名,性别 0
有需要整个项目的可以私信博主,提供部署和讲解,对相关案例进行分析和深入剖析环境点击顶部下载本研究旨在...在数据清洗方面,我们进行了空值检测与处理、字符串约束、字段值扩充等操作,使得数据变得更加准确和可靠。
Hadoop数据压缩、Yarn架构以及工作流程、Hadoop企业优化方案
Hadoop 基本使用中的自定义数据类型和自定义排序

MapReduce是hadoop的核心组件之一,...Windows下登录Hadoop102lcd切换Windows路径,cd切换Linux路径,get下载,put上传MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop 的数据分析应用”的核心框架。

以便将同一分组的数据交给同一个 Reducer 处理,它直接影响 Reduce 阶段的负载均衡。 Map阶段总共五个步骤 step1.3就是一个分区操作 Mapper最终处理的键值对key, value>,是需要送到Reducer去合并的,合并...
MapReduce是一种可用于数据处理的编程模型。Hadoop可以运行各种语言版本的MapReduce程序。MapReduce程序本质上是并行运行的,因此可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心。MapReduce的...
Hadoop数据本地化
标签: hadoop
首先需要知道,hadoop数据本地化是指的map任务,reduce任务并不具备数据本地化特征。 通常输入的数据首先将会分片split,每个分片上构建一个map任务,由该任务执行执行用户自定义的map函数,从而处理分片中的每条...
默认情况下,Map输出的结果会对Key进行默认的排序,但是有时候需要对Key排序的同时还需要对Value进行排序,这时候就要用到二次排序了。下面我们来说说二次排序 1、二次排序原理 我们把二次排序分为以下几个阶段 ...
推荐文章
- 在windows server 2008 64位服务器上配置php环境_在2008服务器上面配置phpmyadmin访问-程序员宅基地
- python 特征选择卡方_4. 机器学习之特征选择-Python代码-程序员宅基地
- WebGL快速入门_webgl入门-程序员宅基地
- C++中的String的常用函数用法总结_string函数-程序员宅基地
- 金融风控训练营金融风控基础知识学习笔记_风控师学习笔记-程序员宅基地
- 哈希表 添加 增添 删除 获取方法 Js封装_js hash追加-程序员宅基地
- JS数据结构-Set集合,创建Set,常用Set方法_js set-程序员宅基地
- C#版的抓包软件_c# winpcap-程序员宅基地
- Unity中批量修改图片导入设置及修改图集的设置_unity立绘整合怎么修改-程序员宅基地
- 【CC2650】——电池电量报文显示_csdn电源耗电量报文-程序员宅基地