
”colly“ 的搜索结果

gocolly_learn:关于学习gocolly
Colly是一个使用golang实现的数据抓取框架,我们可以使用它快速搭建类似网络爬虫这样的应用。本文我们将剖析其源码,以探析其中奥秘。(转载请指明出于breaksoftware的csdn博客) Collector是Colly的核心结构体,...
Colly提供了一个干净的界面来编写任何种类的爬虫/爬虫/蜘蛛。 使用Colly,您可以轻松地从网站中提取结构化数据,这些数据可用于各种应用程序,例如数据挖掘,数据处理或归档。 产品特点 清洁API 快速(单个内核上>...
很多语言都可以写爬虫,包括python,java、c++、Pythhon等。而Go本身是开源的,很多大佬为Python的功能扩展写了很多成熟的工具,也就是网络上常说的xx库,我们可以利用这些工具快速实现我们的需求,比较好入门。...
colly爬虫库学习笔记 前言 稍微的学习了一下Go语言的基础知识(错误处理和协程通道这些还没看),想着能不能做点东西,突然想到自己当时学了python之后就是专门为了写爬虫(虽然后来也咕了,只会一个request.get和...
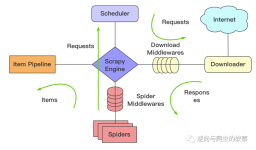
Colly是Gopher的快速和优雅抓取框架



文章目录一、安装二、入门2.1 收集器2.1.1 收集器配置2.2.2 对于递归调用的长任务使用异步存储2.2.3 禁用或限制连接保持活动状态2.2 回调2.2.1 添加回调到收集器中2.2.2 回调函数执行顺序2.3 OnRequest2.4 OnError...
得到每天都百度热搜
文章目录写在前面Go语言爬虫框架之Colly和Goquery网络爬虫爬虫的简单算法Colly开始OnHTMLOnRequest / OnResponseHTMLElementBringing in Goquery写一个完整的爬虫 写在前面 此文翻译自点击阅读原文,建议英语能力好...
爬虫靠演技,表演得越像浏览器,抓取数据越容易,这是我多年爬虫经验的感悟。回顾下个人的爬虫经历,共分三个阶段:第一阶段,09年左右开始接触爬虫,那时由于项目需要,要访问各大国际社交网站,Facebook,myspace...
Colly是Go的爬虫框架,简单快速,适合日常工作获取数据。
写在前面Go语言爬虫框架之Colly和GoqueryPython框架框架比较有BeautifulSoup或Scrapy,基于Go的爬虫框架是比较强健的,尤其Colly和Goquery是比较强大的工具,其灵活性和 表达性都比较优秀。网络爬虫网络爬虫是什么?...
文章目录简介demo 简介 ...cookie登录 ... "github.com/gocolly/colly/extensions" "log" "net/http" "os" "strings" "time" ) /* 请求执行之前调用 - OnRequest 响应返回之后调用 - OnRespon
熟悉了《Golang 网络爬虫框架gocolly/colly 一》和《Golang 网络爬虫框架gocolly/colly 二》之后就可以在网络上爬取大部分数据了。本文接下来将爬取中证指数有限公司提供的行业市盈率。...
文章目录介绍demo 介绍 本章节使用OnResponse进行返回网页数据 使用xpath定位数据; 推荐htmlquery ... "github.com/gocolly/colly/extensions" "gopkg.in/xmlpath.v2" "log" "os" "strings" "time" )
【代码】go的爬虫工具教你如何去翻译(go调用js,colly的使用)
推荐背景日常业务开发中常会遇到一些采集整理互联网数据信息的业务需求,单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高,此时就用爬虫手段来对数据进行自动采集降低完成业务所需的人力成本...
goquery https://blog.csdn.net/yang731227/article/details/89338745 eg1:fcdm爬虫 package main import ( "fmt" ... "github.com/gocolly/colly" "strconv" ... c := colly.NewCollector() content
colly 是 Go 实现的比较有名的一款爬虫框架,而且 Go 在高并发和分布式场景的优势也正是爬虫技术所需要的。它的主要特点是轻量、快速,设计非常优雅,并且分布式的支持也非常简单,易于扩展。 使用 go get -u ...
使用 Colly 实现 豆瓣电影Top250爬取 package main import ( "encoding/csv" "github.com/PuerkitoBio/goquery" "github.com/gocolly/colly" "log" "os" "strings" "time" ) type Movie struct { idx ...
目前在使用colly的时候OnRequest函数并非在h.Do(request, bodySize, checkHeadersFunc)前一步执行因此如果使用Cache功能即使从缓存中读取,任然会先运行OnRequest命令。

推荐文章
- C++零碎知识点(一)-程序员宅基地
- 【Python学习笔记】Coursera课程《Python Data Structures》 密歇根大学 Charles Severance——Week5 Dictionary课堂笔记...-程序员宅基地
- v-html 解析字符串到 html 换行显示_html字符串 v-html-程序员宅基地
- 招收跨专业考计算机的学校,跨专业考研,接受跨专业考研的学校。-程序员宅基地
- 数学模型预测模型_改进著名的nfl预测模型-程序员宅基地
- ELK-FileBeat入门_filebeat 6.5.4 - windows-程序员宅基地
- 微信小程序架构图与开发_微信小程序框架图-程序员宅基地
- Node.js 下载与安装教程_node下载-程序员宅基地
- MySQL报错:The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone_连接失败! the server time zone value ' й ' is-程序员宅基地
- 数学与生活——读书笔记-程序员宅基地