
”flink“ 的搜索结果
上一篇博文介绍了如何独立部署一个高可用的Flink集群,本篇介绍如何用Native k8s去部署高可用的Flink 集群。本篇介绍的集群构建在AWS上,和构建在自己的服务器相比,主要区别在文件系统的选择和使用上。我选用的S3...
概述2019 年是大数据实时计算领域最不平凡的一年,2019 年 1 月阿里巴巴 Blink (内部的 Flink 分支版本)开源,大数据领域一夜间从 Spark 独步天下走向了两强争霸...
Flink实践手册Flink

随着互联网的发展和数据量的爆炸式增长,...Flink的WebSocket API基于Java NIO的WebSocket协议,通过连接到Flink Streams API的WebSocket端口,实时数据流被转换为流数据,并经过一系列的处理,最终输出可视化数据。
背景:近期项目需要,引入flink,研究了下flink,步步踩坑终于可以单独运行,也可发布到集群运行,记录下踩坑点。开发环境:idea+springboot(2.3.5.RELEASSE)+kafka(2.8.1)+mysql(8.0.26)。废话不多说,直接上可执行...
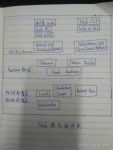

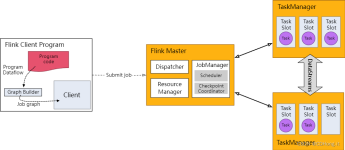
文章目录01 引言02 Flink 知识结构2.1 Flink介绍2.2 环境准备2.3 Flink编程模型2.4 DataStream API2.5 Flink状态管理和容错2.6 DataSet API2.7 Table API & SQL2.8 Flink组件栈2.9 Flink部署与应用2.10 Flink...
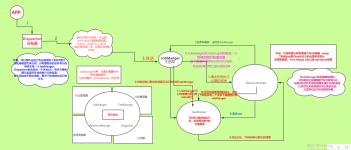
Flink平台部署方案 持续保持更新 有些部署yaml借鉴的文章忘记哪里搬过来了额,但是经过自己测试过可行 再次表谢感谢 1. HDFS部署 (k8s) 可以单独create -f 部署,也可以基于helm统一部署 1.1 hdfs-conf.yaml api...
Apache Flink,作为一个开源的分布式处理引擎,近年来在大数据处理领域崭露头角,其独特的流处理和批处理一体化模型,使得它能够在处理无界和有界数据流时展现出卓越的性能。本文旨在对Flink进行简要的前言性介绍,...
Flink 中的每个方法或算子都能够是有状态的(Flink(八)Flink四大基石之State概念、使用场景、持久化、批处理的详解与keyed state和operator state、broadcast state使用和详细示例了解更多)。状态化的方法在处理...

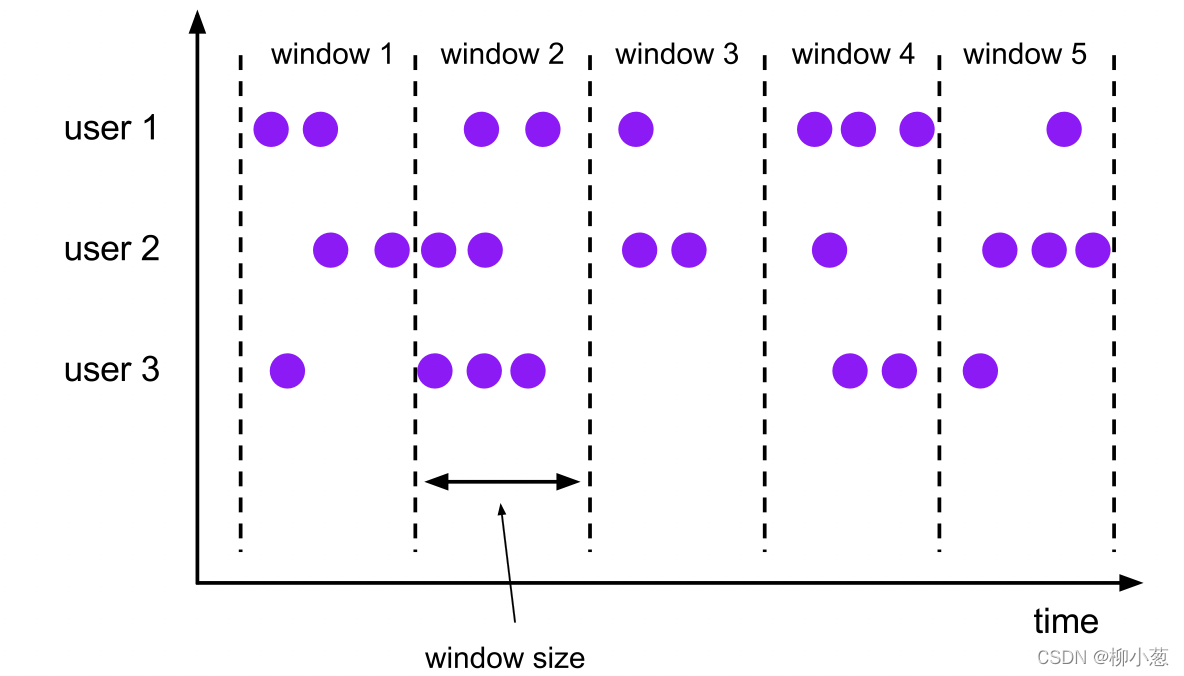
主要记录FLink1.17学习笔记,包含FLink部署模式、DataStrem、时间和窗口、处理函数、多流转换、状态编程、容错机制、Table API和SQL等等。

Flink相关论文

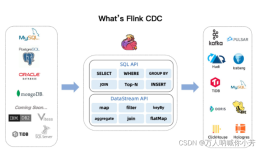

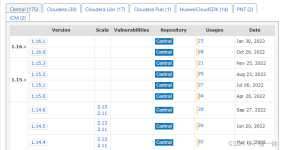
一、
数据库中的CDC(Change Data Capture,变更数据捕获)是一种用于实时跟踪数据库中数据变化的技术。CDC的主要目的是在数据库中捕获增量数据,以便在需要时可以轻松地将这些数据合并到其他系统或应用程序中。...
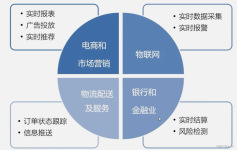
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地