
”hadoop分区数据排序“ 的搜索结果
Hadoop分区排序
标签: hadoop
Hadoop全排序相关 分区排序要点思路分析代码示例CustomGroupingComparator代码CustomPartitioner代码Mapper代码Reduce代码OrderBean代码Driver代码总结流程示意 要点 2 分区排序(默认的分区规则,区内有序) 直白...
hadoop分区二次排序示例,对基站数据,按电话号码升序、到达时间降序进行排序
mapreduce分区机制
mapreduce排序机制
shuffle阶段的排序可以理解成两部分,一个是对spill进行分区时,由于一个分区包含多个key值,所以要对分区内的按照key进行排序,即key值相同的一串存放在一起,这样一个partition内按照key值整体有序了。 第二部分...
hadoop分区二次排序代码示例,包含基站数据集,对基站数据,按电话号码升序、到达时间降序进行排序,只需打包成jar,即可在hadoop集群中运行

考虑从/source/first和 /source/second/ 拷贝文件到/target/# -------------- 跨集群数据同步(先建立表 文件在复制对应的 表文件下) ------------# ---------- 先提前创建分区内容(会记录到源数据里面,负责没数据的...
hive分区、分桶,javal连接hive,Hive的四种排序方式

Spark and Hadoop碎片知识点合集
hadoop高频面试题整理
2、分区方式(1)范围分区范围分区:按照数据表中某个值得范围进行分区,根据值得范围决定数据所在分区。主要特点:能够根据数据的范围,将不同范围的数据存储在不同的分区。适用:按照时间范围存储数据的系统(日志...
云计算大作业使用Hadoop对美国新冠肺炎疫情数据分析项目。 实验内容 统计指定日期下,美国每个州的累计确诊人数和累计死亡人数。 对实验1的结果按累计确诊人数进行倒序排序。(重写排序规则) 对实验1的结果再运算,...
Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到...
4) 将这些数据缓存到 环形缓存区中, 环形缓冲区默认的大小是100M , 有一个临界值0.8, 当达到这个临界值的时候, 会启动一个溢写的线程,...5) 在执行溢写时, 会对溢写的数据进行排序操作, 如果此时有规约, 也会执行规约。
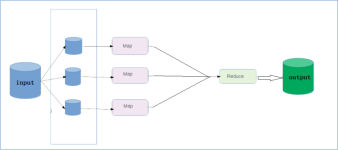
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务 器有各自的角色。。
Hadoop面经
Hadoop(10) MapReduce-3 分区, 排序和合并 分区(Partition) 分区的介绍 分区的作用 之前我们介绍过, 每个分区对应一个ReduceTask, 如果所有MapTask的结果都由一个ReduceTask来汇总, 会很慢, 所以对MapTask的内容进行...
1) hadoop在处理Text文件时,key是行号LongWritable类型,InputSampler抽样的是key,TotalOrderPartitioner也是用key去查找分区。这样,抽样得到的partition文件是对行号的抽样,结果自然是根据行号来排序。
将统计结果按照手机归属地不同省份输出到不同文件中(分区)。 1、输入数据 1,13736230513,192.196.100.1,www.atguigu.com,2481,24681,200 2,13846544121,192.196.100.2,,264,0,200 3,13956435636,192.196.100.3,,...
***相同组内的k-v,由同一次的reduce方法处理 一、为什么写 分区和分组在排序中的作用是不一样的,今天早上看书,又有点心得体会,记录一下。 二、什么是分区 1、还是举书上的例子,在8.2.4章节...
关于数据倾斜、hadoop中数据倾斜产生的原因、数据倾斜的表现、以及解决方案

Hadoop默认分区是根据key的hashCode对ReduceTask个数取模得到的,用户无法控制哪个key存储到哪个分区。 想要控制哪个key存储到哪个分区,需要自定义类继承Partitioner<KEY, VALUE>, 泛型KEY, VALUE分别...
文章目录 一、分区
推荐文章
- EfficientDet 训练自己的数据集_efficientdet训练自己的数据-程序员宅基地
- HTML文件总是WPS打开,设置wps默认打开方式_设置默认使用WPS打开文件-程序员宅基地
- ISE14.7安装行得通的路。当你是win11。_ies 14.7 虚拟机-程序员宅基地
- Linux进程间通信-程序员宅基地
- Roxlabs数据获取服务:解锁高效数据采集与网络应用新境界-程序员宅基地
- FAISS+bge-large-zh在大语言模型LangChain本地知识库中的作用、原理与实践_bge-large-zh训练自己的知识库-程序员宅基地
- 用Python实现打印杨辉三角-程序员宅基地
- html未找到音频文件夹,【已解决】html5中MediaRecorder的dataavailable没有执行获取不到录音数据...-程序员宅基地
- CCF|| 201809-1 卖菜_ccf 201809-1 卖菜-程序员宅基地
- intel cpu性能瓶颈分析方法_使用intel tmam 测量-程序员宅基地