color:rgb(60,132,189)">Hadoop Mapreduce分区、分组、二次排序过程详解[转]作者: 徐海蛟 教学用途 1、MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partiti
”hadoop分区数据排序“ 的搜索结果

目录排序排序的分类自定义排序数据预处理全排序与区排序全排序重写Bean类编写Mapper类编写Reduce类编写Driver类结果区排序重写Partition编写Driver类运行结果 排序 排序的分类 部分排序:MapReduce根据输入记录的键...
二级排序 即对key和value双排序。默认情况下,Map输出的结果会对Key进行默认的排序,但是有时候需要对Key排序的同时还需要对Value进行排序,这时候就要用到二次排序了。 有两种方法进行二次排序,分别为:buffer ...

Hadoop流处理(Hadoop Streaming)是一种将命令行接口(CLI)工具与Hadoop MapReduce框架结合使用的方法,以实现数据处理和分析任务。Hadoop流处理允许用户使用任何编程语言(如Python、Ruby、Perl等)编写MapReduce任务,...
我们的需求是想统计一个文件中用IK分词后每个词出现的次数,然后按照出现的次数降序排列。... 第一个job的就是hadoop最简单的例子countwords,我要说的是用hadoop对结果排序。 假设第一个job的结果输出如下: par

基本思路是利用map来产生,num>这样的数据,这样reduce处理的数据形式是,num1 nmu2 …..>. 代码: import java.io.IOException; import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration; ...
一文让你学明白Hadoop!《大数据技术之Hadoop》详细知识总结
Hadoop 的设计目标是能够处理以千万、亿计的数据为基础的应用程序,提供高可靠性、高性能和高可扩展性的数据处理服务。Hadoop 的历史可以追溯到 2003 年,当时 Doug Cutting 和 Mike Cafarella 在开发一个全文搜索...
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN 网址:https://blog.csdn.net/chenwewi520feng/article/details/130454036 本文介绍MapReduce常见的基本用法。 前提是hadoop环境可正常运行。 ...



第五章 MapReduce的WordCount案例和分区 第六章 MapReduce的排序和序列化 第七章 MapReduce的运行机制和join操作 第八章 MapReduce的其他操作和yarn 第九章 数仓Hive基本操作 第十章 数仓Hive的其他操作和调优

作者:禅与计算机程序设计艺术 1.简介 随着互联网、移动互联网、物联网等新型设备的广泛普及,以及各种应用系统的不断发展,越来越多的数据产生出来,而...大数据的处理方法可以分为三个阶段:数据采集、数据存储、数
元数据的重要性 ...元数据允许用户提供数据的信息(如分区或者排序特性),而后通过不同个的工具(用户或者其他人写入的)利用这些信息生成或者查询工具 元数据允许数据管理工具链接该元数据,而且允许用户执行数据查
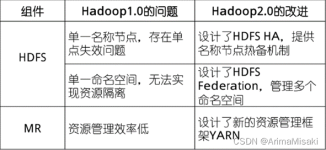


Hadoop提供的Partitioner组件可以让Map对Key进行分区,从而可以根据不同key来分发到不同的reduce中去处理,我们可以自定义key的分发规则,如数据文件包含不同的省份,而输出的要求是每个省份对应一个文件。...
Partitioner编程Partition简介shuffle是通过分区partitioner 分配给Reduce的 一个Reducer对应一个记录文件Partitioner是shuffle的一部分partitioner执行时机:在mapper执行完成,Reducer还没有执行的时候,mapper的...
使用combinner合并,combinner是在map阶段,reduce之前的一个中间阶段,在这个阶段可以选择性的把大量的相同key数据先进行一个合并,可以看做是local reduce,然后再交给reduce来处理。最容易造成的结果就是大量相同key被...
Hive是构建在Hadoop之上的数据仓库平台。 Hive是SQL解析引擎,它将SQL语句转译为MapReduce作业,并在Hadoop上运行。 Hive表是HDFS的文件目录,一个表对应一个目录名,如果有分区的话,则分区值对应子目录。 对比 ...
1.背景介绍 大数据处理是指处理和分析大量、高速、不断增长的数据,这些数据通常来自不同的来源,如...Hadoop是一个开源的大数据处理框架,它可以处理大量数据并提供高性能、可扩展性和容错性。 本文将从以下几...
Hadoop是一个开源的分布式计算平台,用来处理大规模数据集。它基于Google的MapReduce算法和Google文件系统(GFS)的论文实现,通过分布式存储和计算来处理大规模数据。
1.分片(splits)相关...每个map处理一个fileSplit,所以有多少个fileSplit就有多少个map(map数并不是单纯的由用户设置决定的)。 我们来看一下hadoop分片splits的源码: long goalSize = totalSize / (numSplit...
介绍一个 Hadoop生态离线项目: 涉及到的技术: Hadoop:HDFS(数据存储的地方) MapReduce... Hive:数据清洗之后,数据放在hdfs上,需要使用外部表,所有维度的数据统计分析需要通过SQL进行处理分析。在这里数...
推荐文章
- PL2303驱动安装需要联网_ztekdriver_pl2303-程序员宅基地
- Android P Camera架构_android camera2 id 103-程序员宅基地
- 米家接入HomeKit系列二:通过群辉NAS的Docker搭建HomeAssistant_群晖接入米家-程序员宅基地
- Windows 10下载安装openjdk及环境变量配置(以openjdk 8为例)_openjdk环境变量配置-程序员宅基地
- PyTorch如何打印模型详细信息_python打印模型-程序员宅基地
- 维修Proface普洛菲斯触摸屏GP-4502WW 4301 4501TW 4401T人机界面-程序员宅基地
- Apipost 上手指南_apipost上传文件接口-程序员宅基地
- linux单机巡检脚本并发送邮箱的巡检报告-程序员宅基地
- 强强联手:强网杯LongTimeAgo复盘分析网络安全-程序员宅基地
- 【嵌入式总复习】Linux进程间通信_嵌入式 linux 跨进程 信号-程序员宅基地