在这个教材中,我们假定你已经安装了Scrapy。假如你没有安装,你可以参考这个安装指南。 我们将会用开放目录项目(dmoz)作为我们例子去抓取。 这个教材将会带你走过下面这几个方面: 创造一个新的Scrapy项目 定义您将...
”Scrapy框架爬虫“ 的搜索结果


Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
按照我的理解,数据分析大概整体分为5大模块——数据收集、...利用Python可以十分简单的制作一个爬虫(随便一搜,代码就哗哗嘀),因此我在这里就不赘述如何去写一个简单的爬虫了。这篇文章我将倾向于如何分别利用requ
解决url参数过长问题,长度超过设置值时,此URL将被略过而不执行。 解决方案: 在Settings文件中,增加以下参数: URLLENGTH_LIMIT = 5000 以下是官方的说明,可以参考一下: ...The maximum URL le...
Scrapy是一个基于Python的开源网络爬虫框架,用于从网页中提取...通过Scrapy框架实现一个爬虫,只需要少量的代码,就能够快速的网络抓取Scrapy基于Twisted,Twisted是一个异步网络框架,主要用于提高爬虫的下载速度。
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
为您提供ScrapyWeb爬虫框架下载,Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
1、环境准备 ...3、使用scrapy genspider dangdang dangdang.com创建spider爬虫实例 2、代码实操 dangdang.py文件内容 import urllib.parse from copy import deepcopy import scrapy class DangdangS

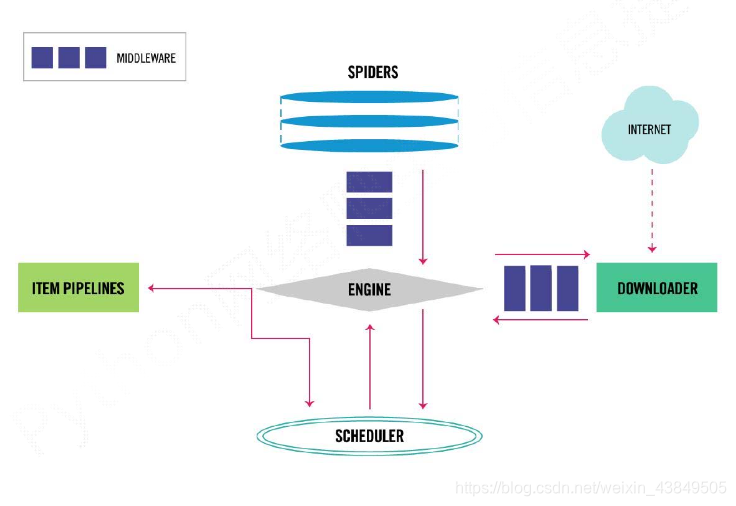
下载中间件是一个钩子到Scrapy的请求/响应处理的框架。这是一个轻量级的、低级的系统,用于全局改变Scrapy的请求和响应。 激活下载器中间件 在settings.py配置,这是一个dict,键是中间件类路径,值是中间件顺序。 ...
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、...
使用了python非常火的Scrapy框架写的爬虫项目,采用Scrapy自带的异步下载,实现对表情包网站的表情秒下载,相比于我上一个发布的表情包爬虫资源,整整快了100倍
在使用scrapy爬虫的时候,我们常常使用xpath来获取html标签,但是我们经常会用到提取的方法,有两种提取的方法,分别是: extract():这个方法返回的是一个数组list,,里面包含了多个string,如果只有一个string,...

学过爬虫的朋友知道,requests库和BeautifulSoup4库可以爬取80%多的数据,但是还有少部分数据通过这两个库无法获取,所以今天介绍另外一个爬虫工具——Scrapy框架。 1.Scrapy框架介绍 Scrapy是用python实现的一个...
爬取数据时,单个数据使用requests或urllib将数据爬取,但是多个url会导致麻烦,使用Scrapy框架一次性爬取多个页面 使用scrapy startproject [项目名称] 在使用命令创建完成之后进入项目文件夹,创建爬虫 scrapy ...
scrapy 是 python 写的爬虫框架,代码架构借鉴于django,灵活多样,功能强大。
Scrapy Web爬虫框架 v1.8.4.zip
scrapy是python 爬虫框架中性能较好的,用户可以自己定义相关组件。这本书是入门书籍

本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
可以用于毕业设计(项目源码+项目说明)目前在window10/11测试环境一切正常,用于演示的图片和部署教程说明都在压缩包里
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
推荐文章
- C++语法基础--标准库类型--bitset-程序员宅基地
- [C++] 第三方线程池库BS::thread_pool介绍和使用-程序员宅基地
- 如何使用openssl dgst生成哈希、签名、验签-程序员宅基地
- ios---剪裁圆形图片方法_ios软件圆形剪裁-程序员宅基地
- No module named 'matplotlib.finance'及name 'candlestick_ochl' is not defined强力解决办法-程序员宅基地
- 基于java快递代取计算机毕业设计源码+系统+lw文档+mysql数据库+调试部署_快递企业涉及到的计算机语言-程序员宅基地
- RedisTemplate与zset redis_redistemplate zset-程序员宅基地
- 服务器虚拟化培训计划,vmware虚拟机使用培训(一)概要.ppt-程序员宅基地
- application/x-www-form-urlencoded方式对post请求传参-程序员宅基地
- 网络安全常见十大漏洞总结(原理、危害、防御)-程序员宅基地