”flink“ 的搜索结果
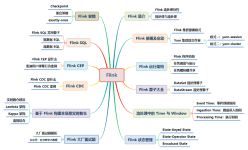
一文弄懂Flink CDC
标签: flink
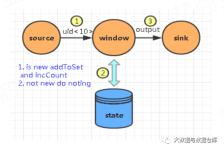
Flink CDC的详解,一文就能理解透彻

一文弄懂Flink基础理论
标签: flink

org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: Failed to execute job 'Flink Kafka'. at org.apache.flink.client.program.PackagedProgram.callMainMethod...
Flink SQL客户端
标签: flink
Flink SQL客户端 1.概述 Flink 的 Table & SQL API 可以处理 SQL 语言编写的查询语句,但是这些查询需要嵌入用 Java 或 Scala 编写的表程序中。此外,这些程序在提交到集群前需要用构建工具打包。这或多或少限制...
Flink 怎么部署安装?
标签: flink
import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment....
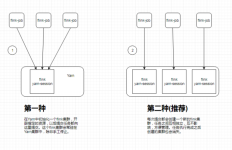
Flink平台部署方案 持续保持更新 有些部署yaml借鉴的文章忘记哪里搬过来了额,但是经过自己测试过可行 再次表谢感谢 1. HDFS部署 (k8s) 可以单独create -f 部署,也可以基于helm统一部署 1.1 hdfs-conf.yaml api...
Flink教程。Flink 是一个同时具备流数据处理和批数据处理的分布式计算框架。flink代码主要是由 Java 实现,部分代码由 Scala实现。Flink既可以处理有界的批量数据集、也可以处理无界的实时数据集。就业界的使用情况...
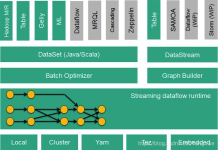
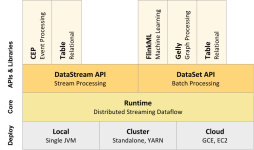
什么是Flink2.特点3.对比4.流处理、批处理5.架构体系 一.简介 1.什么是Flink Apache Flink是分布式大数据处理引擎,可对有限数据流和无限数据流进行状态计算,可部署在各种集群环境下,对各种大小的数据进行快速计算...
Spark 还是 Flink? 前言 Apache Spark 是一个通用大规模数据分析引擎。它提出的内存计算概念让大家得以从 Hadoop 繁重的 MapReduce 程序中解脱出来。除了计算速度快、可扩展性强,Spark 还为批处理(Spark SQL...

Flink Native Kubernetes是1.10版本才有的新功能,通过bin目录下的工具控制kubernetes环境下的flink操作
Flink的并行度及Slot
标签: flink
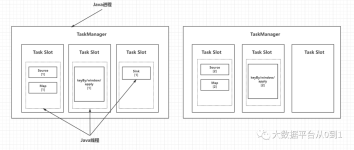
一个Flink程序Application由多个任务组成(source、transformation和sink),一个任务由多个并行实例(线程)来执行,一个任务的并行度实例(线程数)数目被称为该任务的并行度。 并行度的设置方式: a、...
Flink第一章实时计算引擎
标签: flink
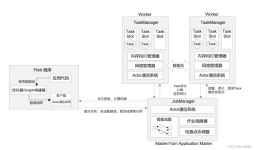
Flink 资源管理
标签: flink
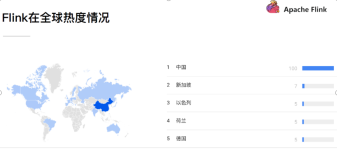
Apache Flink,作为一个开源的分布式处理引擎,近年来在大数据处理领域崭露头角,其独特的流处理和批处理一体化模型,使得它能够在处理无界和有界数据流时展现出卓越的性能。本文旨在对Flink进行简要的前言性介绍,...

一、
Flink总结
标签: flink checkpoint state
Flink CDC踩坑集合
标签: flink
Flink版本-1.11.0 Flink-CDC版本- 1.1.0 问题集合 1. 使用flink sql 时,需要引入flink-json依赖 异常信息 Caused by: org.apache.flink.table.api.ValidationException: Could not find any factories that ...
推荐文章
- ps play服务器没有响应mac,【攻略技巧】人在外心在家 教你用PC/MAC远程打PS4-程序员宅基地
- PHP实现在数据库百万条数据中随机获取几条记录的方法_海量数据随机查询-程序员宅基地
- 基于CC2530的停车场系统_基于cc2530课程设计项目免费-程序员宅基地
- oracle求非偶非素数的和,每个大于的2偶数都是2个素数之和,(无素数定理)-程序员宅基地
- 有了它们,我把所有截图、录 GIF、录屏软件都卸了-程序员宅基地
- 170402网摘题目-程序员宅基地
- 安装paddlespeech报错ERROR: Could not build wheels for webrtcvad_could not build wheels for webrtcvad, which is req-程序员宅基地
- C# 将多个图片合并成TIFF文件的两种方法-程序员宅基地
- 基于springboot+vue.js的中山社区医疗综合服务平台附带文章和源代码设计说明文档ppt-程序员宅基地
- 【代码超详解 · 附参考模板】洛谷 P1226 【模板】快速幂||取余运算_洛谷批改代码系统如何实现-程序员宅基地