docker搭建hadoop集群
”docker搭建hadoop“ 的搜索结果
1.安装docker 2.docker安装Hadoop
###### 这个Dockerfile主要是基于CentOS镜像进行一些系统设置和软件安装,最终生成一个包含SSH服务的镜像。####### dockerfile的内容# 基础镜像# 作者# 将工作目录切换到`/etc/yum.repos.d/`# 使用sed命令注释掉...
第1章 写在前面必读 ...Hbase是一种时序数据库,可用来往hadoop写数据,并通过hadoop读取数据,搭建这些的时候还要用到zookeeper软件去管理消息。总之hadoop生态涉及的东西太多,学习起来复杂,但是并不难,就是
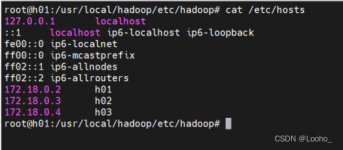
对各个节点指定好功能 maseter为主节点,hadoop01 为从节点和datanode hadoop02 为yarn主节点负责各个节点的资源调度, hadoop02,hadoop03为datanode节点 OS hostname IP Centos8 hadoop-master ...
基于Docker搭建Hadoop集群(2).docx
在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了。 一:环境准备: 1:首先要有一个Centos7操作系统,可以在虚拟机中安装。 2:在centos7中安装docker,docker...
基于 Docker 搭建完全分布式 Hadoop 平台 小白的折腾记录

每一天,都充满惊喜,总会遇见不同的人,看见不同的风景,听见不同的故事,这样就很好!!!

本文探讨了使用 Docker 搭建 Hadoop + Hive + Spark 集群的方法,项目地址在此。在阅读本文前,建议先对 Docker 以及 Docker Compose 有基本的了解。 准备工作 本项目基于Docker和Docker Compose,搭建的集群包含...
docker network create --subnet=172.20.0.0/16 hadoop-cluster 2. 创建自定义镜像(基于centos) 拉取centos镜像: docker pullcentos:latest 运行容器: docker run -d --privileged --name cluster-master ...



按照这两篇文章即可,总结来说 pull ubuntu,进入系统,配置java、hadoop,保存镜像。然后根据这个镜像启动三个容器master,slave1,slave2,在master上配置相关信息。把程序在本地打成jar包,传到容器内(ubuntu)...
spark要配合Hadoop的hdfs使用,然而Hadoop的特点就是分布式,在一台主机上搭建集群有点困难,百度后发现可以使用docker构建搭建,于是开搞: github项目:https://github.com/kiwenlau/hadoop-cluster-docker ...
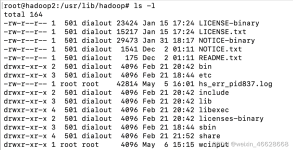
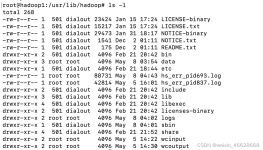
要用docker搭建集群,首先需要构造集群所需的docker镜像。构建镜像的一种方式是,利用一个已有的镜像比如简单的linux系统,运行一个容器,在容器中手动的安装集群所需要的软件并进行配置,然后commit容器到新的镜像...
下载VMware、Xshell、Xftp、centos7映像文件、hadoop和jdk的压缩包。
以一主二从的Hadoop集群为例,在搭建时,需要如下条件: 启动三台机器 三台机器要相互和自身免密登录 每台机器都要有Java和Hadoop的环境,并且Hadoop的配置文件也要相同 基于这个条件,构建一个已经安装好相关软件...
这只是一个简单的示例教程,用于在Docker中搭建Hadoop集群。实际上,搭建和配置一个完整的Hadoop集群涉及到更多的步骤和详细的配置。你可以通过进一步研究Hadoop文档和参考资料来了解更多关于Hadoop集群的配置和管理...
人工智能-Hadoop
推荐文章
- HTML刷新当前页面的小脚本_html刷新网址脚本-程序员宅基地
- m_map绘制多波束数据-程序员宅基地
- java语言实现多态的方式_什么是多态机制?Java语言是如何实现多态的?【详细解释】...-程序员宅基地
- Spring boot 整合 rabbit MQ 死信队列的应用-订单过期自动取消_rabbitmq 死信队列 处理订单过期未支付-程序员宅基地
- java反编译的静态方法参数问题6_java8 探讨与分析匿名内部类、lambda表达式、方法引用的底层实现...-程序员宅基地
- android4.4.2link2sd,Android Studio 2.3 特性:生成Android App Links-程序员宅基地
- hive中行转列、列转行的实现_hive 列转行str_to_map-程序员宅基地
- python怎么安装sympy库_python中sympy库求常微分方程的用法-程序员宅基地
- python如果输入错误提醒_如果输入了无效的输入,如何让python程序退出并显示错误消息?...-程序员宅基地
- c语言编程项目实践报告快递管理系统,学生成绩管理系统C语言程序设计实践报告.doc...-程序员宅基地