本文将详细分析Scrapy多线程导致抓取错乱的原因,并提出相应的解决方案,帮助读者更好地应对实际问题。本文针对Scrapy爬虫多线程导致抓取错乱的问题进行了深入分析,并提出了相应的解决方案。通过严格控制并发数、...
”Scrapy多线程爬取“ 的搜索结果
Scrapy是一个用Python编写的开源网络爬虫框架。
它具有强大的抓取能力,支持多线程和分布式爬虫,能够并行爬取多个网页。Scrapy提供了方便的API和丰富的功能,可以自定义爬虫规则和处理流程,支持数据的持久化存储和导出。它还提供了可视化的调试工具和强大的反...
首先,通过使用多线程和多进程来提高程序的并发性能;然后,演示了如何使用Scrapy框架实现分布式爬虫,将爬取任务分发到多个节点上以提高效率;最后,介绍了如何进行并发控制和限制请求频率,包括Scrapy内置的功能...
python scrapy 多线程

主要介绍了Python实现多线程抓取网页功能,结合具体实例形式详细分析了Python多线程编程的相关操作技巧与注意事项,并附带demo实例给出了多线程抓取网页的实现方法,需要的朋友可以参考下
一:多线程爬虫原理 二:Scrapy框架 定义:Scrapy是基于Python实现,方便爬取网站数据、提取结构性数据的应用框架。 底层:使用Twisted异步网络框架来处理网络通讯,加快下载速度。 不用手动实现异步框架,包含了...
Scrapy支持多线程爬取,可以使用Python的threading模块和Queue模块实现。以下是一个简单的示例,展示如何在Scrapy中使用多线程爬取: ```python import threading from queue import Queue import scrapy from ...

网络爬虫-学习记录(五)利用scrapy实现多进程爬取
Scrapy实战-爬取网页英语书籍 一、下载Scrapy(若没有下载可以点击下面的链接按步骤下载),之前若下载过可以跳过此步。 博主文章官方链接:在 windows系统中安装 Scrapy详细过程 二、按照先后顺序复制下面的代码,...
【小宅按】对于日常Python爬虫由于效率问题,本次测试使用多线程和Scrapy框架来实现抓取斗图啦表情。由于IO操作不使用CPU,对于IO密集(磁盘IO/网络IO/人机交互IO)型适合用多线程,对于计算密集型:建议用多进程。...
问题的由来我们的需求为爬取红色框框内的名人(有500条记录,图片只展示了一部分)的 名字以及其介绍,关于其介绍,点击该名人的名字即可,如下图:这就意味着我们需要爬取500个这样的页面,即500个HTTP请求(暂且...
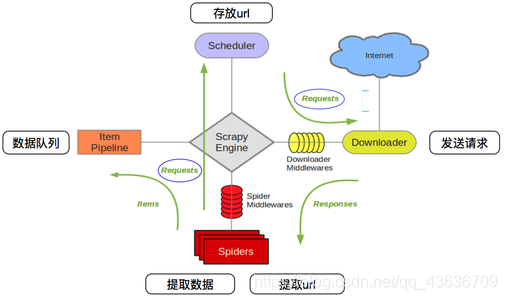
Scrapy框架 是什么 用处 实现方法
Scrapy入门:爬取古诗文
标签: python
从入门到放弃,,,太难了吧

1.scrapy教程资料 2scrapy安装配置 3.介绍scrapy框架 1.scrapy教程资料 官方文档 中文版:http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html 英文版:...

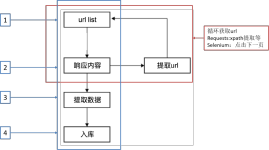
本部分所实现的功能是,批量的爬取网页信息,不再是像以前那样只能下载一个页面了。也就是说,分析出网页的url规律后,用特定的算法去迭代,达到把整个网站的有效信息都拿下的目的。 因为本部分讲完后,功能已经...
scrapy基本结构、爬取流程、定义随机请求头、抓取异步网页请参考:scrapy框架–基础结构加爬取异步加载数据的网址项目完整实例 items.py class BooksItem(scrapy.Item): # define the fields for your item here ...
做了一个关于爬取中国最好大学网http://www.zuihaodaxue.com/rankings.html的项目用的这个Scrapy框架,多线程还挺好用,爬取结束后用Pyecharts作图。写的代码可能有点粗糙,只是抒发拙见,还请各位大佬勿怪。
import requests as reqs import threading import time #Some User Agents hds={'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6', ...
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架。 用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片。 (提高请求效率) Scrapy 使用了Twisted...
点击上方“Python爬虫与数据挖掘”,进行关注回复“书籍”即可获赠Python从入门到进阶共10本电子书今日鸡汤潮平两岸阔,风正一帆悬。大家好,我是杯酒先生,这是我第一次写这种分...


推荐文章
- maven 如何查看jar在哪个pom引入_maven查看jar包从哪个pom引入-程序员宅基地
- handsontable合并项mergeCells应用及扩展-程序员宅基地
- Object.requireNonNull_objects.requirenonnull-程序员宅基地
- python提取pdf中图片和文本_python原生代码,提取pdf图片中的文字-程序员宅基地
- 计算机二级office考试题库操作题,计算机二级考试MSOffice考试题库ppt操作题附答案...-程序员宅基地
- unity 启动相机_Unity3D研究院之打开照相机与本地相册进行裁剪显示(三十三)...-程序员宅基地
- oracle sql 分区查询语句_oracle表空间表分区详解及oracle表分区查询使用方法-程序员宅基地
- 国培 计算机远程培训心得,信息技术国培学习心得体会(2)-程序员宅基地
- oracle博客管理系统,读赵杰夫博客之ORACLE EBS 系统主数据管理(A)摘录-程序员宅基地
- java实现会员注册_java wed【上机作业】会员注册,利用request对象。(1)首先判断密码长度要在5~1-程序员宅基地