
”bert“ 的搜索结果
BERT
标签: JupyterNotebook
BERT

本课件是对论文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 的导读与NLP领域经典预训练模型 Bert 的详解,通过介绍NLP领域对通用语言模型的需求,引入 Bert 模型,并对其...
探索BERT在文档二分类中的应用:bert_doc_binary_classification 项目地址:https://gitcode.com/percent4/bert_doc_binary_classification 本文将带你深入了解一个基于BERT的Python项目——bert_doc_binary_...
可能是版本的升级pretrained_config_archive_map这个字段做了修改,以Bert为例,这个字段改为了‘BERT_PRETRAINED_CONFIG_ARCHIVE_MAP’。per_gpu_train_batch_size和per_gpu_eval_batch_size:batch_size大小,根据...
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练模型,它是自然语言处理(NLP)领域的重大里程碑,被认为是当前的State-of-the-Art模型之一。BERT的设计理念和结构基于Transformer...
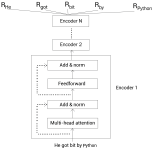
在篇我们将详细学习如何使用预训练的BERT模型。首先,我们将了解谷歌对外公开的预训练的BERT模型的不同配置。然后,我们将学习如何使用预训练的BERT模型作为特征提取器。此外,我们还将探究Hugging Face的...
HottoSNS-Bert:利用预训练模型进行社交网络文本挖掘 项目地址:https://gitcode.com/hottolink/hottoSNS-bert HottoSNS-Bert 是一个基于BERT预训练模型的开源项目,旨在帮助开发者和研究人员高效地处理和分析社交...
所谓预训练模型,举个例子,假设我们有大量的维基百科数据,那么我们可以用这部分巨大的数据来训练一个泛化能力很强的模型,当我们需要在特定场景使用时,例如做医学命名实体识别,那么,只需要简单的修改一些输出层...

在pytorch上实现了bert模型,并且实现了预训练参数加载功能,可以加载huggingface上的预训练模型参数。 主要包含以下内容: 1) 实现BertEmbeddings、Transformer、BerPooler等Bert模型所需子模块代码。 2) 在子模块...
1、内容概要:本资源主要基于bert(keras)实现文本分类,适用于初学者学习文本分类使用。 2、数据集为电商真实商品评论数据,主要包括训练集data_train,测试集data_test ,经过预处理的训练集clean_data_train和...
探索前沿自然语言处理:TFBERT - TensorFlow实现的BERT模型 项目地址:https://gitcode.com/huanghuidmml/tfbert 在自然语言处理领域,BERT(Bidirectional Encoder Representations from Transformers)是近年来的一...
探秘BERT_SMP2020-EWECT:预训练模型的新突破 项目地址:https://gitcode.com/BrownSweater/BERT_SMP2020-EWECT 本文将向您介绍BERT_SMP2020-EWECT,这是一个针对中文语言理解任务优化的预训练模型。该项目由...
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。BERT可以在大规模的未标注文本上进行预训练,然后在各种下游NLP任务上进行...
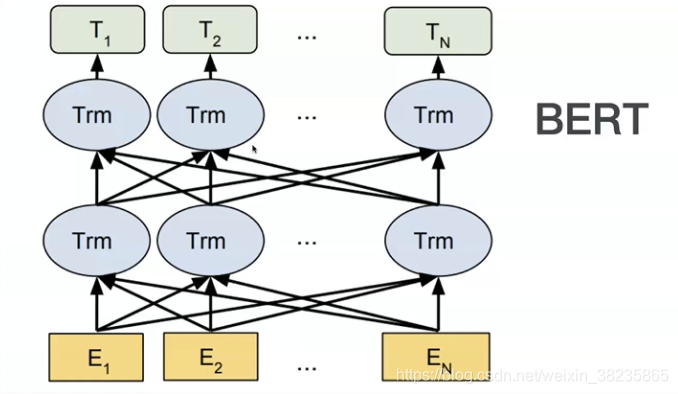
Fast-Bert是一个深度学习库,允许开发人员和数据科学家针对基于文本分类的自然语言处理任务训练和部署基于BERT和XLNet的模型。 FastBert的工作建立在优秀的提供的坚实基础上,并受到启发,并致力于为广大的机器...
BERT-pytorch
标签: Python
伯特·比托奇 Google AI的2018 BERT的Pytorch实现,带有简单注释BERT 2018 BERT:用于语言理解的深度双向变压器的预培训论文URL: : 介绍Google AI的BERT论文显示了在各种NLP任务(新的17个NLP任务SOTA)上的惊人...
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。BERT的创新之处在于采用了双向(bidirectional)的预训练方法,相较于传统的...
Bert语言模型基本介绍
记录一下,后续补充完善
BERT的对抗性嵌入 上基于BERT的情感分类对抗嵌入生成与分析。 建立在对Google Research之上。 IMDB加载器和处理器功能取自。 存储库还包括一种算法,用于投影对抗性嵌入内容以获得对抗性离散文本候选对象。 尽管该...
利用bert预训练的中文语言模型进行文本分类 训练脚本 train.sh 批量测试脚本 predict.sh 利用模型进行单条语句测试 intent.py 注:修改single_predict.py中 get_test_examples,get_labels方法 max_seq_length,需...
(ps:BERT本身并没有一个绝对的精度,因为它是一个预训练的模型,其性能取决于具体任务和数据集,但是一些标准的基准数据集上,BERT和其变种通常能够达到非常高的精度。例如,在GLUE上)----------->均使用单项的语言...
在"fine_tuned_bert_model"目录中包含了微调后的BERT模型的相关文件,这些文件通常是Hugging Face Transformers库默认的模型保存结构,其中包括了模型的权重、配置信息、词汇表等。在上述代码中,'bert-base-uncased...
使用说明保存预训练模型在数据文件夹下├──数据│├──bert_config.json │├──config.json │├──pytorch_model.bin │└──vocab.txt ├──bert_corrector.py ├──config.py ├──logger.py ├──...
Bert
我们已经证明,除了BERT-Base和BERT-Large之外,标准BERT配方(包括模型体系结构和训练目标)对多种模型尺寸均有效。 较小的BERT模型适用于计算资源有限的环境。 可以按照与原始BERT模型相同的方式对它们进行微调。...
推荐文章
- vuex中state对象会数组中的值更新后getters没有监听到state数据的改变的问题state数据跟新页面不刷新问题_vue对象数组改变元素没有getter-程序员宅基地
- 《Centos7——手动部署prometheus》_prometheus centos7-程序员宅基地
- iOS 数据保存几种方式总结_苹果ld都会保留那些数据-程序员宅基地
- quartus生成qdb文件_quartus 生成qxp和vqm文件的方法-程序员宅基地
- Servlet学习笔记3,及回忆。_attributeadded(servletrequestattributeevent ev)方法的-程序员宅基地
- cv::putText详解-程序员宅基地
- tomcat优化_tomcat ajp端口干嘛用的 关闭会怎么样-程序员宅基地
- (UVA)11916 Emoogle Grid-程序员宅基地
- 指针_定义一个指针变量他的值是多少-程序员宅基地
- 《Java基础——异常的捕获与抛出》_java捕获异常和抛出异常-程序员宅基地