”Self-Attention“ 的搜索结果
1 Self-Attention的概念2 Self-Attention的原理3 Self-Attention的作用4 Self-Attention的问题。
自关注与文本分类 本仓库基于自关注机制实现文本分类。...$ python imdb_attention.py 比较结果 算法 训练时间(每纪元) Val准确率 Val损失 所需Epoch数 LSTM 116秒 0.8339 0.3815 2 双向LSTM

自注意力机制(Self-Attention),有时也称为内部注意力机制,是一种在深度学习模型中应用的机制,尤其在处理序列数据时显得非常有效。它允许输入序列的每个元素都与序列中的其他元素进行比较,以计算序列的表示。...

通过pip安装$ pip install self-attention-cv 如果您没有GPU,最好在您的环境中预安装pytorch。相关文章程式码范例多头注意力import torchfrom self_attention_cv import MultiHeadSelfAttentionmodel = ...
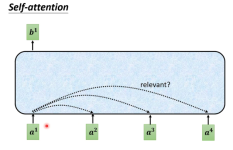
1.由来 在Transformer之前,做翻译的时候,一般用基于RNN的...输入的x1,x2x_{1},x_{2}x1,x2,共同经过Self-attention机制后,在Self-attention中实现了信息的交互,分别得到了z1,z2z_{1},z_{2}z1,z2,将z1,z2
A Supervised Multi-Head Self-Attention Network for Nested NE.pdf
以下代码创建了一个注意力层,它遵循第一部分中的方程( attention_activation是e_{t, t'}的激活函数): import kerasfrom keras_self_attention import SeqSelfAttentionmodel = keras . models . Sequential ()...
Stand-Alone_Self-Attention_in_Vision_Models 创建的资料库旨在审查德累斯顿大学计算机视觉研讨会的科学文章

从三大顶会论文看百变Self-Attention,i.e.,了解并熟悉self-attention的相关思想以及最新的研究进展。另外,一并附上一个self-attention论文集仓库(https://github.com/PengboLiu/NLP-Papers)
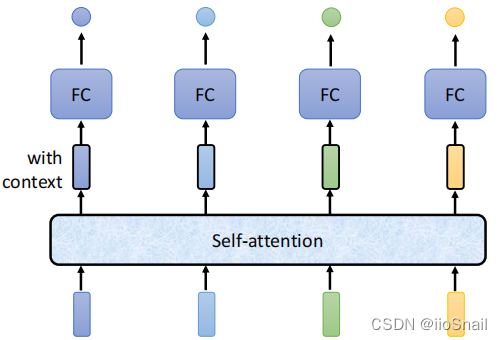
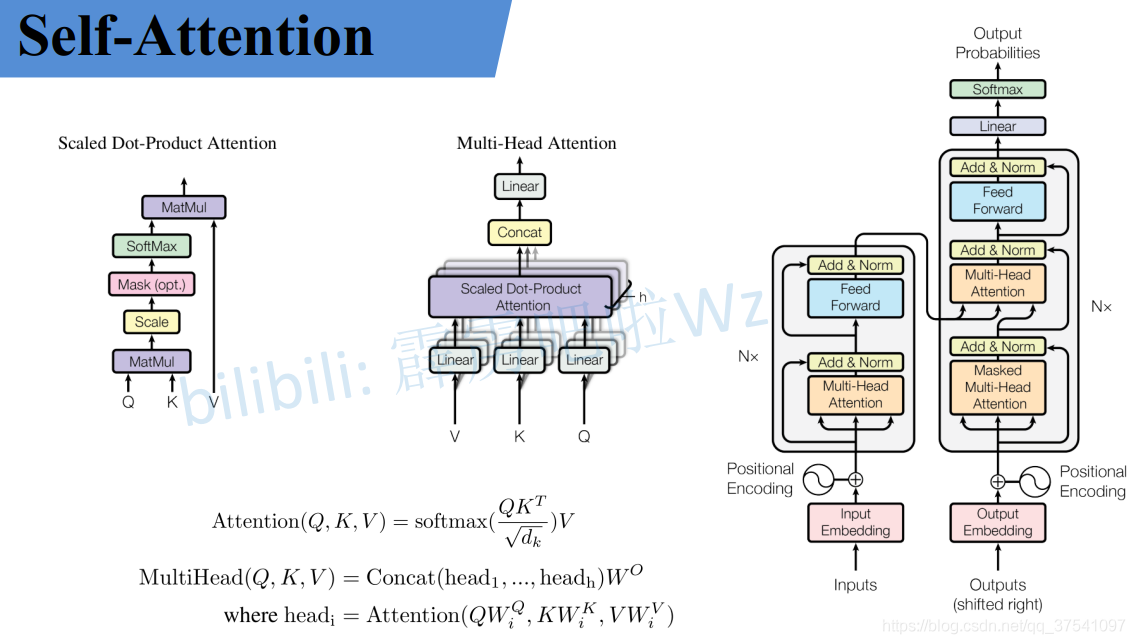
Self-Attention&Multi-head-Attention原理和代码实现


全球自我关注网络 ,该提出了一种全关注的视觉主干,该主干比具有较少参数和计算的卷积可以获得更好的结果。 他们使用先前发现的,进行了少量修改以获取更多收益(对查询不进行标准化),并与相对位置注意相对,并...



使用自我注意和离散视差量的自我监督单眼训练深度估计-ML重现性挑战2020 该项目是CVPR 2020论文的复制品 使用自我注意和离散视差量的自我监督单眼训练深度估计 阿德里安·约翰斯顿,古斯塔沃·卡内罗 ...
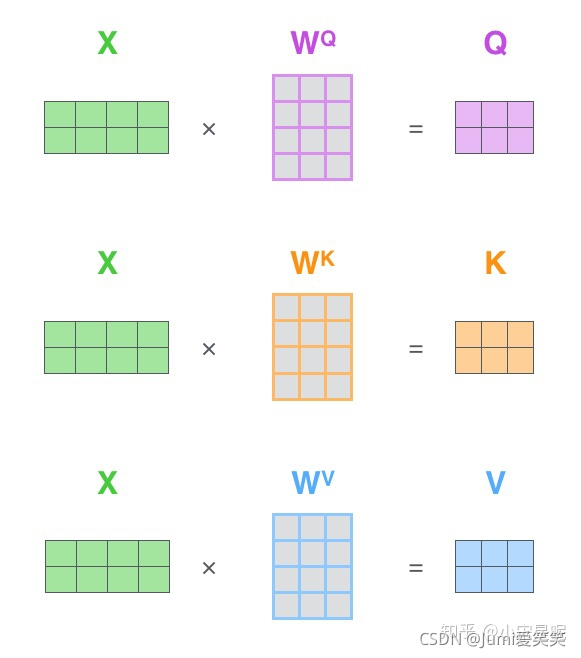
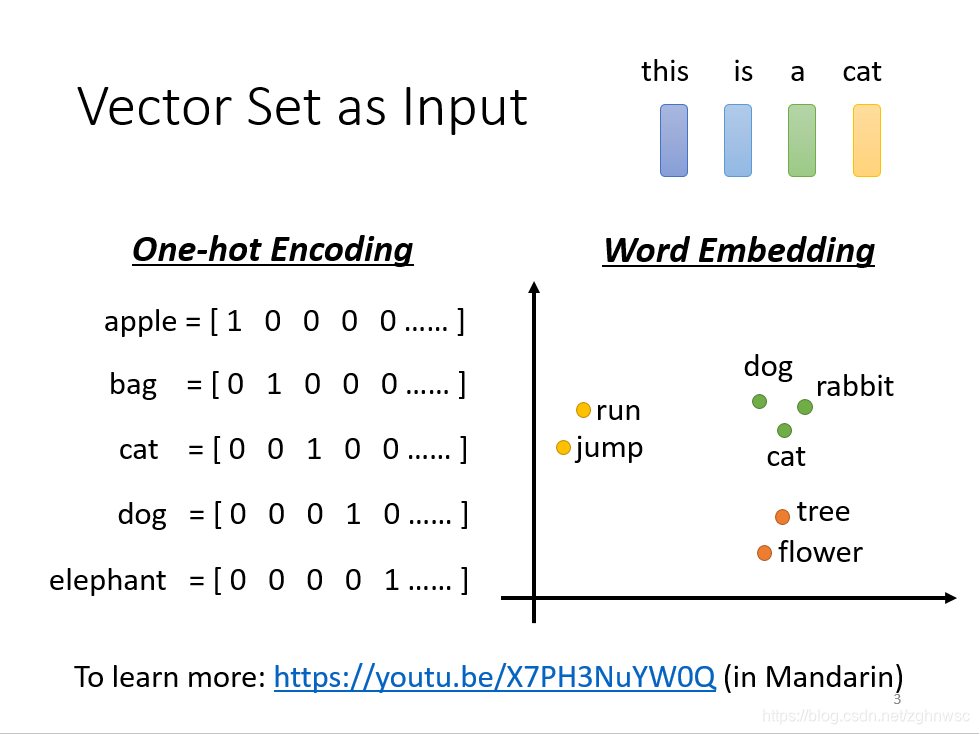
为什么是512*512?人们常说,Transformer不能超过512,否则硬件很难支撑;从输入输出角度,N个Transformer Encoder block中的第一个Encoder block的输入为一组向量 X = (Embedding + Positional Embedding),向量...



推荐文章
- 大数据技术未来发展前景及趋势分析_大数据技术的发展方向-程序员宅基地
- Abaqus学习-初识Abaqus(悬臂梁)_abaqus悬臂梁-程序员宅基地
- 数据预处理--数据格式csv、arff等之间的转换_csv转arff文件-程序员宅基地
- c语言发送网络请求,如何使用C+发出HTTP请求?-程序员宅基地
- ccc计算机比赛如何报名,整理:加拿大的CCC是什么,怎么报名?-程序员宅基地
- RK3568 学习笔记 : ubuntu 20.04 下 Linux-SDK 镜像烧写_rk3568刷linux-程序员宅基地
- Gradle是什么_gradle是干嘛的-程序员宅基地
- adb命令集锦-程序员宅基地
- 【Java基础学习打卡15】分隔符、标识符与关键字_java分隔符有哪三种-程序员宅基地
- Python批量改变图片名字_python批量修改图片名称-程序员宅基地