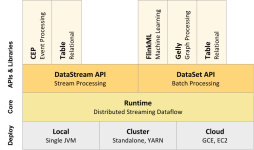
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。Flink最适合的应用场景是低时延的数据处理(Data...
”flink“ 的搜索结果
Flink第一章实时计算引擎
标签: flink


Flink总结
标签: flink checkpoint state

手动编译基于cdh版本的flink
Flink的并行度及Slot
标签: flink
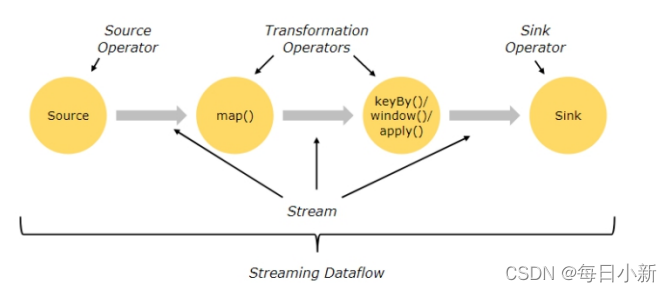
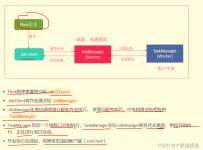
一个Flink程序Application由多个任务组成(source、transformation和sink),一个任务由多个并行实例(线程)来执行,一个任务的并行度实例(线程数)数目被称为该任务的并行度。 并行度的设置方式: a、...
将flink-sql-connector-mysql-cdc/target/flink-sql-connector-mysql-cdc-2.2.0.jar拷贝到本地进行引用,同时将原来pom.xml的flink-connector-mysql-cdc依赖注释掉,最后就可以在本地运行项目了。如果不放心可以在...

flink redis connector(支持flink sql) 1. 背景 工作原因,需要基于flink sql做redis sink,但bahir 分支的flink connector支持只是基于datastream,而需要支持flink sql,还需要进一步完善 flink sql及flink ...
Flink教程。Flink 是一个同时具备流数据处理和批数据处理的分布式计算框架。flink代码主要是由 Java 实现,部分代码由 Scala实现。Flink既可以处理有界的批量数据集、也可以处理无界的实时数据集。就业界的使用情况...
flink 介绍,描述flink 场景使用及不足。flink 技术栈包含内容
在 Flink on yarn 的模式下,taskManager的日志会存储到所在的DataNode上,当 Flink 任务发生异常,产生异常日志时,需要我们第一时间感知任务已经出现异常,避免影响业务。因此我们需要将Flink任务的日志实时收集...
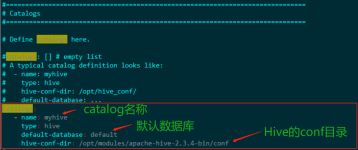
的启用、存储方式、存储位置,在应用代码中配置,其中存储方式、存储位置,也可以在flink-conf.yaml文件中通过state.backend、state.checkpoints.dir参数配置全局参数,但应用代码中配置优先级更高。(3) Flink ...


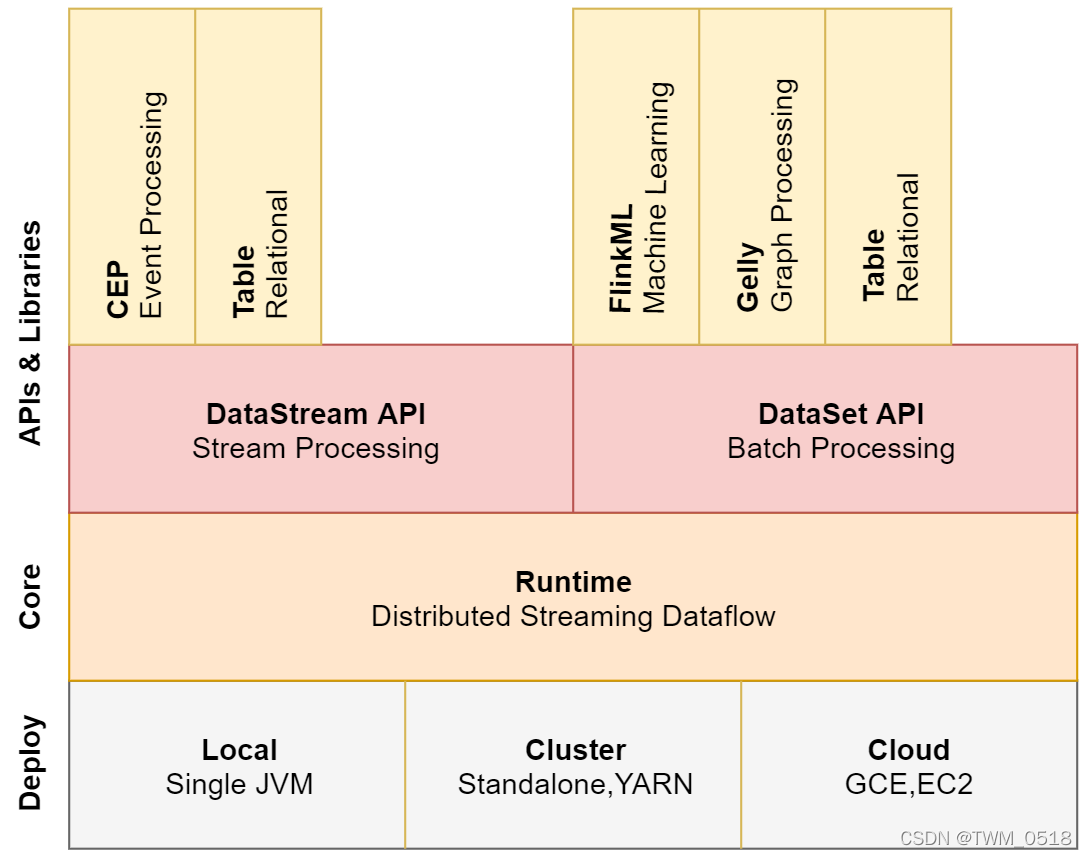
Flink 是一个流式计算引擎。既支持实时的 Streaming 模式对进来的数据进行逐一处理,也适合对批量的数据做 Batch 处理。 一句话,对实时/离线的数据处理做到了批流合一。 Flink 对于数据和数据流做了非常好的抽象,...
Flink1.13.6详细部署方式
标签: 大数据
进入Flink官网,点击Downloads往下滑动就可以看到 Flink 的所有版本了,看自己需要什么版本点击下载即可。
Spark 还是 Flink? 前言 Apache Spark 是一个通用大规模数据分析引擎。它提出的内存计算概念让大家得以从 Hadoop 繁重的 MapReduce 程序中解脱出来。除了计算速度快、可扩展性强,Spark 还为批处理(Spark SQL...


推荐文章
- Adaboost模型公式的参数推导_adaboost加权公式-程序员宅基地
- 削峰填谷与应用间解耦:分布式消息中间件在分布式环境下并发流量控制的应用_消息中间件削峰填谷-程序员宅基地
- C 语言实现智能指针___attribute__((cleanup(free_stack)))-程序员宅基地
- 刮刮卡兑换-程序员宅基地
- H5横屏,移动端缓存_h5 横向-程序员宅基地
- python wx包_今天玩点啥:python真香系列之利用wxpy包写一个微信消息自动回复插件...-程序员宅基地
- 【PCL】使用自定义点类型时LNK2001、LNK2019链接错误解决_使用pcl出现link2019-程序员宅基地
- 获取数组中元素个数的方法_qt获取数组的元素个数-程序员宅基地
- Centos7 安装 docker及docker-compose_yum install -y yum-utils device-mapper-persistent--程序员宅基地
- c 与易语言程序间通信,易语言与三菱PLC通信-FX系列-程序员宅基地